去年底上線前的一次系統轉換演練,碰到某支轉檔SQL執行變慢,表象是執行計畫改變(plan change),進一步找原因則發現是不太即時的統計值造成Query Optimizer產生較差的執行計畫。
SQL版本: SQL 2014/2017 Enterprise
統計值系列之二: 不新鮮
為了接續接下來的幾篇筆記,我們開一個新資料庫StatisticsDb來作實驗。
建立環境
CREATE DATABASE StatisticsDb
USE [master]
GO
ALTER DATABASE [StatisticsDb] SET COMPATIBILITY_LEVEL = 100
GO
--查詢資料庫統計值有關的屬性(預設)
SELECT is_auto_create_stats_on
,is_auto_create_stats_incremental_on
,is_auto_update_stats_on
,is_auto_update_stats_async_on
FROM sys.databases WHERE name = 'StatisticsDb';

除了索引上的統計值外,資料庫預設是自動建立、自動更新索引及欄位的統計值。
建立查詢統計值的預存程序
CREATE PROCEDURE usp_showStatistics
@TableName varchar(50)
AS
BEGIN
SELECT
s.name AS 'Statistics'
,so.name AS TableName
,COL_NAME(scol.object_id, scol.column_id) AS 'Column'
,s.auto_created
,s.user_created
,sp.last_updated
,sp.rows AS RowsInTableWhenUpdated
,sp.rows_sampled
,sp.modification_counter
FROM sys.stats s (NOLOCK)
JOIN sys.objects so
ON s.object_id = so.object_id
JOIN sys.stats_columns AS scol (NOLOCK)
ON s.stats_id = scol.stats_id
AND s.object_id = scol.object_id
JOIN sys.tables AS tab (NOLOCK)
ON tab.object_id = s.object_id
CROSS APPLY [sys].[dm_db_stats_properties](so.object_id, s.stats_id) [sp]
WHERE
so.name = @TableName
--s.name like '_WA%'
--and stats_column_id = 1
ORDER BY so.name, s.name
END
建立西班牙皇家馬德里的球員名單資料表來測試
USE StatisticsDb
IF OBJECT_ID('RealMadridClub') IS NOT NULL
DROP TABLE RealMadridClub;
--建立資料表
CREATE TABLE RealMadridClub
(
PLAYER_ID INT IDENTITY,
NAME VARCHAR(50),
JERSEY_NO INT,
COUNTRY VARCHAR(50),
CONSTRAINT [PK_RealMadridClub] PRIMARY KEY CLUSTERED
(
PLAYER_ID ASC
)
)
--建立範例資料
INSERT INTO RealMadridClub VALUES
('Isco',22,'西班牙')
,('Benzema',9,'法國')
,('Toni Kroos',8,'德國')
,('Cristiano Ronaldo',7,'葡萄牙')
,('Gareth Bale',11,'英國')
新增5筆資料後,我們來觀察統計值,只出現了叢集索引的統計值。
但,裡面是空的統計資訊

執行剛剛串好的預存程序
EXEC usp_showStatistics 'RealMadridClub'
也是相同的結果,統計值還沒開張。另外也沒有自動建立的欄位統計值

何時出現自動建立的統計值
試試看,使用非索引欄位的NAME來查詢資料
SELECT * FROM RealMadridClub
WHERE NAME = 'Isco'
執行剛剛串好的預存程序
EXEC usp_showStatistics 'RealMadridClub'
多了姓名NAME欄位的統計值

如果查詢的條件欄位沒有統計值,Query Optimizer會在編譯前作統計值建立或有門檻條件性的更新。
建立索引時會不會直接產生統計值?
來試試新增索引
CREATE INDEX IX_RealMadridClub ON RealMadridClub(NAME)
執行剛剛串好的預存程序,果然多了索引的統計值,資訊也馬上更新。

會!
來試試新增大量資料
INSERT INTO RealMadridClub
SELECT NAME,JERSEY_NO,COUNTRY FROM RealMadridClub
GO 15
已經新增了很大量的資料,統計值也記錄了異動數,但統計值尚未更新

從第一個案例,我們可以知道,應該會發生在使用統計值時才更新,來執行查詢。
SET STATISTICS TIME ON
SELECT * FROM RealMadridClub
WHERE NAME = 'isco'
執行預存程序usp_showStatistics觀察,與姓名有關的兩個統計值都更新了

第一次使用統計值時,會發現統計值過舊(outdated),query compilation 會等待統計值更新完畢後再往下執行資料擷取(SQL剖析與編譯時間增加)。
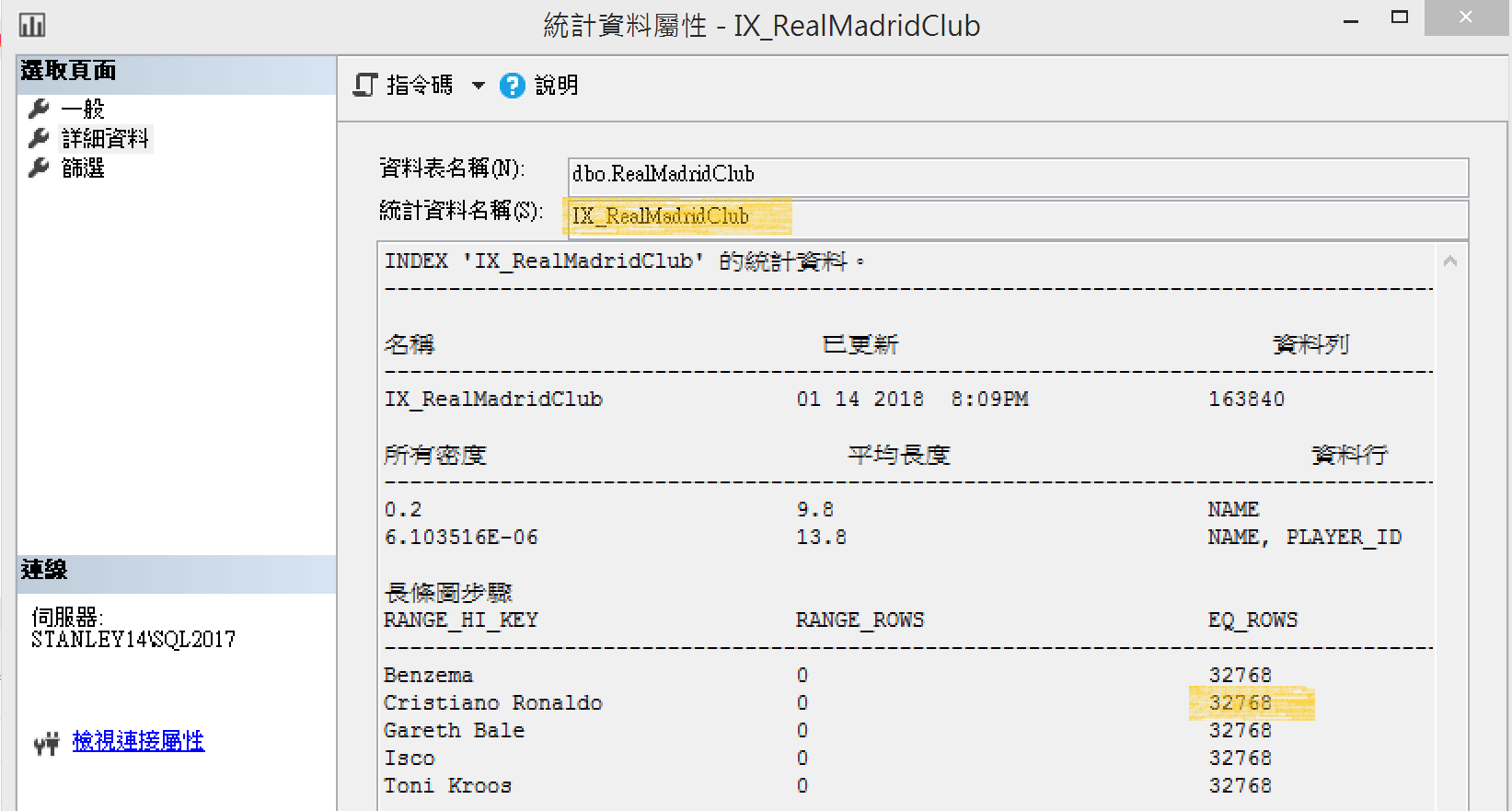
長條圖資訊的統計,每個球員都是32,768筆資料
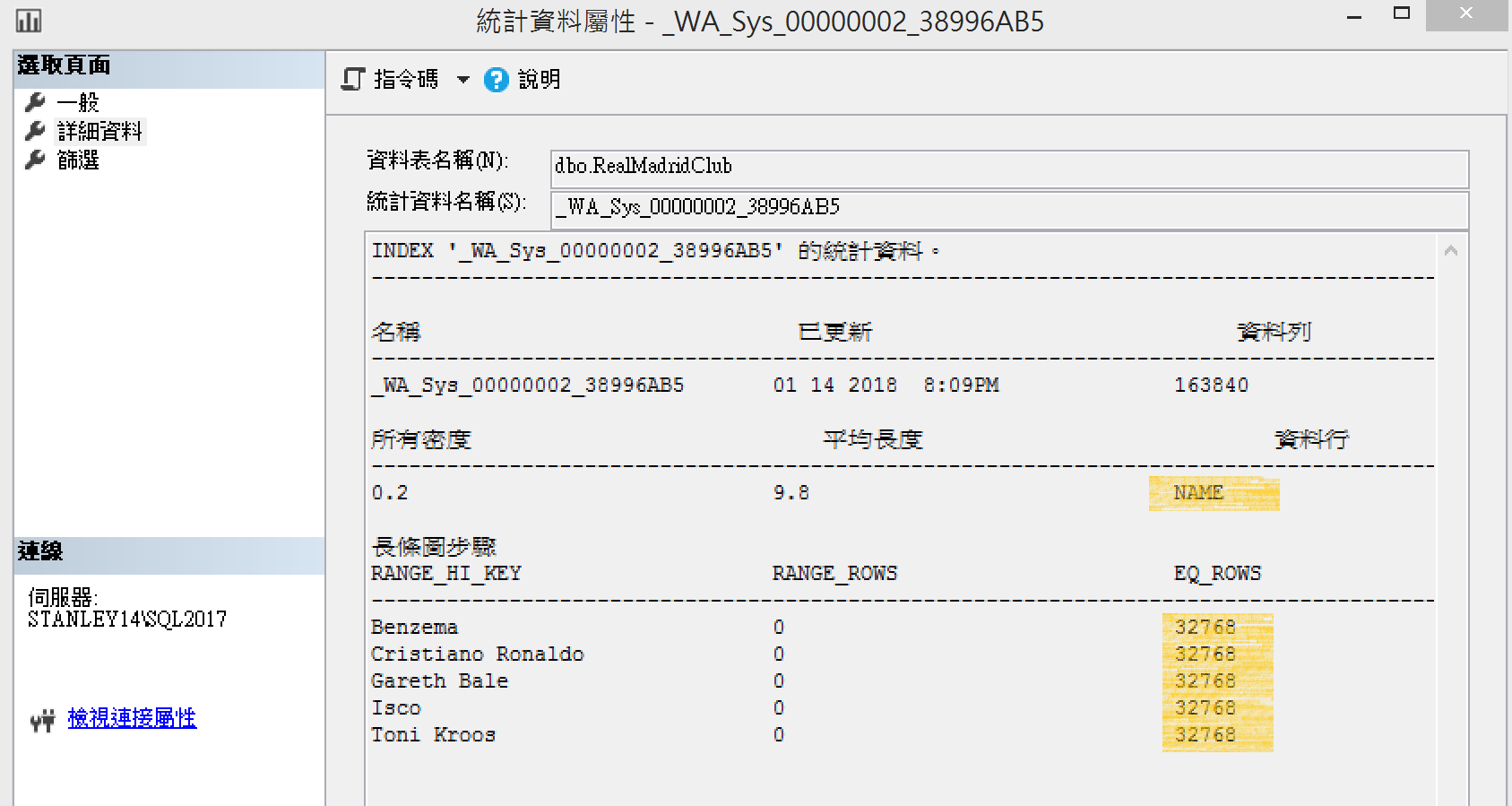
統計值不新鮮造成的問題
C羅只有1個,所以來刪除其他32,767個假C羅
DELETE TOP(32767)RealMadridClub
WHERE NAME = 'Cristiano Ronaldo'
執行預存程序usp_showStatistics觀察,情報中心都有記載異動總量

但實際欄位統計值(_WA_sys..)下的長條圖沒有記載這次大量的刪除
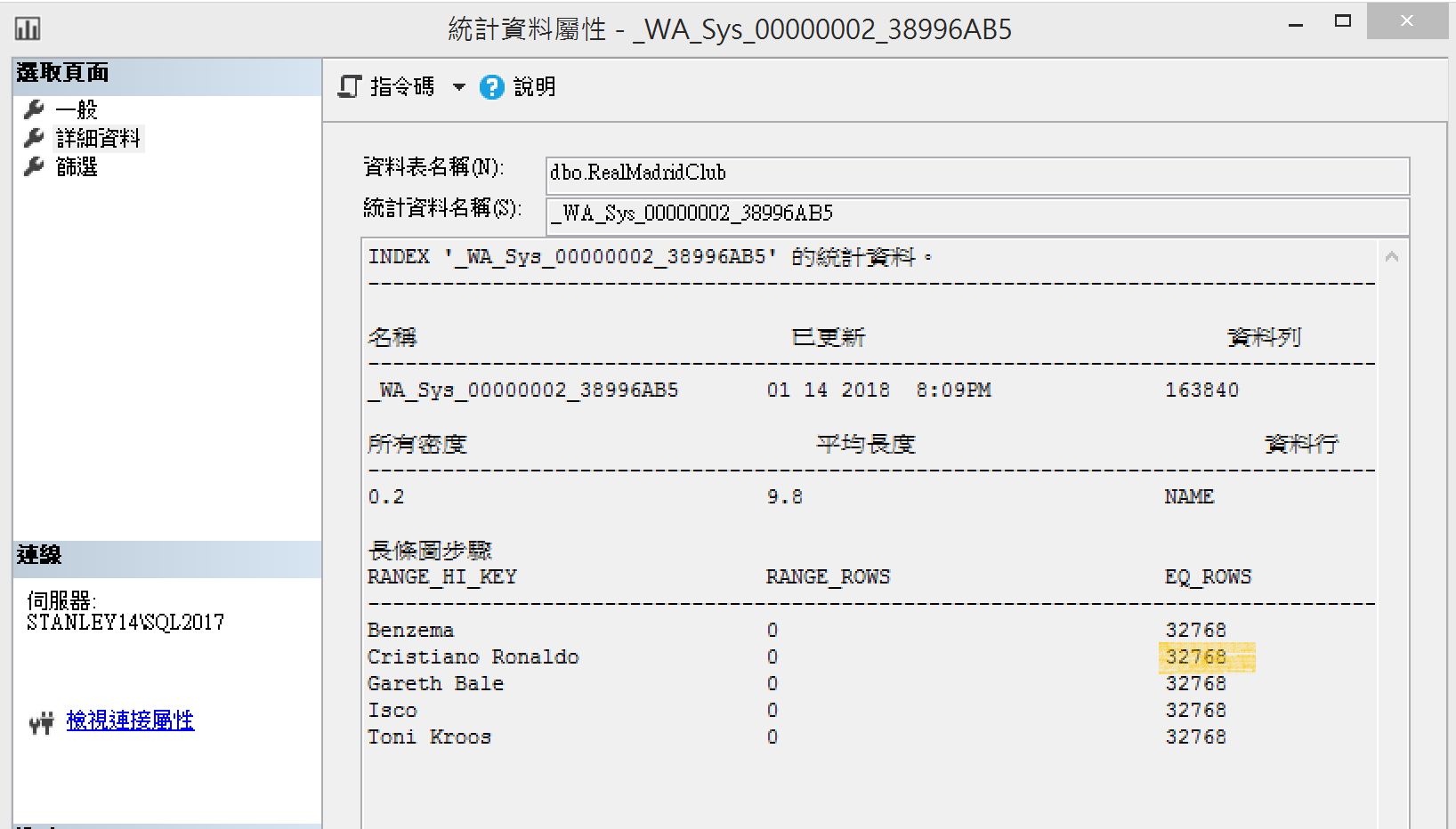
以姓名為索引的IX_RealMadridClub也是
這時如果查詢C羅,因為只有1筆,我們期待是一個以索引搜尋方式的優秀執行計畫!
查詢刻意不用參數條件,避免參數探測問題
SELECT * FROM RealMadridClub
WHERE NAME = 'Cristiano Ronaldo'
但結果卻是走叢集索引掃描?
預估26,214筆,實際只有1筆,準確率非常低。
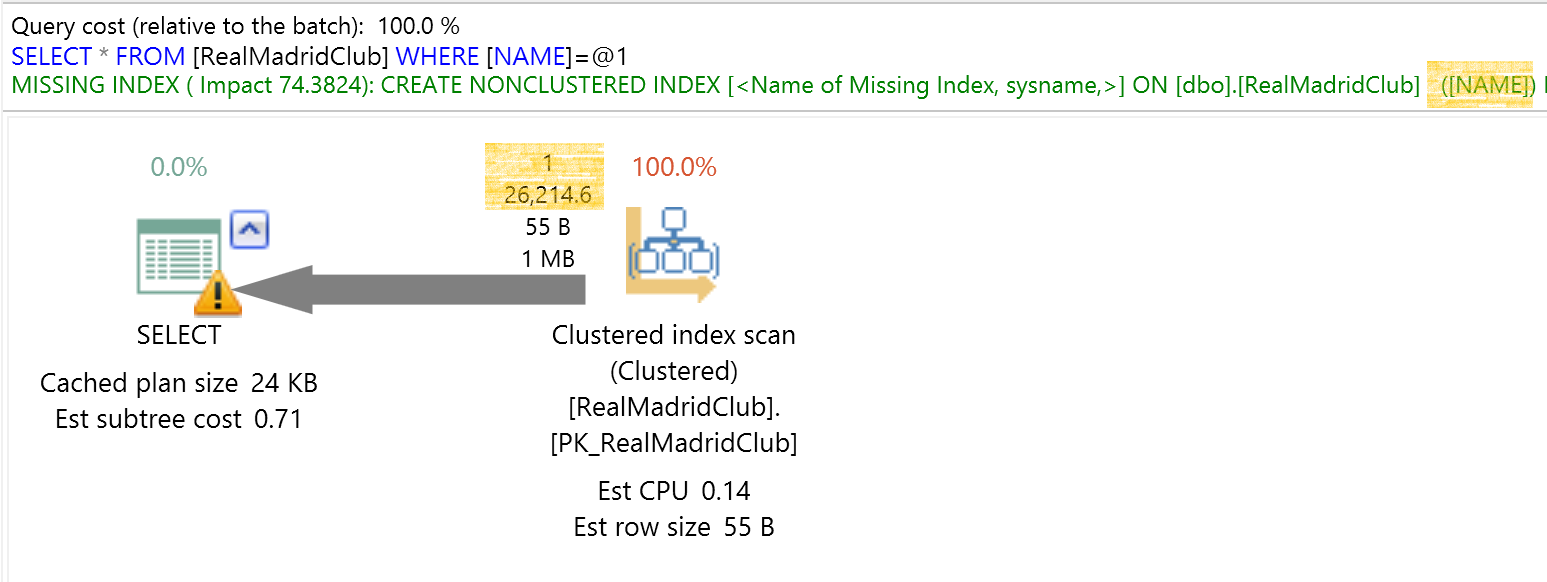
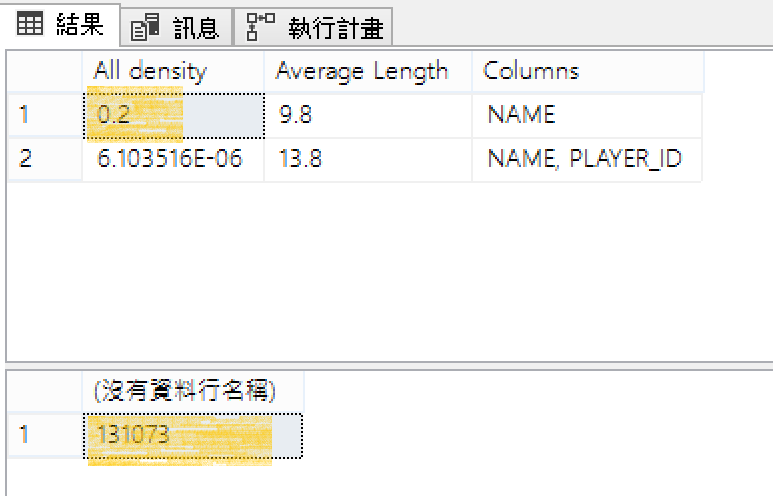
*26,214是根據目前資料表最新資料列筆數 * 密度 20% = 131073 * 0.2 = 26,214.6(無條件捨去小數位)
DBCC SHOW_STATISTICS('RealMadridClub','IX_RealMadridClub') WITH DENSITY_VECTOR
SELECT COUNT(*) FROM RealMadridClub
查詢結果:
臨時解決辦法
手動更新統計值
UPDATE STATISTICS RealMadridClub
執行預存程序usp_showStatistics觀察,統計值都更新了

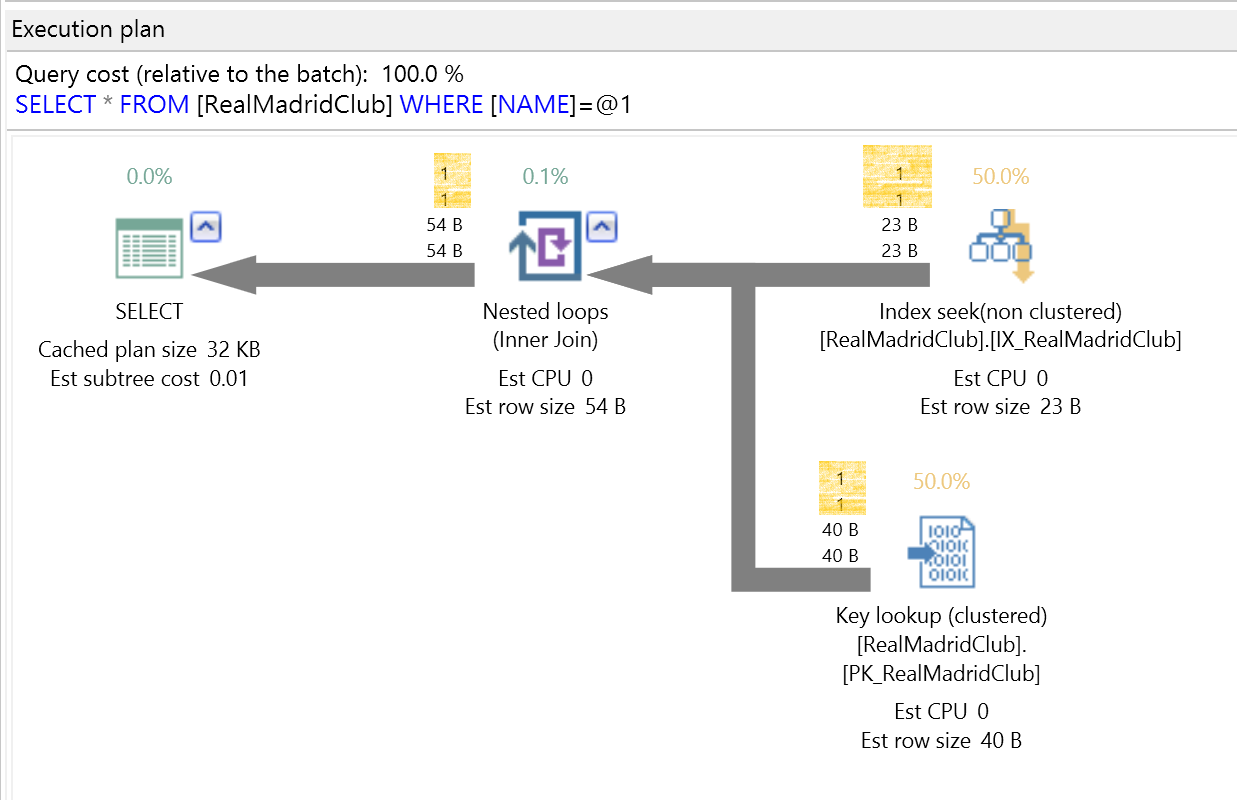
重新查C羅的資料
SELECT * FROM RealMadridClub
WHERE NAME = 'Cristiano Ronaldo'
走優秀的執行計畫了! 小資料找大資料,走搜尋。
小結
- 統計值的更新並不是在Delete/Update/Insert/Merge交易後馬上執行,而是更新後第一次使用統計值。
- 碰過DBA大人設定非同步選項,查詢先行,使用舊的統計值後再更新。
- DBA大人好像都會以排程方式更新統計值。
- 大型資料表統計時,會出現抽樣統計的情形,抽樣不足與過時的統計都可能造成問題。
- 也不是有異動資料表就更新統計值,我們下一篇來實驗SQL2014以前(含),觸發更新統計值的門檻值RT(recompilation threshold)。
Morata 8,000萬歐轉隊
參考
Docs UPDATE STATISTICS (Transact-SQL)
Docs system view-sys.stats_columns
Docs system-stored-procedures sp_statistics