使用 HtmlAgilityPack 擷取 巴哈姆特 新聞
1. 到 Nuget Package 下載 HtmlAgilityPack 套件
2. 新增 using
using System.IO;
using HtmlAgilityPack;
using System.Text;
using System.Net;
3. 於Page_Load插入以下程式碼片段
//指定來源網頁
WebClient url = new WebClient();
//將網頁來源資料暫存到記憶體內
MemoryStream ms = new MemoryStream(url.DownloadData("http://gnn.gamer.com.tw/4/133124.html"));
//以巴哈新聞例http://gnn.gamer.com.tw/
//4/133124.html 表示為文章編號
// 使用 UTF8 編碼讀入 HTML
HtmlDocument doc = new HtmlDocument();
doc.Load(ms, Encoding.UTF8);
// 裝載第一層查詢結果
HtmlDocument hdc = new HtmlDocument();
//XPath 來解讀它 /html[1]/body[1]/div[3]
hdc.LoadHtml(doc.DocumentNode.SelectSingleNode("/html[1]/body[1]/div[3]").InnerHtml);
//這邊因為公告內文含有 img tag 所以需使用 InnerHtml
string txt = hdc.DocumentNode.SelectSingleNode(".").InnerHtml.Trim();
// 去頭
int p = txt.IndexOf("<!--區塊1開始-->");
txt = txt.Substring(p);
// 去尾
p = txt.IndexOf("<!--新聞內容結束-->");
txt = txt.Substring(0, p);
// 解析 標題與內文 以字串 "<!--新聞內容開始-->" 分隔
string[] txts = txt.Split(new string[] { "<!--新聞內容開始-->" }, StringSplitOptions.RemoveEmptyEntries);
// 輸出結果
string result = string.Format("標題:{0}<br>內文:<br>{1}", txts[0], txts[1]);
Response.Write(result);
4.前端部分可以把 Default.aspx 的全部 HTML TAG 先刪除 比較乾淨
5.以上參照自:https://dotblogs.com.tw/jackbgova/2014/06/10/145471
6.查詢XPATH可以利用GOOGLE CHROME F12
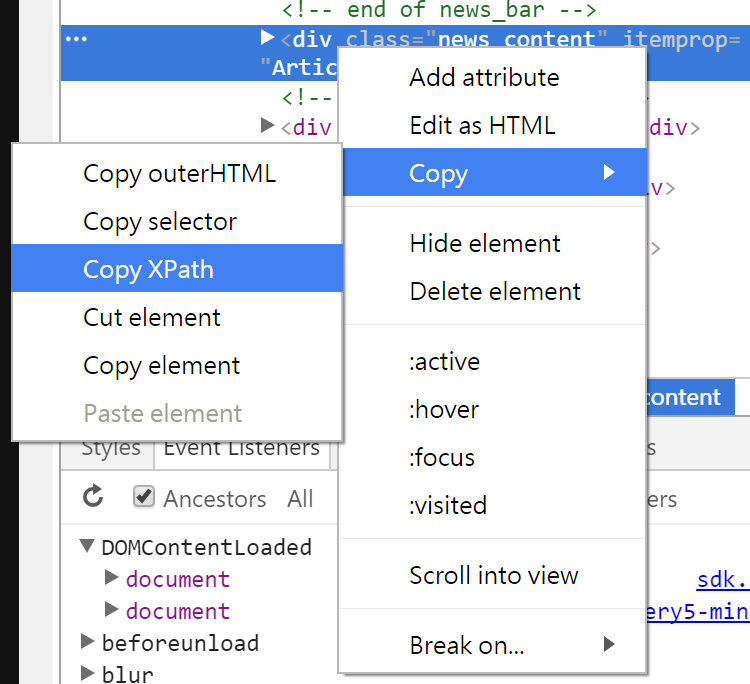
7.查詢新聞連結清單
string link, XPath;
link = "http://gnn.gamer.com.tw/index.php?k=4";
XPath = "/html[1]/body[1]/div[3]/div[1]/div[5]/div[2]";
// 指定來源網頁
WebClient url = new WebClient();
// 將網頁來源資料暫存到記憶體內
MemoryStream ms = new MemoryStream(url.DownloadData(link));
// 使用 UTF8 編碼讀入 HTML
HtmlDocument doc = new HtmlDocument();
doc.Load(ms, Encoding.UTF8);
// 裝載第一層查詢結果
HtmlDocument hdc = new HtmlDocument();
// XPath 來解讀它
hdc.LoadHtml(doc.DocumentNode.SelectSingleNode(XPath).InnerHtml);
HtmlNodeCollection htnode = hdc.DocumentNode.SelectNodes(@"//div[@class='GN-lbox2B']/div/a");
foreach (HtmlNode currNode in htnode)
{
string currLink = currNode.SelectSingleNode(".").Attributes["href"].Value;
Response.Write(currLink + "<br/>");
}
