Dot com 電子商務在西元2000年時達到的巔峰,資料採礦(Data Mining)更是打蛇隨棍上,藉由這股熱錢在產業中快速地掘起。微軟也是由 SQL Server 2000 開始支援資料採礦的功能,並且在 SQL Server 2005 增加了更多的演算法。基礎於微軟定位自己是一個平台供應商,在自己不是演算法的供應商的情況下,主導這個市場的能力有限。所幸在2015年買下了 Revolution Analytics,終於解鎖了這個限制,讓企業的想像力可以盡情的奔馳…
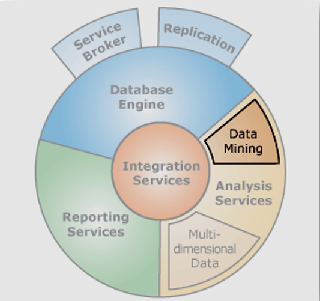
台灣是世界上便利商店最密集的國家之一,促銷的手法也是千變萬化,例如經典的集點送公仔,也是基礎於資料採礦讓業績有飛躍性的成長。本篇將會介紹 SQL Server有哪些演算法?以及相關的應用情境…
就像是我們在Azure Machine Learning 在銀行業的行銷應用篇幅聊到的 AlphaGo,他有網路分散式版本、單機本。這很重要喔!跟大陸的圍棋世界冠軍比賽,若是沒有單機版的解決方案,在中國網路長城的封索限制下,AlphaGo將有如廢鐵一般…
機器學習發展至今解決方案有雲有地非常多元,若想參考微軟在機器學習的全方面佈局可以看這一篇。本篇是先回顧 Sql Server 2014版本未加入拼購 R之前的資料採礦(但其實後續的版本,在 Data mining也有沒有新的進展),以利後續再介紹 R與Python的機器學習。
以下本篇將分別以三個章節,向各位介紹資料採礦解決方案:
- 資料採礦的情境
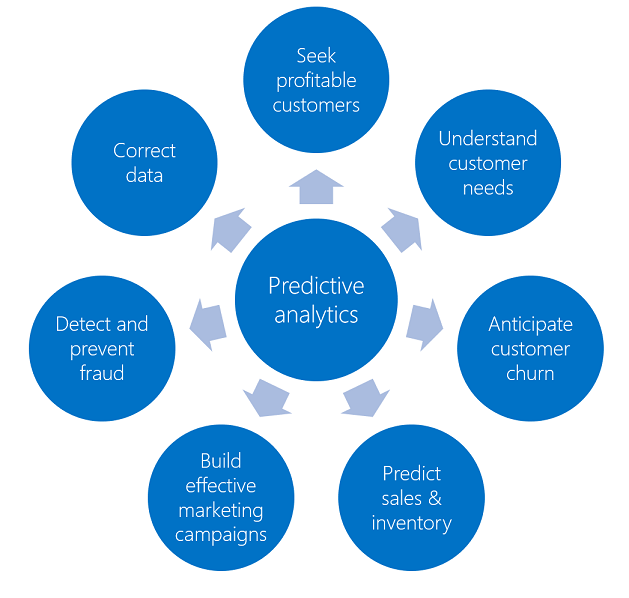 上圖是基礎於 SQL Server所支援的演算法,當時常見的的應用情境但不限於此,包含有:
上圖是基礎於 SQL Server所支援的演算法,當時常見的的應用情境但不限於此,包含有:
A.更正資料:透過 Pattern/Model 可以減少人力在更正錯誤的資料上
B.找出能對營收有貢獻的客戶:根據80/20法則,若我們可以找到20%的高貢獻客戶是可以輕易達標80%的業績目標,所以需要一個好方法來找到這20%
C.了解客戶的需求:要如何做好up-selling與cross-selling又不讓客戶覺得不舒服地被推銷?就會需要透過分析客戶行為或是客戶資料(Profile)
D.找出哪些是即將要流失的客戶:雖然我們都知道攻下五個新客戶還不如維持好一個老客戶,以及客戶關係(CRM)的重要,但是我們要如何得知客戶將要離開了呢?
E.測試接下來的營收與庫存:企業的管理者需要許多資訊來協助他治理公司,包含了公司未來的營收數據、庫存數據,甚至是相關趨勢…
F.規劃出有效地市場行銷方案:消費市場千變萬化,該怎麼打造出天時地利人和的行銷規劃呢?
G.偵測與預防詐欺事件:惡意的詐欺,將會造成客戶與企業的損失。若能適時的發現,除了能杜絕不法情事,將能因為提供更安全的解決方案來贏得更多的客戶 - 資料採礦的流程
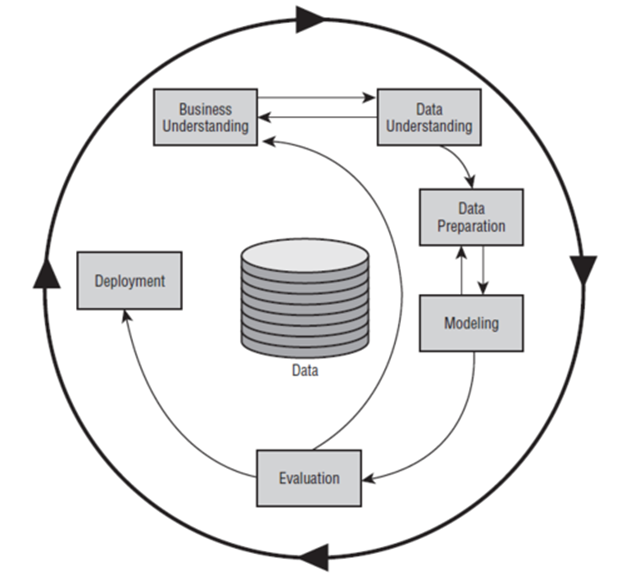 在上圖中,我們可以了解到,標準的資料採礦流程,先要有資料,然後是問題界定(想要解決什麼問題,演算法的選擇),資料準備(資料前處理),模型(建立模型),評估(驗證模型的準確度),佈署(等待前端來呼叫)
在上圖中,我們可以了解到,標準的資料採礦流程,先要有資料,然後是問題界定(想要解決什麼問題,演算法的選擇),資料準備(資料前處理),模型(建立模型),評估(驗證模型的準確度),佈署(等待前端來呼叫)
 在設計階段,當題目被定義後,演算法也決定了。例如某電信公司,想知道用手機綁約二年的客戶,時間到會不會離開?
在設計階段,當題目被定義後,演算法也決定了。例如某電信公司,想知道用手機綁約二年的客戶,時間到會不會離開?
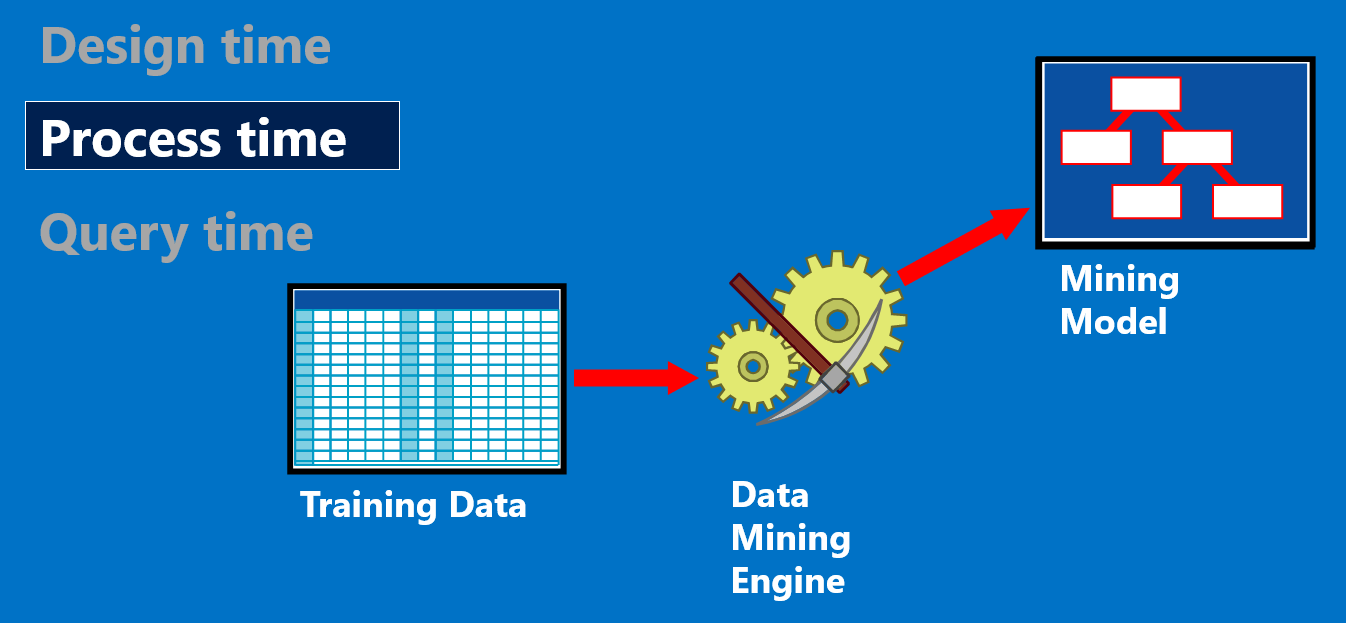 處理階段,要匯入訓練資料,把模型訓練好。把客戶15個月的歷史資料準備好,來訓練這個模型。
處理階段,要匯入訓練資料,把模型訓練好。把客戶15個月的歷史資料準備好,來訓練這個模型。
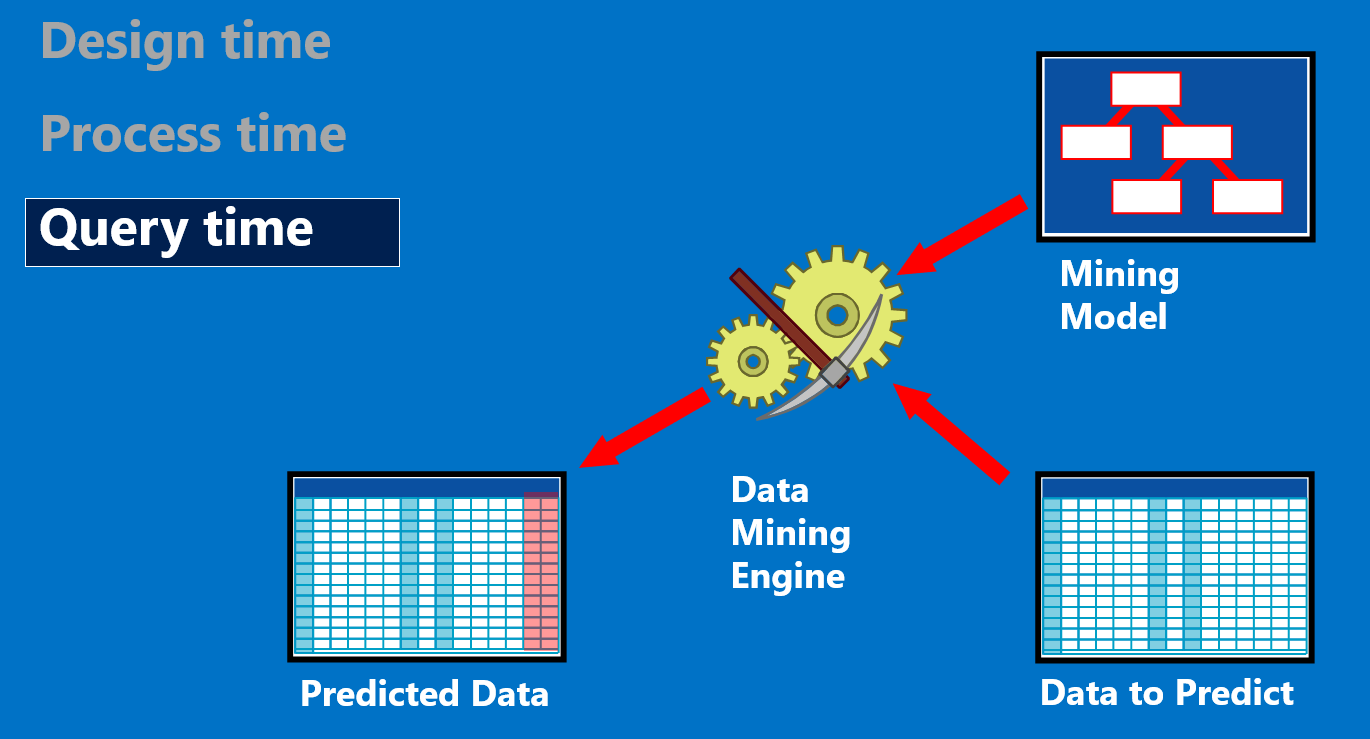 最後,就能拿資料來進行預測。把第16個月以後的資料匯入,就能產出上圖中紅色的Target Value。後續就可交給不同的部門去作業,例如新的手機綁約行銷方案、智慧家庭CrossSell協同銷售、客服部門做客戶挽留…等應用
最後,就能拿資料來進行預測。把第16個月以後的資料匯入,就能產出上圖中紅色的Target Value。後續就可交給不同的部門去作業,例如新的手機綁約行銷方案、智慧家庭CrossSell協同銷售、客服部門做客戶挽留…等應用 - 資料採礦的範例:在官網中提供了一些練習的案例先準備SQL2014的 SSAS服務,然後下載微軟範例資料庫 AdventureWorksDW2012
A.透過資料採礦來分析和預測客戶購買行為的目標郵寄促銷活動的案例(包含群集、決策樹和貝氏機率分類演算法)
B.中繼資料採礦:SSAS提供一個整合式的環境來建立和使用資料採礦模型。 您可以輕易地繫結資料來源、以相同資料建立及測試多個模型,以及部署模型以供預測分析。
不同區域自行車型號的每月銷售報表,收集為單一檢視。(建立預測狀況)
假設您是銷售分析師,上級希望你能預測下一年度產品的銷售狀況、比較不同區域和產品線的預測狀況、判斷不同產品的銷售情況是否會隨著年度時段而有所不同?=>當你利用歷史資料,建立了一個時間序列模型,然後你就可以看圖說故事,說明歐洲、北美和太平洋的產品銷售狀況。接著透過交叉分析,你可以再進一步了解,不同自行車型號的銷售情況隨著時間改變的情況如何?這三個區域的銷售模式之間是否有差異?是否能夠預測銷售旺季?
C.一個包含客戶訂單清單的資料表,和一個顯示每個客戶個別購買情況的巢狀資料表。(建立購物籃狀況)
當行銷部門想把交叉銷售 Cross-selling 的策略加入公司網站,在更新網站時,想要能夠根據客戶的購物籃中的其他產品來預測客戶可能會想購買的產品。另外也想要更了解客戶的購買行為,將客戶想要同時購買的項目做推薦。此時你就會需要購物籃分析(Market Basket Analysis)演算法
D.用於購物籃分析的相同資料,其中加入了識別碼,用來顯示項目購買的順序。(建立時序群集)
行銷部門想了解客戶如何在電子商務網站中的瀏覽行為。公司猜想客戶會依某種次序模式,將產品放入購物籃中。公司希望分析購物次序,以了解客戶如何將相關的產品加入購物籃中。之後,他們就能利用這項資訊來簡化網站的流程,以便引導客戶購買其他產品。時序群集演算法預測客戶接著會將哪一項產品放入購物籃中。
所以你將會需要建立兩個版本的模型:第一個模型只分析購物籃中的產品順序,而第二個模型另外包含一些用於群集的客戶人口統計資料。最後,你將使用這些模型來建立預測,以便向客戶提供產品建議。
E.單一資料表,其中包含來自客服中心的一些初步效能追蹤資料。(建立類神經網路和羅吉斯迴歸模型)
營業部門正在負責處理一個專案,目標是提升客服中心的客戶滿意度。他們雇用廠商來管理客服中心、回報客服中心績效的數據,並要求你分析廠商所提供的一些初步資料。他們想要知道是否有任何有趣的發現。尤其想知道這些資料是否反映出有關人員雇用的任何問題,或改善客戶滿意度的方式。這個資料集很小,只包含期限為 30天的客服中心作業。這些資料會追蹤每個排班的新進和資深操作員數目、來電數目、訂單數目、必須解決的問題數目,以及客戶等候電話回應的平均時間。資料也包含以放棄率(Abandon Rate一種客戶挫折度的指標)為基礎的服務品質標準。
由於你對於資料呈現的內容沒有任何預先的期待,因此您決定使用類神經網路模型來探索可能的相互關聯。類神經網路模型經常用於進行探索,因為這種模型可以分析許多輸入和輸出之間的複雜關聯性。
換言之,透過類神經網路演算法,你可以了解有什麼因數會影響客戶滿意度?以及,客服中心可以做些什麼來改善服務品質?
最後你根據這些結果,再一步建立一個羅吉斯迴歸模型以進行預測,當你把上述的因素加入客戶服務之後,客戶中心的績效是否會變好?
F.進階應用或與應用程式整合。當使用者想建立自訂應用程式,使用資料採礦功能能擴大其資料分析的功能。就會需要使用資料採礦延伸模組(DMX)查詢語言 - 演算法說明
 SQL Server提供了五大類的演算法,包含:
SQL Server提供了五大類的演算法,包含:
1.分類:根據已知樣本的特徵值,去判斷一個新的樣本,會屬於哪種已知的類別?例如收到的電子郵件,可以分成是不是垃圾郵件?電信業,可以把客戶分成會不會續約?銀行業,可以把客戶分成會不會不還錢?
俗話說:龍生龍,鳳生鳳,老鼠生的兒子會打洞。這個類別被歸為監督式學習,至少有8種子類,包含了 Liner classifers(線性分類器)、Support vectoer machines(支持向量機器)、Quadratic classifiers(二元分類器)、Kernel estimation(核推估)、Boosting(分類)、Decision trees(決策樹)、Neural networks(類神經網路)、Learning vector quantization(學習式向量量化)。以下只介紹 SQL Server有提供的…

**線性廻歸(上圖),它非常直覺從已知樣本中一刀切下去,一分為二,當我們把新資料畫上去,就能區分出是屬於左半類別或是右半類別?

**羅吉斯廻歸(上圖),用在衛生福利部疾病管制署,利用人口統計資料來預測特定疾病的風險。用在交通部觀光局,尋找影響客戶重覆光顧商店的因素。用在文件、電子郵件或其他具有許多屬性的物件分類,判斷是否為垃圾郵件。
**貝氏機率分類,它是利用已知的事件發生之機率來推測未知資料的類別。當新的樣本資料加入時,只要再調整某些機率,及可以得到新的分類的模型(機率)。最初常用於文字的分類與檢索,例如利用詞頻來判斷其文章的類別,是體育、娛樂、社會、政治…等新聞或議題,後來這個演算法愈用愈廣,它可以協助我們在分析問題時,可以快速切換不同的角度,或是做換位思考

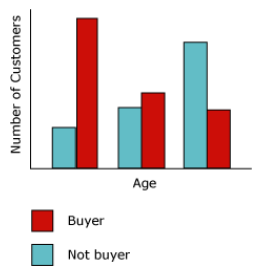
我們以上面所提及的資料採礦範例中(A)郵寄促銷活動的案例為例,當行銷部門決定郵寄廣告傳單來鎖定目標潛在客戶時,為了成本的節省,他們想要將廣告傳單只寄給那些有可能回應的客戶。公司會將有關人口統計資料與舊郵件回應…等相關資訊儲存在資料庫中。就可以應用其人口統計資料(例如年齡和地點)來協助預測促銷的回應,進而,藉由將潛在客戶與具有類似特性,而且過去曾向公司購買產品的客戶做比較。尤其是分析那些有購買腳踏車和沒有購買腳踏車的客戶之間的差異時。
上圖中,我們利用 SSDT中貝氏機率分類檢視器來觀察,第二個欄位(特徵值)「通勤距離」,了解不同通勤距離在人口分佈中的狀況為何?當我們限縮 1~2 Mile(英哩)的客戶時,再依據其購買自行車的機率是 0.387,而不購買自行車的機率則是 0.287,判斷是否要以通勤距離成為發動行銷的主軸?
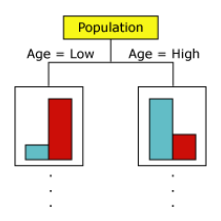 **決策樹它可用在離散或是連續性數值的類別預測,並藉由推導出類別的成因來解決問題。以離散數值為例(如上圖),在預測哪些客戶可能購買腳踏車時,如果10個年輕客戶當中有9個會購買腳踏車,但是10個年紀較大的客戶當中只有2個人會購買腳踏車,則演算法會推斷年齡是腳踏車購買的理想特徵值。接著,下一個影響購買腳踏車的特徵值,可能是通勤距離、或是工作類型…等,所以,決策樹就是依據傾向於特定結果的趨勢來產生預測。
**決策樹它可用在離散或是連續性數值的類別預測,並藉由推導出類別的成因來解決問題。以離散數值為例(如上圖),在預測哪些客戶可能購買腳踏車時,如果10個年輕客戶當中有9個會購買腳踏車,但是10個年紀較大的客戶當中只有2個人會購買腳踏車,則演算法會推斷年齡是腳踏車購買的理想特徵值。接著,下一個影響購買腳踏車的特徵值,可能是通勤距離、或是工作類型…等,所以,決策樹就是依據傾向於特定結果的趨勢來產生預測。
**類神經網路又稱為ANN(Artificial neural networks),是一種模仿生物體的神經網路(大腦)的結構和功能的數學模型或運算模型,神經網路由大量的人工神經元聯結進行計算。大多數情況下人工神經網路能在外界資訊的基礎上改變內部結構,是一種具有學習功能的自適應系統。
類神經網路演算法在分析複雜輸入資料(例如來自製造程序或商業程序的資料)或商務問題(有大量培訓資料可用但很難使用其他演算法來衍生規則)時很有用。例如,分析製造和產業流程、文字採礦、行銷和促銷分析,例如衡量直接郵寄促銷廣告或電台廣告活動的績效。從記錄資料中預測股價移動、貨幣波動或其他高流動性財務資訊。或是,任何分析許多輸入以及較少輸出之間複雜關聯性的預測模型。
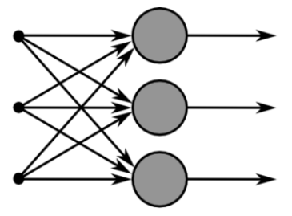 類神經網路演算法會建立最多由三層節點(有時稱為神經)所組成的網路。 這三層分別是:輸入層/隱藏層/輸出層,上圖就是輸出層的示意圖。這種網路一般稱為感知器(對單隱藏層)或多層感知器(對多隱藏層),神經網路的類型已經演變出很多種,這種分層的結構也並不是對所有的神經網路都適用。例如 CNN(Convolutional Neural Network)卷積神經網路就是深度學習的一種演算法。
類神經網路演算法會建立最多由三層節點(有時稱為神經)所組成的網路。 這三層分別是:輸入層/隱藏層/輸出層,上圖就是輸出層的示意圖。這種網路一般稱為感知器(對單隱藏層)或多層感知器(對多隱藏層),神經網路的類型已經演變出很多種,這種分層的結構也並不是對所有的神經網路都適用。例如 CNN(Convolutional Neural Network)卷積神經網路就是深度學習的一種演算法。

每個類神經網路模型都有一個代表模型及其中繼資料的單一父節點,以及一個提供輸入屬性之相關描述性統計資料的臨界統計資料節點 (NODE_TYPE = 24)。臨界統計資料節點相當實用,因為該節點摘要輸入的相關資訊,你就不需要從個別節點查詢資料。在這兩個節點下面,至少還有兩個節點,可能更多,取決於模型的可預測屬性數量。第一個節點 (NODE_TYPE = 18) 永遠代表輸入層的最上層節點。在這個最上層節點之下,你可以找到包含實際輸入屬性及其值的輸入節點 (NODE_TYPE = 21)。每個後續節點都包含不同的「子網路」 (NODE_TYPE = 17)。每個子網路永遠包含一個隱藏層 (NODE_TYPE = 19),以及一個該子網路的輸出層 (NODE_TYPE = 20)。
2.推估:它主要是處理連續數值的預測,包含了決策樹、線性廻歸、羅吉斯廻歸、類神經網路,這個類別也是屬於監督式學習。至於為何有些演算法會跟"分類 Clsassification"重覆?因為某些演算法是同時可以處理連續與離散的數值,但是處理或設定的方法還是有些不同之處,需要注意…
**當線性廻歸與羅吉斯廻歸遇到連續數值時,我們該怎麼考慮?請回顧上面的圖(我在裡面藏了伏筆),請注意這二張圖的上方,為何要在 X軸畫一條標明數字1的虛線?主要是要說明,當你只想處理介於0到1的資料時,使用羅吉斯廻歸將會是最佳解。概念像是線性廻歸顆粒度比較大,當我們篩選掉超過1以上的資料後,再加上羅吉斯廻歸顆粒度比較小的演算法,可以將推估做得更準確些…
**決策樹


針對連續數值(左上圖),決策樹演算法將會應用線性迴歸(但它不是一直線或是S曲線)的方法,來決定決策樹分岔之處。換句話說,它會尋找樹狀結構中主要為線性的線段,並為這些線段建立不同的廻歸公式。藉由將資料分成不同線段,就可以改善模型在估計資料時的作業績效。
為了預測結果,需要算出模型中的樹狀分支,分別是y=.5X+5與y=.25X+8.75。散佈圖中兩條線交叉的點就是非線性點(右上圖),也是在決策樹模型中之節點會分岔的那個點。
3.群集:依據你給的條件(大方向)進行分群(類),例如用在客戶區隔、晶圓瑕疪類型診斷、文字主題分析。
俗話說:物以類聚。這個類別被歸為非監督式學習,它可以把靜態的資料中分出適當的群組(類別)。至少有15種子類,其中又以時效 CP值高的 K-Means最出名。它屬於 Centroid models 是由下至上這個方向來進行,意思是會從每個物件(假設是散佈圖中單獨一個點)開始做分類,然後不斷地融合靠近它的點,直到每個物件都被算過。快雖快但是不保證每個點都能被分類的缺點,例如下圖中有幾個點並沒有被分到群組內。
它的流程是:選擇群集的個數 K,任意產生 K個群集,然後確定群集中心,或者直接生成 K個中心。對每個點確定其群集中心點。再計算其群集新中心。重複以上步驟直到滿足收斂要求。通常就是確定的中心點不再改變。

上圖是微軟官網中群集演示法的示意圖
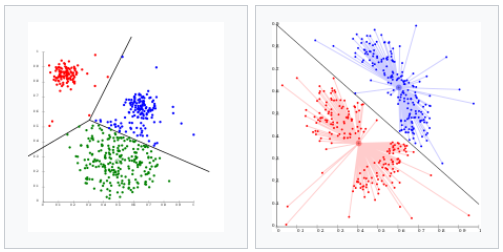 左上圖是將資料分成三類(群),右上圖是將資料分成二類(群)並且畫出每個點與中心(平均值)的最短距離
左上圖是將資料分成三類(群),右上圖是將資料分成二類(群)並且畫出每個點與中心(平均值)的最短距離
4.預測:隨著時間不同所帶來的變化,這個類別也是屬於非監督式學習。
**時間序列(Time Series)演算法是微軟針對連續數值的預測,在合併多種演算法所自行開發出來的。應用的場景顧名思義會跟時間有關,例如一段時間的產品銷售狀況,來提供最佳化功能。這個演算法除了 SQL Server也出現在 Excel、PowerBI…等產品

上圖是一個產品在四個不同的銷售區域銷售的時間預測。模型會將每一個區域的銷售繪製成不同顏色的線條,再透過一條垂直的線條將每個區域分成兩個部分。歷程記錄資訊會出現在垂直線的左方,這些就是建立模型的來源資料;預測的資訊會出現在垂直線的右方,就是根據演算法讓模型所做出的預測。至於來源資料和預測資料的組合則稱為「序列」。
5.關聯分組:以關聯與序列規則來分組,包含了關聯規則與決策樹演算法
**關聯規則分析,是一種在大型資料庫中發現變數之間的有趣性關係的方法。它的目的是利用一些有趣性的量度來辨識資料庫中發現的強規則。
由超市的POS系統記錄的大批交易資料中產品之間的規律性。例如,從銷售資料中發現的規則 {啤酒、洋芋片}→{尿布} 發現如果顧客買啤酒,他們也有可能買尿布(尤其是週五)。此類資訊可以作為做出促銷定價或產品置入等行銷活動決定的根據。除了上面購物籃分析中的例子以外, 關聯規則如今還被用在許多應用領域中,包括網路用法挖掘、入侵檢測、連續生產及生物資訊學中。與序列挖掘相比,關聯規則通常不考慮在事務中、或事務間的專案的順序。

SQL Server的關聯規則分析,是採用 Apriori 演算法。裡面會使用到兩個參數,包含案例數與機率,是用來描述它產生的項目集和規則。(上圖中)項目集可能是 "Mountain 200=Existing, Sport 100=Existing",且可能有 710 個案例數。 接著,演算法會從項目集產生規則。依據演算法識別為重要的其他特定項目出現與否,這些規則將用來預測項目在資料庫出現與否。例如,若規則是「if Touring 1000=existing and Road bottle cage=existing, then Water bottle=existing」,則機率為 0.812。在這個範例中,演算法識別出由於購物籃內有 Touring 1000 輪胎和水壺架的存在,所以就能預測出水壺也可能會出現在購物籃內(因為買水壺架子順便連水壺也一起買是蠻合理的)。
另外,關聯規則還需要考量所處理的值的類型(離散/連續)、所涉及的資料維數(度)、所涉及的抽象層次(廣義的運動鞋與龍頭Nike是屬於不同的抽象層次)換句話說,這個演算法並不會分析模式,而是產生「候選項目集」並接著加以計算。項目可能代表事件、產品或屬性的值,根據分析的資料類型而定。在常見類型的關聯模型中,代表「是/否」或「遺漏/現有」值的布林值變數會指派給每個屬性,例如產品或事件名稱。購物籃分析是關聯規則模型的其中一個範例,該模型使用布林值變數代表客戶購物籃中的特定產品是否存在。接著,演算法會針對每個項目集建立代表支援及信心的分數。這些分數可用來從項目集衍生有趣性規則並排列其次序。如果是是連續數值屬性,可以將數字「分隔」或群組到值區中。接著就可以將離散化的值當做布林值或屬性值配對處理。 - 結論
 上圖是這五大類所包含的演算法整理
上圖是這五大類所包含的演算法整理
在本文的開頭有提到,便利商店的集點送公仔。它的應用情境是,市場行銷部門想透過異業合作增加銷售金額。於是他們從POS系統調出了平均客單價,然後把這個金額,除了加上贈品的成本之外,還要再乘以一個斜率,就可以透過門市來進行此次的行銷。有趣的是,一般消費者來到便利商店消費時,為了想得到這個公仔,勢必還要再多買一件東西,但又不會覺得買不下手。心中的OS是:「好可惜就差一點金額,一定要集到這個點數」。所以基礎於這個斜率,消費者也不會覺得門檻很高,很順手地就隨便抓了個點心、零食、飲料,甚至是相同的商品。便利商店的營收自然可以提升15%以上(斜率就是與營收增加有關的變數)。可惜當各家便利商店用的太兇,效果就會打折扣,需要再找新的應用或是解決方案…
資料採礦發展至今是一項很成熟的技術。例如電信業,二階段,先分類是否續約,再推估顧客終身價值,提供相關產品或方案給客戶。他們會分二階段作業,先分類客戶是否會續約?再推估顧客終身價值,以利提供相關產品或方案給客戶。如此一來,省時又精準!既不會為了要跑完所有的客戶等到天荒地老,也不會因為跑出來的資料太粗略實用性不高
下一棒就拉力給雲端的機器學習ML,若是在地端就是用R或Python語言來做資料採礦或是機器學習ML
 以上是 SQL2017 R Service 所支援的演算法大分類
以上是 SQL2017 R Service 所支援的演算法大分類
李秉錡 Christian Lee
Once worked at Microsoft Taiwan