http 的 header 可以塞入壓縮的選項,當 client 端收到 header 有壓縮的選項時,會自動進行解壓縮,以增加傳輸效率,然而 kafka 是否也有類似的功能可以進行壓縮與設定
由於 kafka 是個高效的 mq 服務,在傳輸過程會有大量的資料
若是不壓縮的話,在網路頻寬不足的情況下,是有可能會造成資料的延遲
然而在 topic 裡有這個設定 compression.type 可以查看

kafka 共提供了四種壓縮方式
- Gzip (較舊的壓縮方式)
- Snappy
- Lz4
- Zstd
然而這四個壓縮方式哪個適合自己的系統,需要自行壓測看看才會知道
由於 Snappy.net 的套件已經不再維護了,所以 BenchMark 的效能的壓測的效果而言 LZ4, ZSTD 是不錯的選擇

生產者如何設定壓縮
以 Confluent.Kafka 套件為例的話,只要生產者端進行設定即可,然而消費者端完全不需要修改,這點的實作看來跟 http 的概念是一樣的
var config = new ProducerConfig
{
BootstrapServers = "localhost:9092",
CompressionType = CompressionType.Gzip
};觀察封包內容
這邊是以 wireshark 來分別查看生產者跟消費者的封包結果
使用 wireshark 的好處是已經內建了 kafka 協定的封包解析,若是 kafka 服務不是預設的 9092 port 的話,將會補捉不到
下圖生產者發送訊息,左邊是沒有進行壓縮的封包內容,右圖是有進行 ZSTD 的壓縮內容

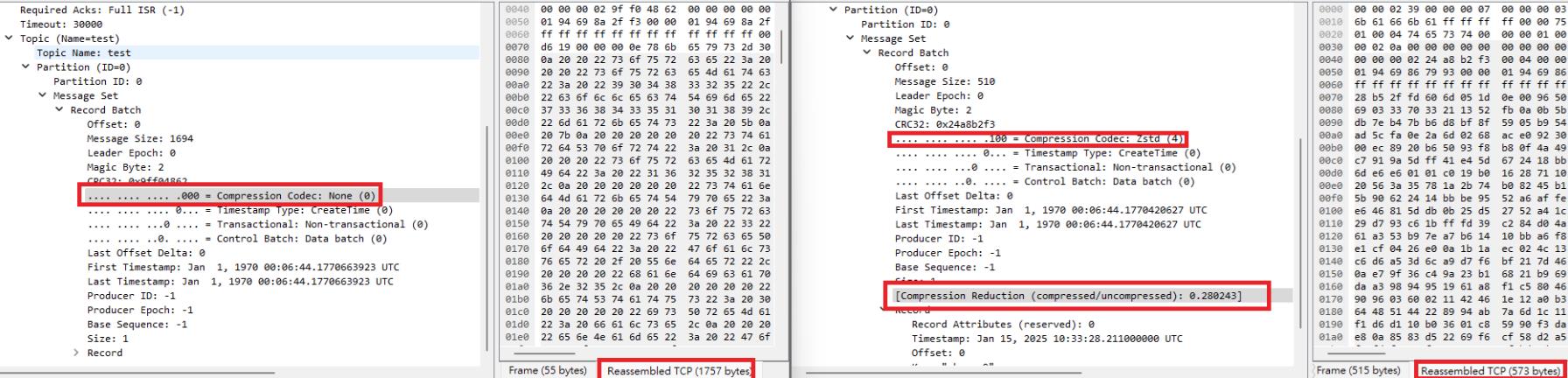
消費者端
以下是收取 gzip 的內容,wireshark 甚至也有內建 gzip 的解壓縮,所以傳送的內容也能 decode 後進行確認的

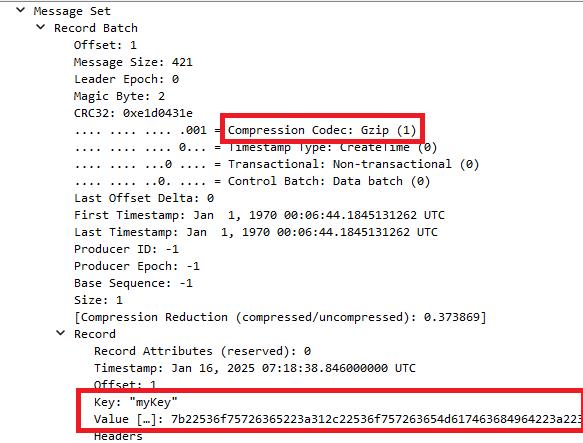
更棒的一點是,kafka 的壓縮方式如果是設定成 producer,則代表所有壓縮的形式都是由 producer 決定
也就是說一個 topic 上可以允許各種的壓縮方式,雖然現實生活上你不會這麼搞
下面的封包內容是在同一個 topic 裡,消費者往裡面送了三種壓縮方式,分別是 Gzip, ZSTD, None
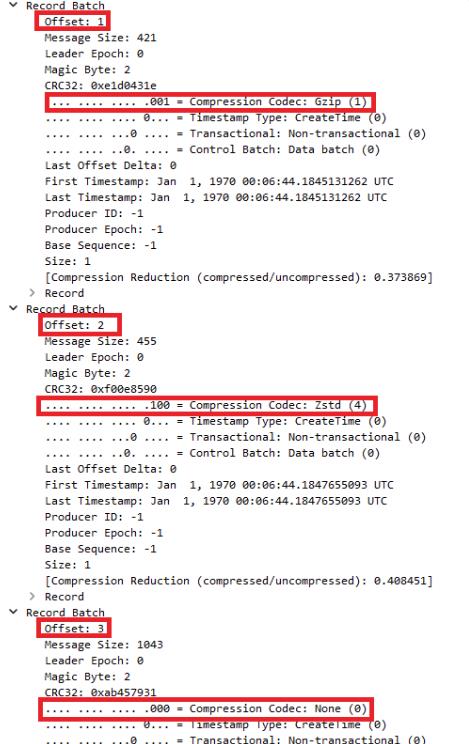
在消費者端也是完全沒問題可以進行消費跟處理的,不需進行任何調整
這個設計真的是非常的有趣
然而 kafka 為了做這樣的設計,在存入的檔案應當是有特別存入壓縮的方式
下面就來看看實體檔案是長成什麼樣子
實體檔案
若是 compression type 是 None 的形式,在 kafka 寫到硬碟的檔案會是明碼的,有些無法顯示的字元應該就是 kafka 自己的處理資料

若是有設定 compression type 為 ZSTD,則檔案內容會是全然不同的

結論
以壓縮設定而言,只要生產者設定即可,消費者完全不需要修改;若是之後想針對壓縮方式修改,也不影響舊有的資料,具有高度彈性與兼容性,又能增加傳輸上的效率,其實是個非常完全的設計
對於處理方式有興趣的人可以參考 confluent-kafka github

最後發現其實該套件的底層處理是使用他們自家的 c++ 套件來做引用,所以如果有想看 壓縮/解壓縮 過程的人得去參考 c++ project
對 topic 直接設定壓縮方式
如果有安裝了對 kafka 的 GUI 管理套件 (ex: CMAK)
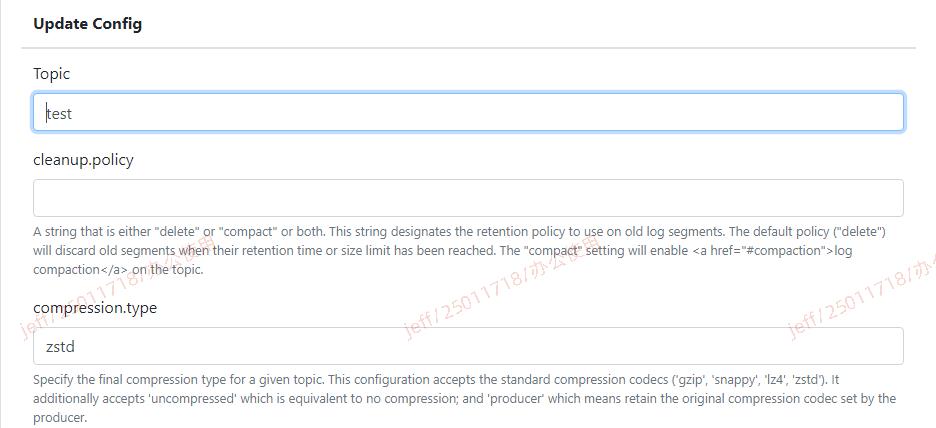

如果對 topic 直接設定為 ZSTD 會發生什麼事
裡面的資料不管生產者怎麼設定 Gzip 或是 LZ4,進到 kafka 裡都會直接被轉成 ZSTD (但這應該會對 kafka server 造成負擔)
如果去觀察生產的的封包的話,也會發現資料都是 ZSTD 的格式回傳
這也是相當有趣的一環設計