經過前面的2篇實驗,實驗出Ad hoc使用到臨時資料表(#TABLE)每次都會重新編譯,至於預存程序(SP)使用臨時資料表則要視情況而定。上一篇還有一個延伸問題,既然預存程序使用臨時資料表(#TABLE)不一定會觸發重新編譯而更新臨時資料表統計值,如果產生臨時資料表的資料源在第一次編譯之後,資料量變動很大,而臨時資料表要和其他資料表Join,是否會導致SQL Query Optimizer應該正確選擇合併或雜湊連結(Merge/Hash Join)卻選擇巢狀迴圈(Nested Loop)而導致效能問題?
答案是不會! 因為資料源的資料表統計值有更新,有使用到的預存程序,本來就會重新編譯執行計畫。
好!繼續檢定這個假說!
- 我們會先新增加一個球員資料表,裡面只會有4筆資料,然後用球隊的臨時資料表和球員資料表Join,最後保留執行計畫內容(Nested Loop)作為對照組;
- 接下來,將球隊資料表灌大200萬筆,同時開啟重新編譯的監測(擴充事件、Profiler),然後執行,最後觀察執行計畫(Merge/Hash Join)作為實驗組。
測試環境準備
除了上兩篇準備好的環境,這邊重建球隊資料表,另外再增加一個球員資料表,並且新增4筆資料
球隊資料表
DROP TABLE [Teams]
CREATE TABLE Teams
(
CountryName nvarchar(30),
FIFARanking int,
GroupID varchar(1)
)
INSERT INTO Teams VALUES('Russia',65,'A'),('Saudi Arabia',63,'A'),('Egypt',30,'A'),('Uruguay',17,'A')
INSERT INTO Teams VALUES('Portugal',3,'B'),('Spain',8,'B'),('Morocco',48,'B'),('Iran',34,'B')
Create INDEX IX_Teams ON Teams(FIFARanking)
球員資料表:
Create Table Player
(
PlayerId int identity primary key clustered,
name nvarchar(30),
CountryName nvarchar(30)
)
Create index IX_Player on Player(CountryName)
insert into Player values('Sergio Ramos','Spain'),('Andrés Iniesta','Spain'),('Isco','Spain'),('Isco','Spain')
新建立一支預存程序,內容除了查詢球隊,也希望球隊查詢出來之後,要和球員資料表連結(Join)。
CREATE PROCEDURE [dbo].[uspTestJoinTempTableRecompile]
AS
IF OBJECT_ID('tempdb..#DATA') IS NOT NULL
DROP TABLE #DATA;
SELECT * INTO #DATA FROM Teams
WHERE FIFARanking >= CONVERT(INT,RAND() * 10)
SELECT * FROM #DATA A JOIN Player B
ON A.CountryName = B.CountryName
對照組(臨時資料表只有少量資料)
先執行1次,並且打開包括實際執行計畫
EXEC uspTestJoinTempTableRecompile
查詢出拉莫斯、小白及2名伊斯科。
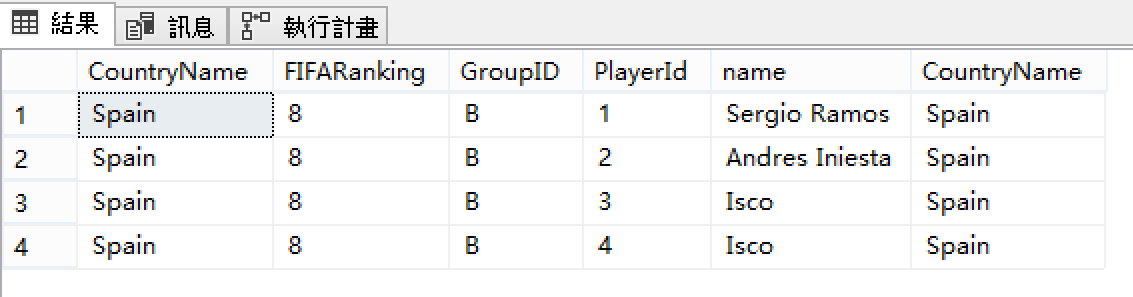
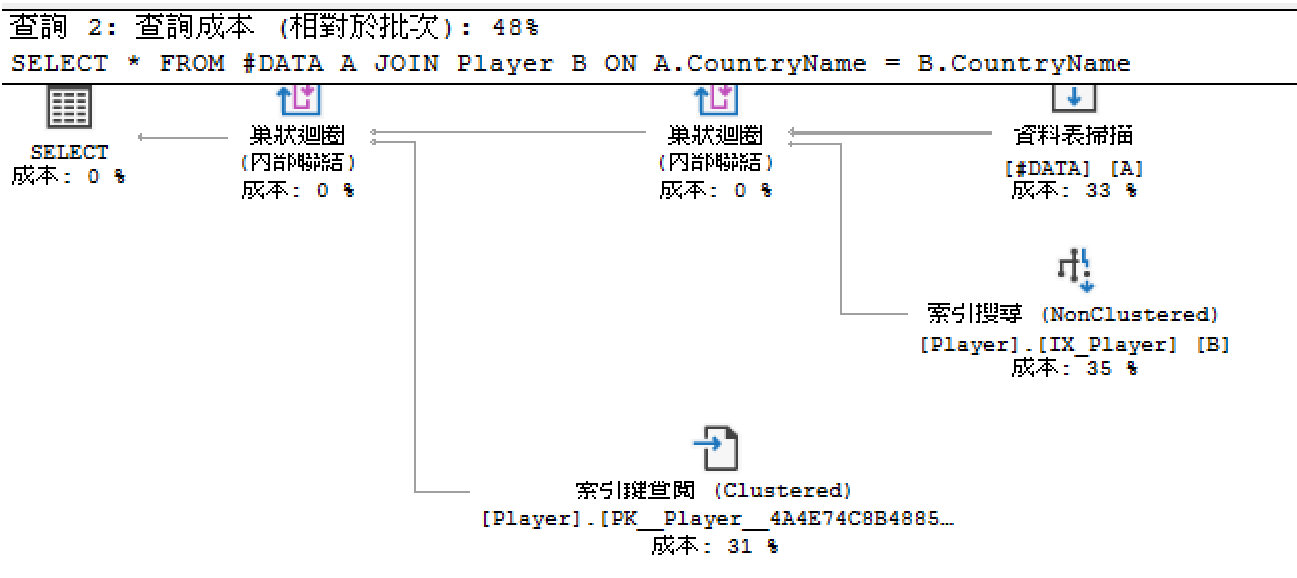
執行計畫如預期的採用巢狀迴圈來連結Player資料表(索引搜尋)。
順便也記錄Temp table統計值中的長條圖(HISTOGRAM):
USE Tempdb
SELECT
OBJECT_NAME(s.object_id) AS TableName
,s.name
,COL_NAME(scol.object_id, scol.column_id) AS 'Column'
,hist.step_number
,hist.range_high_key
,hist.range_rows
,hist.equal_rows
,hist.distinct_range_rows
,hist.average_range_rows
FROM sys.stats AS s
JOIN sys.stats_columns AS scol (NOLOCK)
ON s.stats_id = scol.stats_id
AND s.object_id = scol.object_id
AND scol.stats_column_id = 1
CROSS APPLY sys.dm_db_stats_histogram(s.[object_id], s.stats_id) AS hist
WHERE OBJECT_NAME(s.object_id) Like '#%'
ORDER BY s.name,hist.step_number,COL_NAME(scol.object_id, scol.column_id)
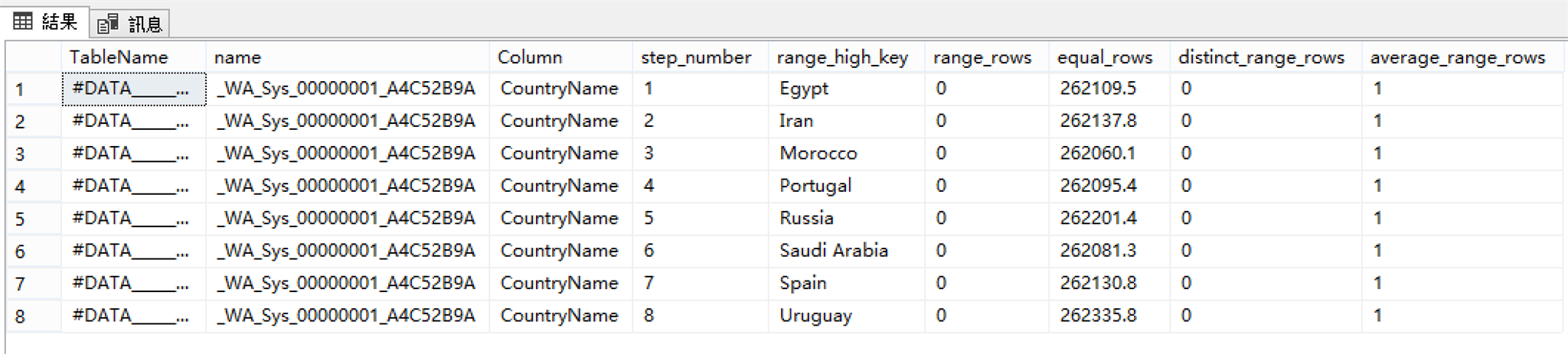
長條圖(HISTOGRAM)查詢結果: 平均每個球隊1筆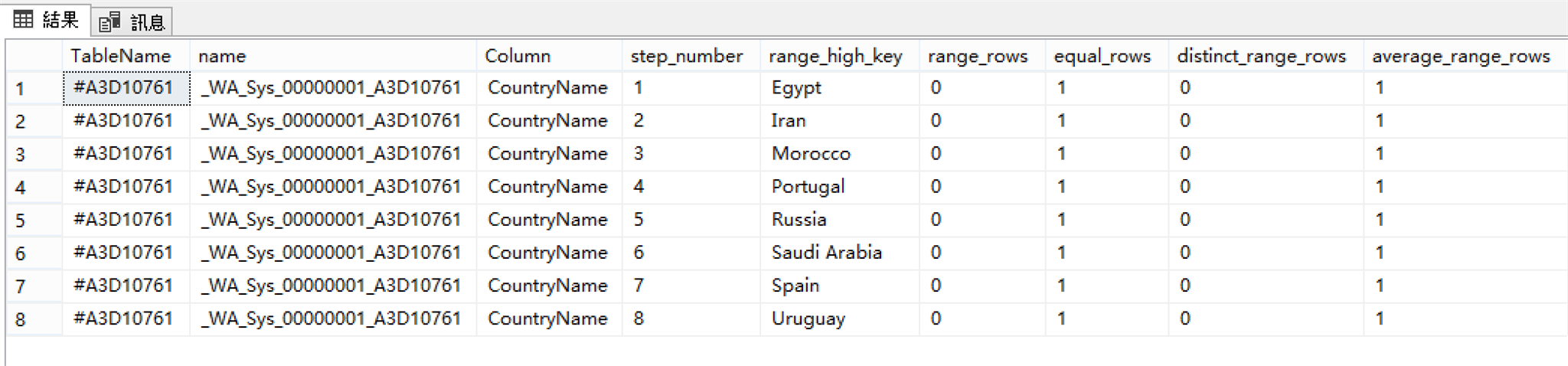
在進行實驗之前,我們先將暫存資料表的資料來源Teams資料表放大18次方。
INSERT INTO Teams
SELECT * FROM Teams
GO 18
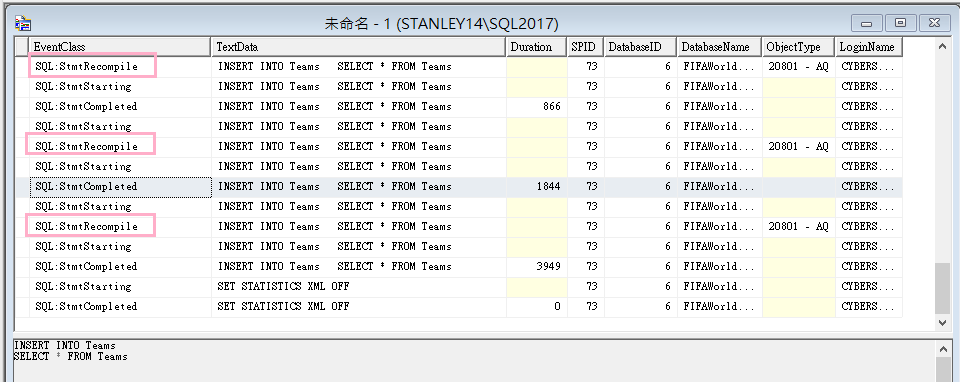
由於統計值的改變,每次讀取現有資料列來新增資料時,都有出現重新編譯
現在有200萬筆國家隊資料了!
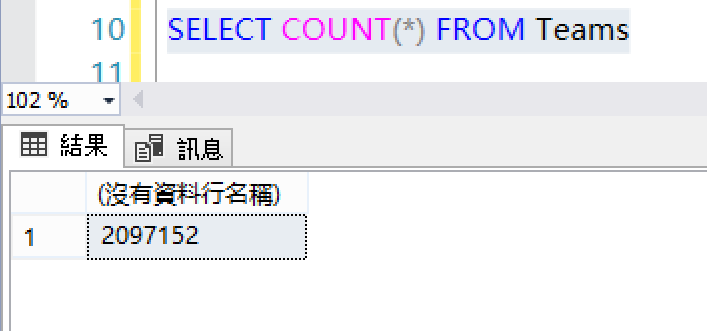
即使只是COUNT(*),也是會因為統計值變更,而需要重新編譯執行計畫。
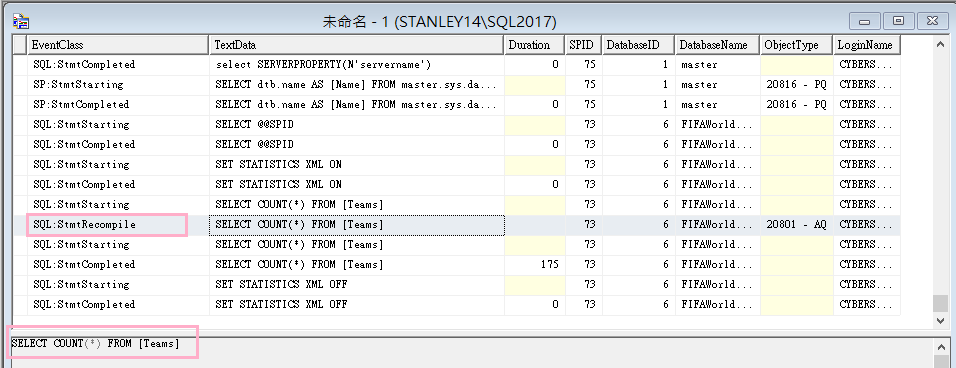
實驗組(臨時資料表出現大量資料)
執行預存程序,打開包括實際執行計畫
EXEC uspTestJoinTempTableRecompile
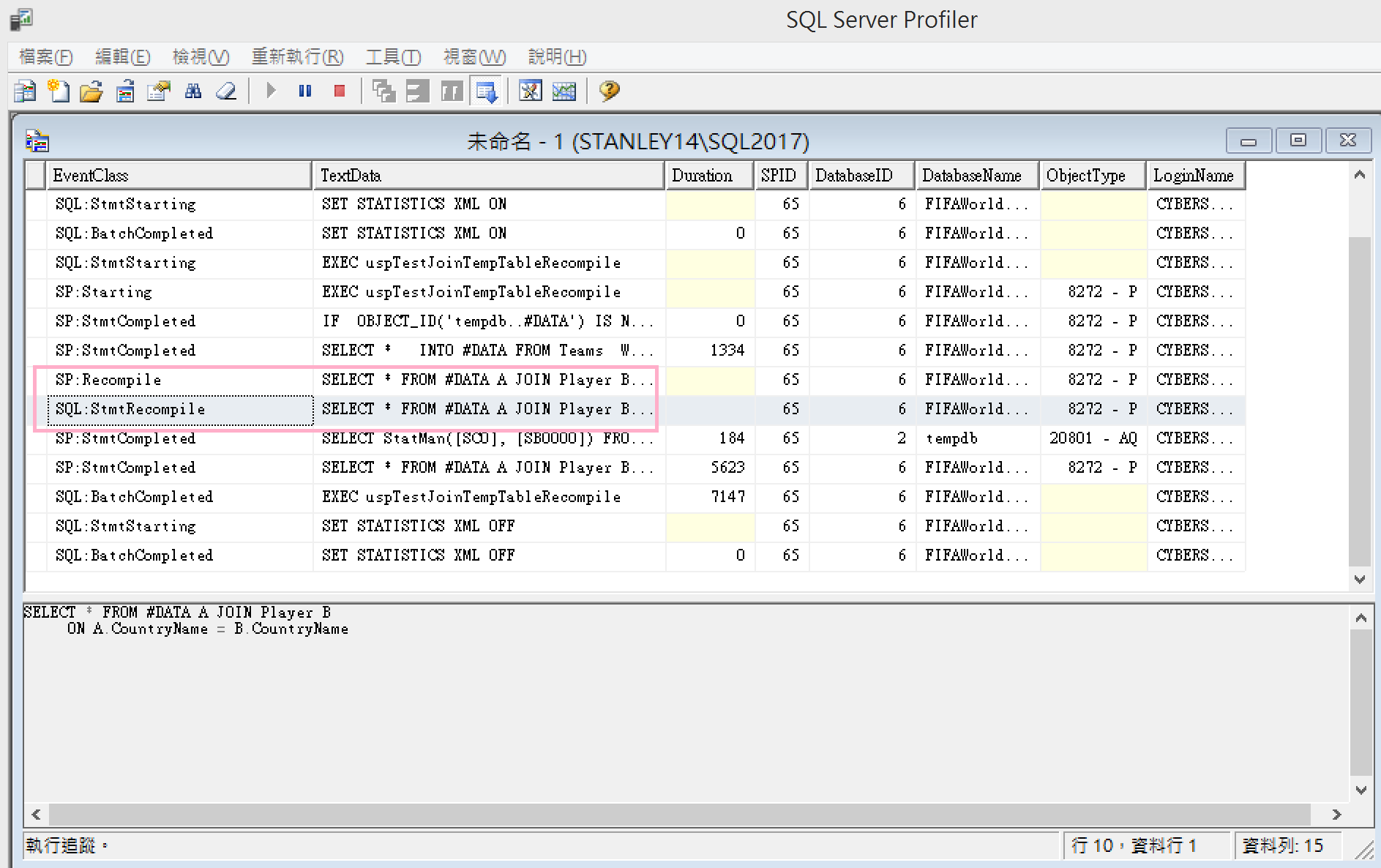
從Profiler觀察到重新編譯(Recompile)!
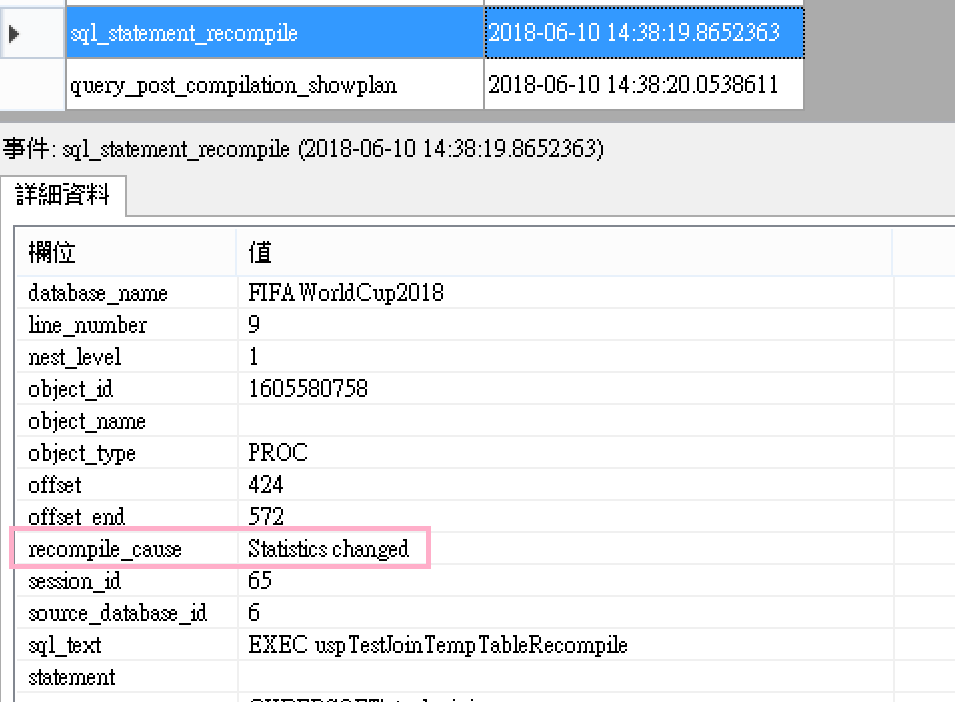
從擴充事件也觀察到重新編譯,Recompile_cause是statistics changed! 統計值改變
Temp Table的統計值也有更新,從長條圖來看,每個國家球隊的筆數都從1筆增加到26萬筆了。
觀察到3個事證:
- Profiler出現重新編譯(Recompile)
- 擴充事件也發現統計值改變觸發了重新編譯(Recompile)
- 不只是資料源資料表的統計值改變,Temp Table也更新了。
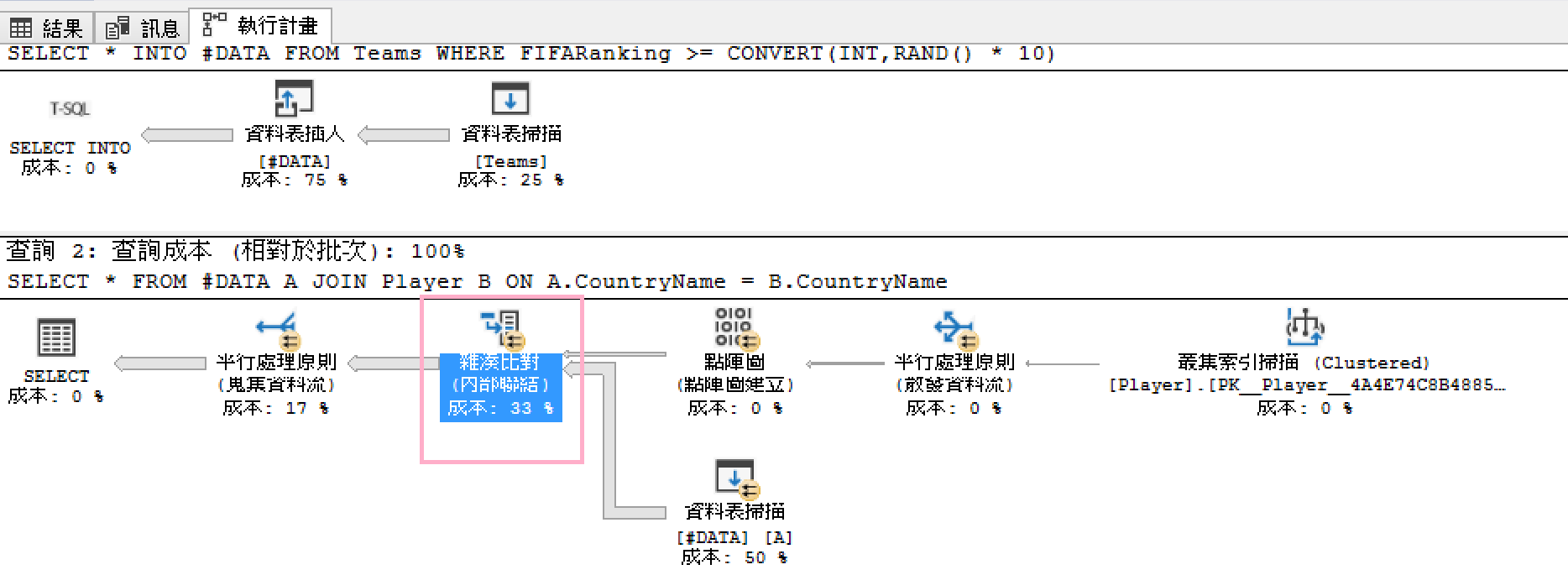
從下圖的執行計畫來驗證結果: SQL Query Optimizer果然優秀的選擇Hash\Merge Join,放棄Nested Loop的方式與球員資料表連結。
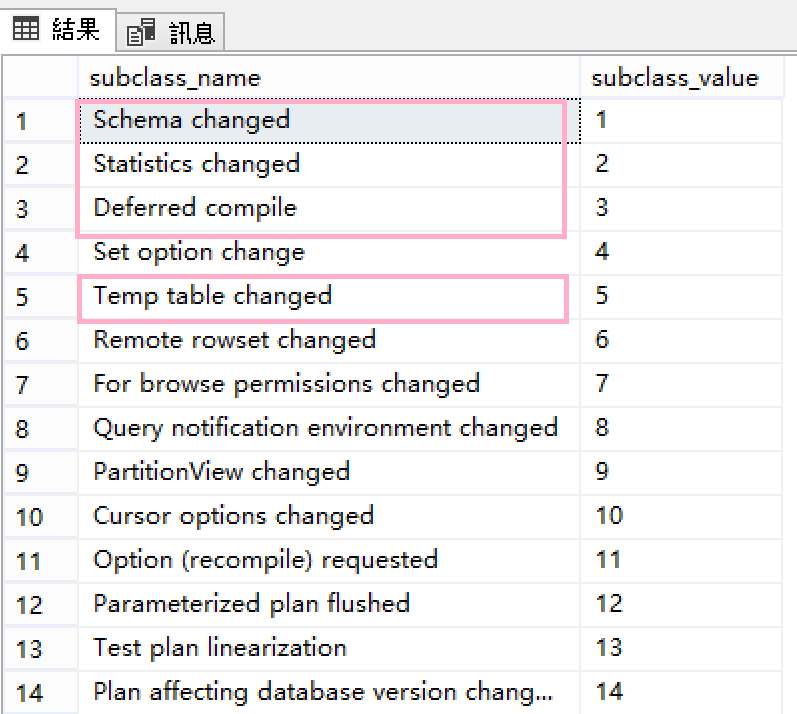
這三篇的實驗的經驗累積下來,我們剛好遇到了4種引發重新編譯的原因了。
小結:
- 因為Temptable是稀有的(只有1個),所以我們還是會期待線上交易減少使用臨時資料表(#TABLE) 。
- 批次型交易使用臨時資料表(#TABLE)時,可以透過建立索引來觸發重新編譯,進而進行統計值更新。
 2018.06 台北市大同區
2018.06 台北市大同區
參考
[SQL Server]暫存資料表(#TABLE)引發的重新編譯Re-Compilations(Ad hoc)
[SQL Server]暫存資料表(#TABLE)引發的重新編譯Re-Compilations(SP)
[SQL Server][Statistics]統計值(一)看見統計值