人工智慧在媒體推波助瀾的宣傳下,社會大眾起初是驚呼地去理解,這將是一個改變人類的工作與生活型態的新科技突破,但是在深入了解後,又覺得AI只是一個能做到單手無敵的新科技(例如下圍棋),要取代雙手萬能的人類還是很遙遠,尤其是在創作與創新上面。但隨著新的演算法與應用不斷地推陳出新,本文將會介紹GAN如何應用在模仿,甚至是創新與創作的應用…

前言:
即使在深度學習愈來愈普及的現在,人工智慧應該是更加地強大與廣泛地被應用,把資料轉換成數字丟到類神經網路去硬Train一波,就能有不錯的結果。但基礎於人工智慧的原理是以已知去預測未知,還是需要大量的資料,而且還有超過85%以上佔比都是監督式學習。此外,國際上對於個人隱私的尊重,例如GDPR 在世界上罰鍰不斷地創新高,許多人都憂心於未來的訓練資料要合法取得,將會是一大挑戰,甚少成本會被墊高許多。再者人類在學習的歷程上,最開始就是透過模仿在累積經驗與知識的,所以GAN (Generative Adversarial Network,生成對抗網路)這種非監督學習的演算法,就是在圖片生成的需求上,所應運而生。
然而,GAN 除了用於訓練資料不足的情境之外,也常用於生成幾可亂真的圖片,例如生成出微妙微肖 FB創辦人的 Deepfake app。有興趣者可以參考這一篇報導。接下來,這個方法還被用於生成影片、三維物體模型…等應用。
雖然,GAN 原先是屬於非監督學習的一支演算法,但是後進者,也不斷地致力於新的監督學習、半監督學習、強化學習相關地有趣新應用,以下我們將會跑一段Vallina GAN的程式,並且示範怎麼使用 Microsoft GAN Studio不需寫程式就能生成圖像,來滿足不同需求的你。
緣由:
在2014年時 Ian Goodfellow (曾經任職Google,後來被挖角到Apple) 就透過設計二個互相對奕的神經網路 DNN,並取名為生成對抗網路,來實現圖片生成的任務。
在2016年時,記者採訪了來參加研討會的 AI大師Yann LeCun,對於這個技術他的回答是:GANs as the coolest idea in machine learning in the last twenty years. 換句話,這個有創意的演算法設計已經得到了類神經網路大師的認可…
定義:
隨著深度學習技術掘起,電腦便不斷地百尺竿頭地,將物件辨識這類的機器視覺題目發揮地很好,甚至在2015時,機器視覺已經在物理上完全超越我們的靈魂之窗眼睛了。在接下來的時間,人類繼續嚐試讓電腦可以挑戰其他議題,一開始,許多批評者認為,即使深度學習能夠用海量資料的已知學習來實現未知的預測,但是創造新的事物這種,沒有已知可以學習的任務,電腦是不可能完成的。直到人類透過 GAN 這一個神經網路的分支,開始賦予電腦類似於想像力的能力,並且在實務上,已經開始在圖像、影片、音樂、戲劇…等領域注入新的應用。但它是怎麼做到的呢?
原來它是由一個生成網路Generator (你可以想像成一台偽鈔製造機),與一個判別網路 Discriminator (你可以想像成造幣局的稽核主管) 所組成。生成網路會需要一個 latent space中的隨機取樣作為輸入(有點像是種子),透過學習來輸出一個儘可以模仿真實樣本(或稱為答案)的結果 (你可以想像成要印出類似真鈔的假鈔)。至於判別網路的輸入則為真實樣本或生成網路的輸出,其目的是要判別由生成網絡的輸出與真實樣本的差距有多少?而生成網路則要盡可能地欺騙判別網絡。兩個網絡相互對抗、不斷調整參數,最終目的是能在非人工介入情境下,完成指定的圖片生成任務。
發展:
有趣的是從下圖來看,由於早期大家都認為 AI欠缺了想像力,所以當學界/業界火力全開在這塊未開發的處女地,這個領域的研究真的成長的太快了!光是 A~Z的符號已經無法滿足各種新的生成對抗網路的識別需求了,甚至已經多到開起動物園了 the GAN zoo。以下我將舉幾個我比較熟悉的經典演算法來介紹~
 從 Ian Goodfellow 所發展的第一版 GAN,到加入 CNN 以產生更高解析度的 DCGAN、再到可以控制條件生成的 CGAN,最早還卡在 Loss function 抑制錯誤方法(例如由KL改成JS divergence)的發展,所以的圖片生成還處於比較粗放階段;接著,又出現了能轉換馬與斑馬紋路或是風格轉換的 CycleGAN,以及 Pix2Pix (下圖中這種導航地圖與衛星地圖成對的圖像生成技術) 這類 Conditional Adversarial Network 才開啟了更細緻的圖片內細節生成階段;甚至是 PizzaGAN 這種圖層式應用,讓圖像生成的過程可以加入更大彈性的客製化;最後是 Google巨擘也透過硬體TPU、self attention 的 SAGAN 與 DeepMind團隊所開發出來效果逼真清晰的 BigGAN家族 (其top1的正確性已經來到了61.3%) 來加入戰局;或是 GPU大廠 Nvidia 所推出的更高解析度的 Style GAN,除了把圖像生成的解析度提升至 1024*1024的更高程度之外,也將所需的運算推升至全新的境界。如果不用上 8張 GPU 就會跟十年前跑個深度學習(當成3層就算很深了) 需要等個1~2個月,這樣的曠日費時。
從 Ian Goodfellow 所發展的第一版 GAN,到加入 CNN 以產生更高解析度的 DCGAN、再到可以控制條件生成的 CGAN,最早還卡在 Loss function 抑制錯誤方法(例如由KL改成JS divergence)的發展,所以的圖片生成還處於比較粗放階段;接著,又出現了能轉換馬與斑馬紋路或是風格轉換的 CycleGAN,以及 Pix2Pix (下圖中這種導航地圖與衛星地圖成對的圖像生成技術) 這類 Conditional Adversarial Network 才開啟了更細緻的圖片內細節生成階段;甚至是 PizzaGAN 這種圖層式應用,讓圖像生成的過程可以加入更大彈性的客製化;最後是 Google巨擘也透過硬體TPU、self attention 的 SAGAN 與 DeepMind團隊所開發出來效果逼真清晰的 BigGAN家族 (其top1的正確性已經來到了61.3%) 來加入戰局;或是 GPU大廠 Nvidia 所推出的更高解析度的 Style GAN,除了把圖像生成的解析度提升至 1024*1024的更高程度之外,也將所需的運算推升至全新的境界。如果不用上 8張 GPU 就會跟十年前跑個深度學習(當成3層就算很深了) 需要等個1~2個月,這樣的曠日費時。
小結一下,從2014的初聲試啼,然後百家爭鳴,到科技大廠的投入。讓電腦進行圖像生成,已經發展成看你願意投入多少資源,來決定你會得到什麼結果的一項任務了。
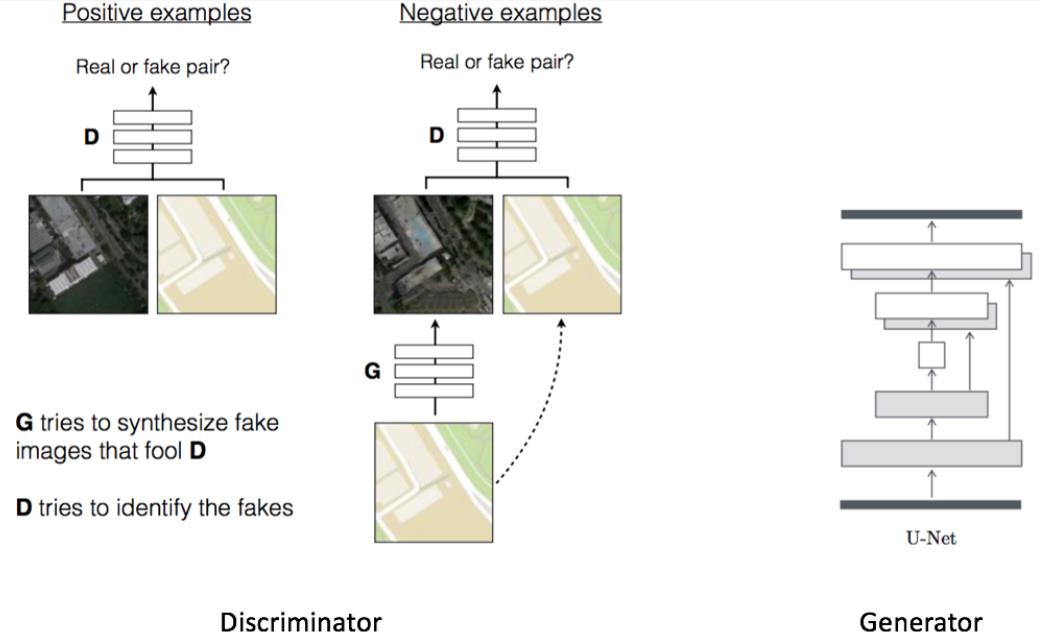
挑戰:
- 新的演算法:剛才我們提到了GAN 的動物園,再加上深度學習是目前的顯學,所以新的模型設計、新的 Loss function或是其他的模型優化細節,將來不斷地接踵而至。為了趕上技術的更新,沒有別的方法,你必需養成定期瀏覽相關資訊的習慣
- 仍有不可遇期的結果:就像是訓練 DNN 神經網路一樣,會有錯誤率壓不下來,或是發生 over fitting的問題。因為訓練 GAN 的時間比較長,你的某一個參數可能要過個十天半個月才能知道結果;或是發生了 loss function 的梯度不穩定、Mode collapse (應該要學會二個峰值的分佈,結果卻不如遇期只學會一個峰值),造成後面的訓練都是浪費時間。總之就是時間愈拉長,風險就愈高
- 不易評估結果:雖然圖像要評估二張圖像的相似程度並不困難,但是 GAN 是把 laten space (模型的參數初始值) 加上經過抽樣的 real data 資料分佈當成輸入,然後分別讓 generator 與 disciminator 學會這些資料分佈。也由於要讓二個資料分佈要儘可能的出現交集甚至是重疊並不容易,想像一下你拿著一個能穿越時空的對講機,一頭是站在現代台灣版塊的人;一頭是站在一億年前版塊尚未分裂的台灣上另一個生物,你透過對講機要讓他們對齊,談何容易?這裡面有一堆高維 minifold、相對空間/位置…的複雜數學要計算。除了 loss function 目前評估的方法,主流是以 inception score或是 Frechet Inception Distance (簡單FID)。然而 google 之前投入大量的資源做出的 Big GAN也只能達到 61.3 %,至於 Nvida 也是覺得與其投入大量的 RD資源去解決學術上所在意的因子 (模型梯度的穩定、更小的 loss、抑制Mode collapse…) 讓分數提高,還不如想辦法把精細度提高以及增加更多可供使用者可以控制的變化在圖像生成上,更能增加 GPU的銷售,所以還真的是不容易啊!
- 運算能力爆增:隨著應用場景愈來愈廣,以及 AI落地(例如應用8K的電視上),大家對於圖像與影片的解析度將會愈加苛求,GPU的資源。以StyleGAN1來說要生成256*256的圖像,使用一張Tesla V100的GPU就會需要358小時,當我們把解析度提高到1024*1024時間就來到988小時。在這個新的生成競賽中,如果你沒有銀彈的支援,是很難把時間成本控制的好
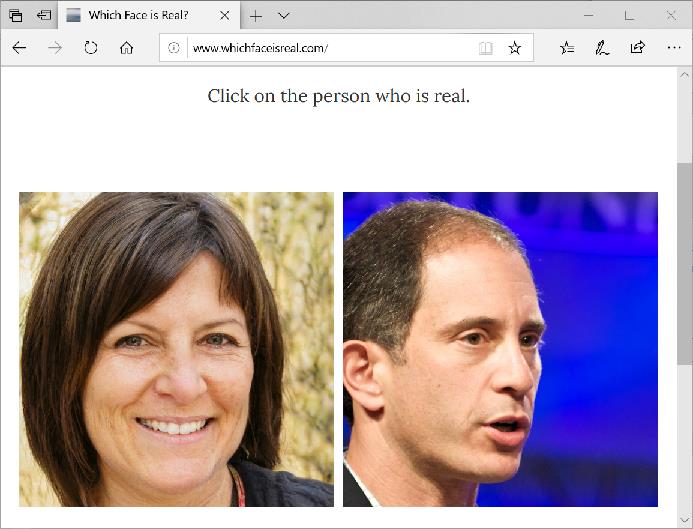
- 不當的應用:由於生成的圖像與影片愈來愈能以假亂真,所以它已經成功地被應用在開玩笑的明星不雅合成照、想要吸引他人注意力的裸女轉換器、政客想藉由移花接木的操作散佈不實的言論、詐騙集團的犯罪應用…只要有陰暗處與地下的交易,將會成為犯罪的溫床與治安上的死角。因此每個人將來都要提升自己在真假圖像的辦識能力上,例如來這個網站練功
- 資訊安全的風險:基礎於人類愈來愈倚重 AI,新的犯罪手法也開始從 AI的流程中開花結果。惡意者在分析某一個 AI的運作後,輕則,會刻意影響結果的準確性;中則是在模型更新時(或是其他環節)中插入惡意程式;重則是透過 AI的存取權限去入侵企業的重要系統,進而造成更大的損失。
應用:
隨著科技的發展,各種類型的應用將會不斷地被產生,例如遊戲業用在新的關卡與背景的自動生成上、Facebook的 Neural Face人臉自動生成上、自動生成人產品文宣(DM)或是唱片封面、能有狸貓換太子(將馬變成班馬)效果的 Cycle GAN、圖像流形生成(能把素描的簡單筆觸生成為完整圖像)、將文字生成為圖像、能預測2秒後的影片生成…
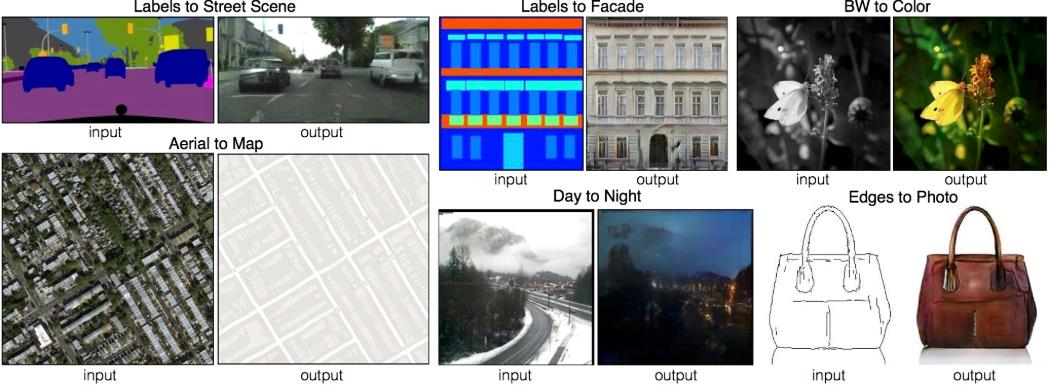 上圖是,以 Pix2pix為例,它可以用在街景的圖像生成、建築物的細節圖像生成、灰階至彩色圖像的生成、衛星至地圖的圖像生成、日間轉夜間的圖像生成、皮包的邊界轉細節圖像的生成…
上圖是,以 Pix2pix為例,它可以用在街景的圖像生成、建築物的細節圖像生成、灰階至彩色圖像的生成、衛星至地圖的圖像生成、日間轉夜間的圖像生成、皮包的邊界轉細節圖像的生成…
示範:
以下將示範 Microsoft與 MIT所合作的 GAN studio,首先先透過瀏覽器連上 https://gen.studio/
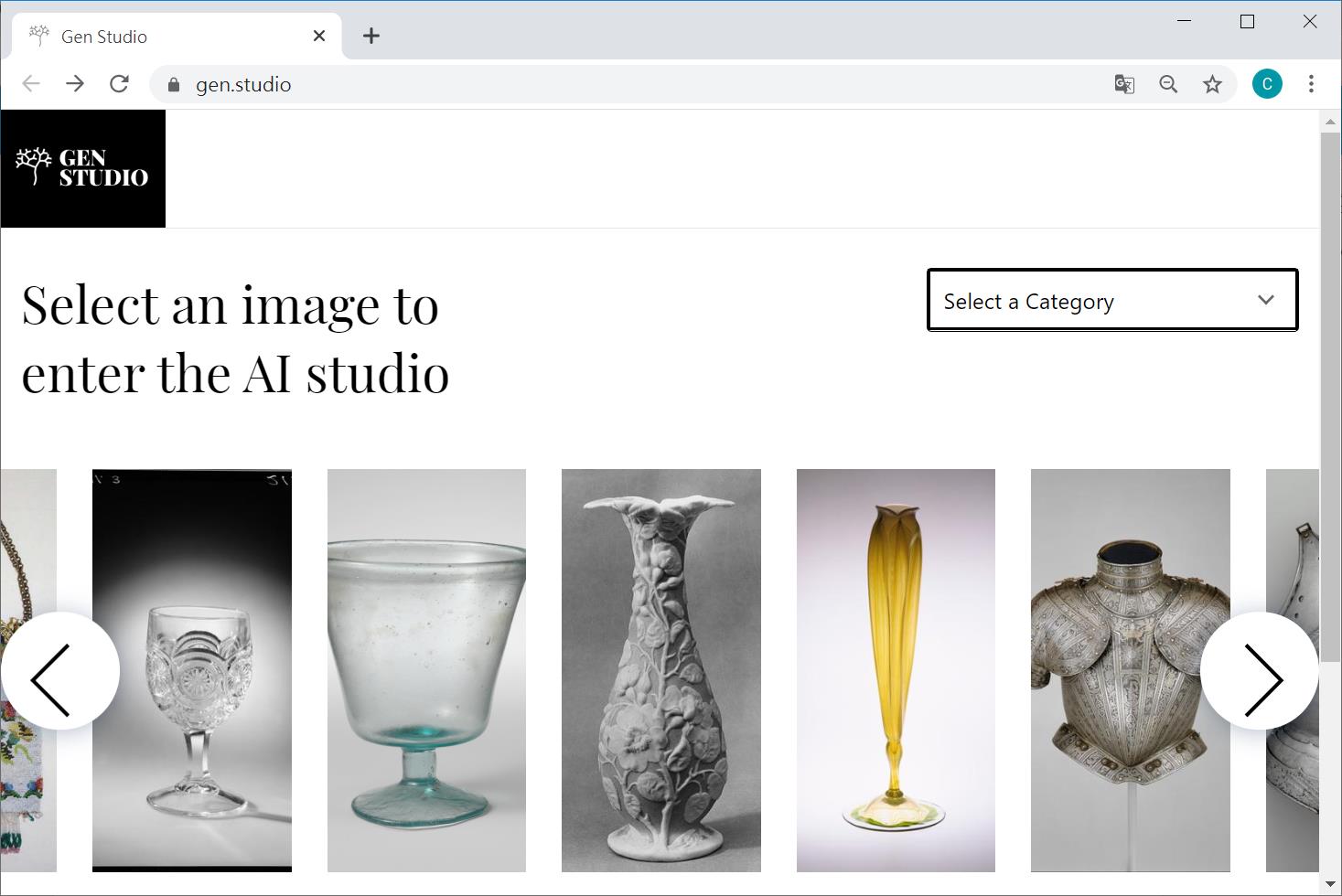 接著選擇有興趣的類別,例如盔甲、水壺、水杯、包包、花瓶。假設我選了花瓶類別,再利用左右去挑出喜好的單品,再按下左下方的產生鍵
接著選擇有興趣的類別,例如盔甲、水壺、水杯、包包、花瓶。假設我選了花瓶類別,再利用左右去挑出喜好的單品,再按下左下方的產生鍵
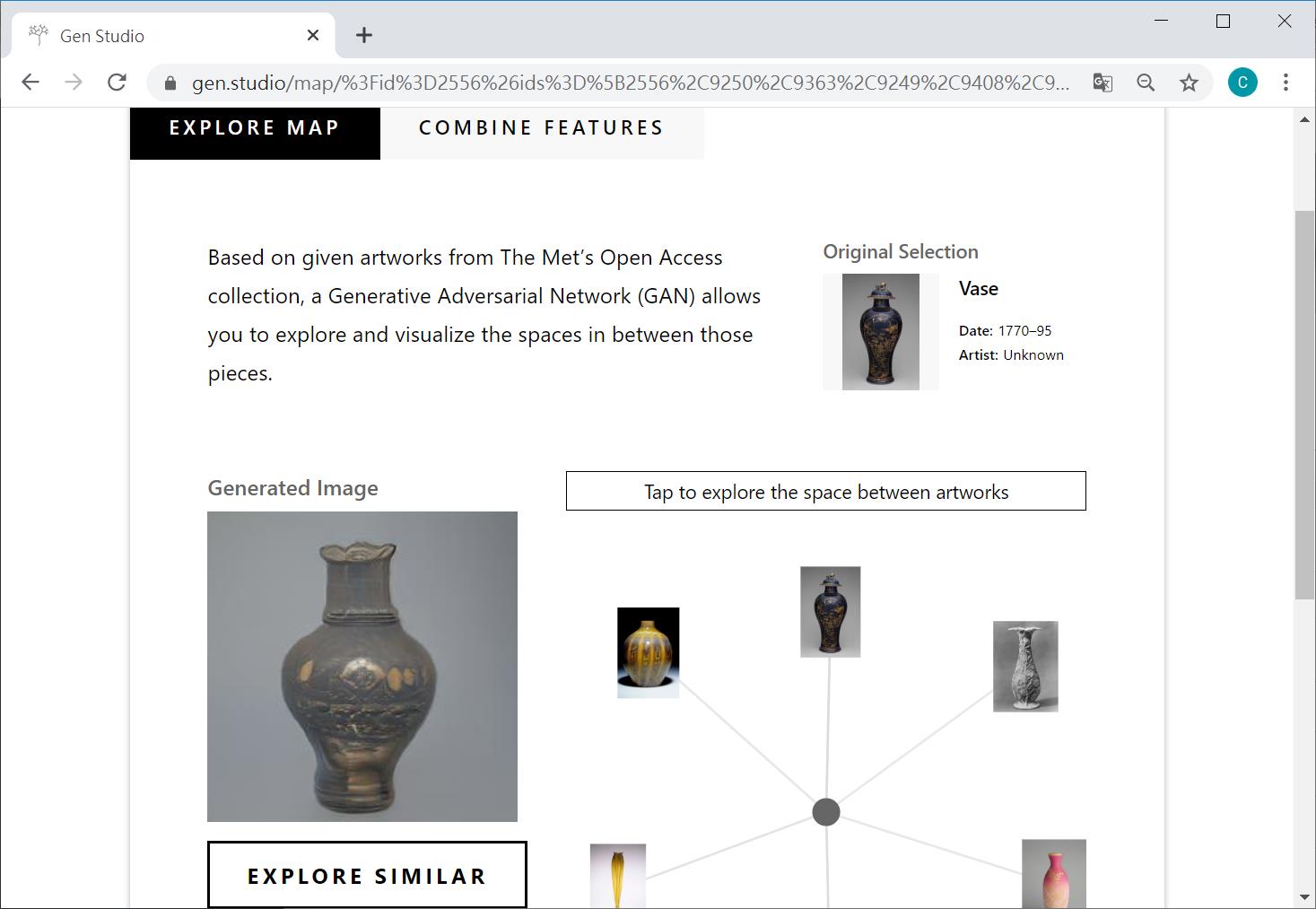
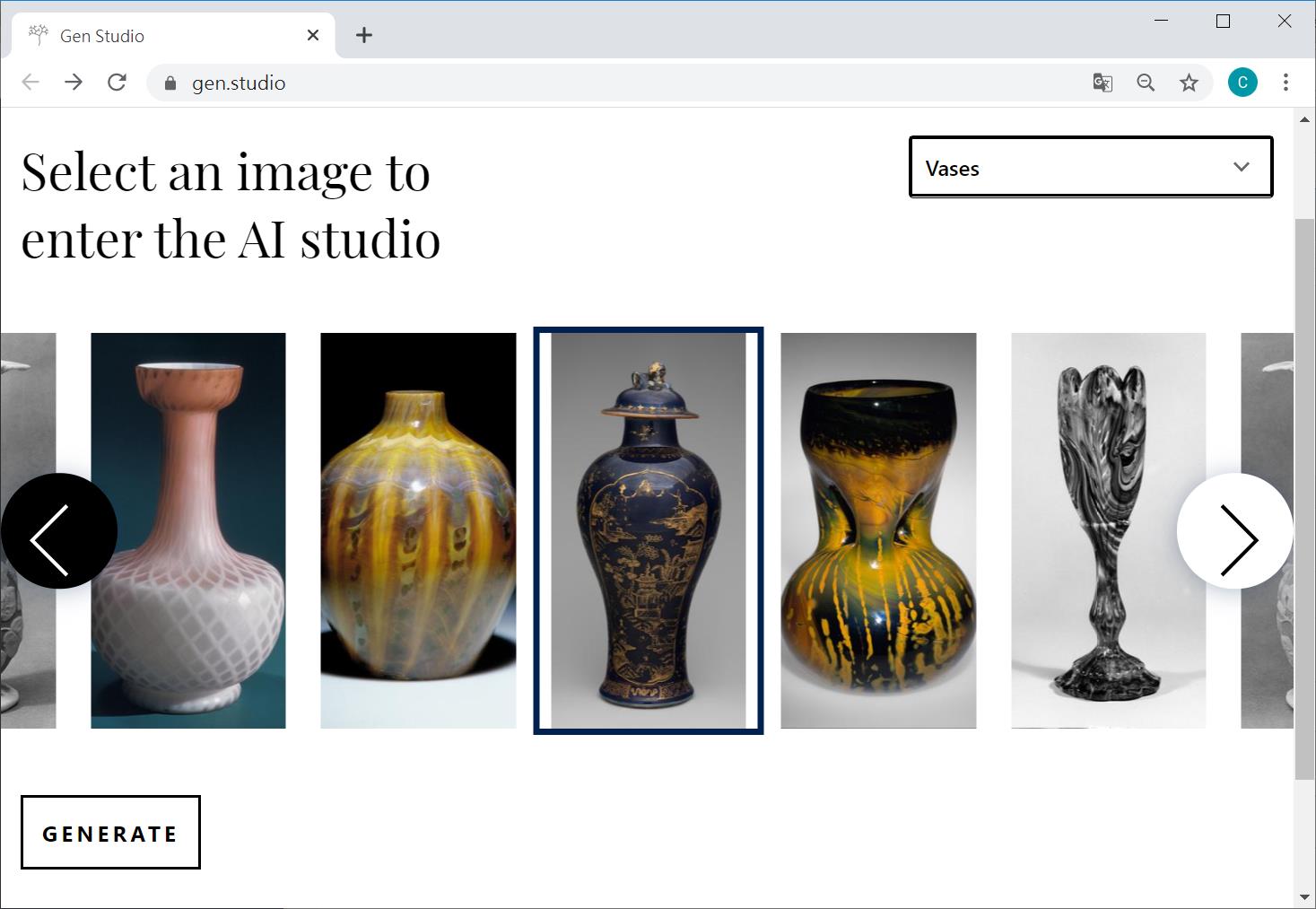 在Explore map中,畫面中的左下角已經呈現出基礎於六張圖像所產生的圖像,在儲存這張圖像之前,你可以先切到 Combine features去增減這六張的各自權重
在Explore map中,畫面中的左下角已經呈現出基礎於六張圖像所產生的圖像,在儲存這張圖像之前,你可以先切到 Combine features去增減這六張的各自權重
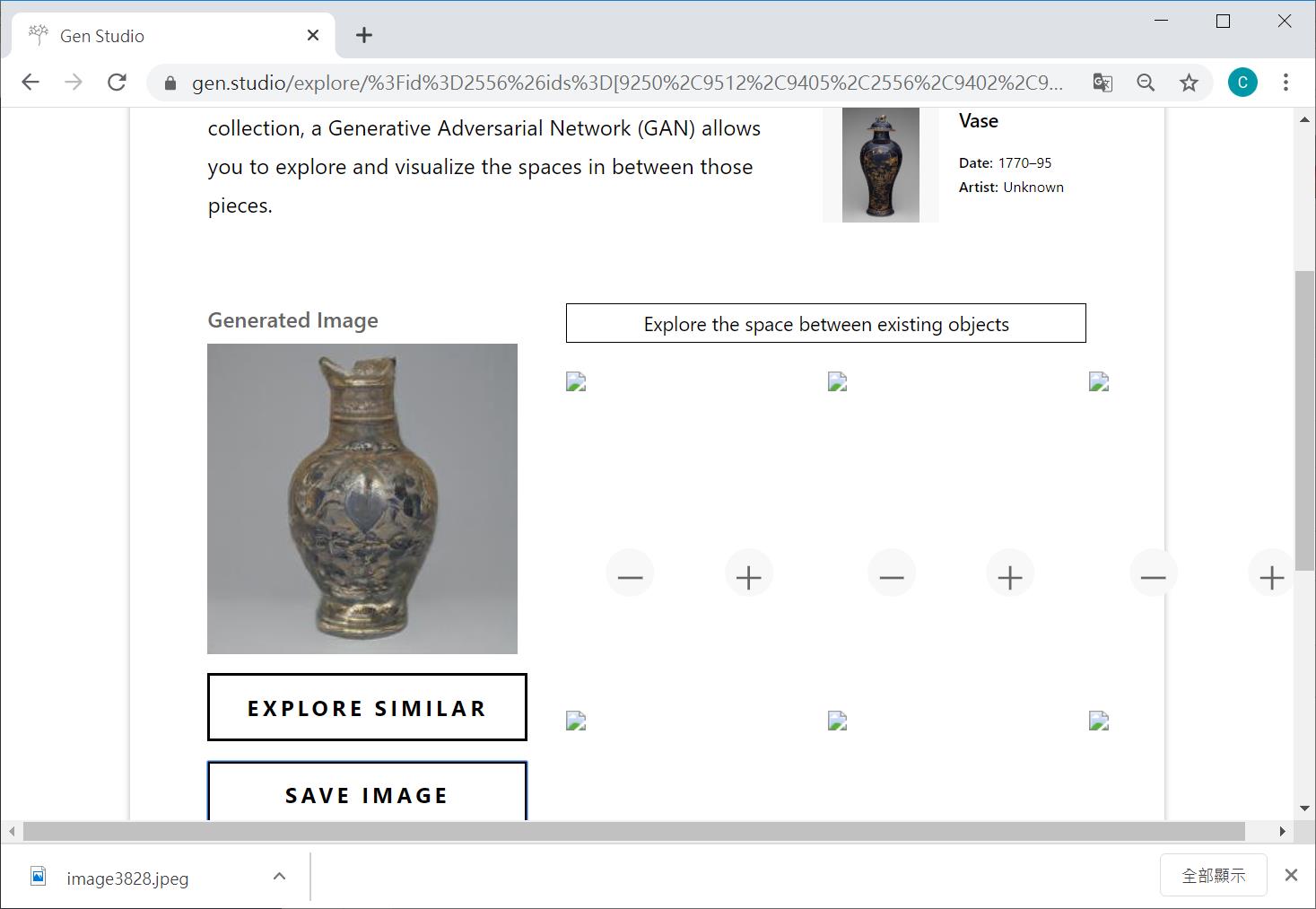
 你可以看到下圖,就是經過我增減不同的權重之後,所產生獨一無二的古代花瓶,當我按下Save image時,就可以將這個 256*256的創作儲存至我的硬碟,甚至進一步的分享給朋友
你可以看到下圖,就是經過我增減不同的權重之後,所產生獨一無二的古代花瓶,當我按下Save image時,就可以將這個 256*256的創作儲存至我的硬碟,甚至進一步的分享給朋友
 成果
成果

技術實作:
以下將示範,如果以MNIST資料集,來生成 0~9的數字(解析度為28*28)
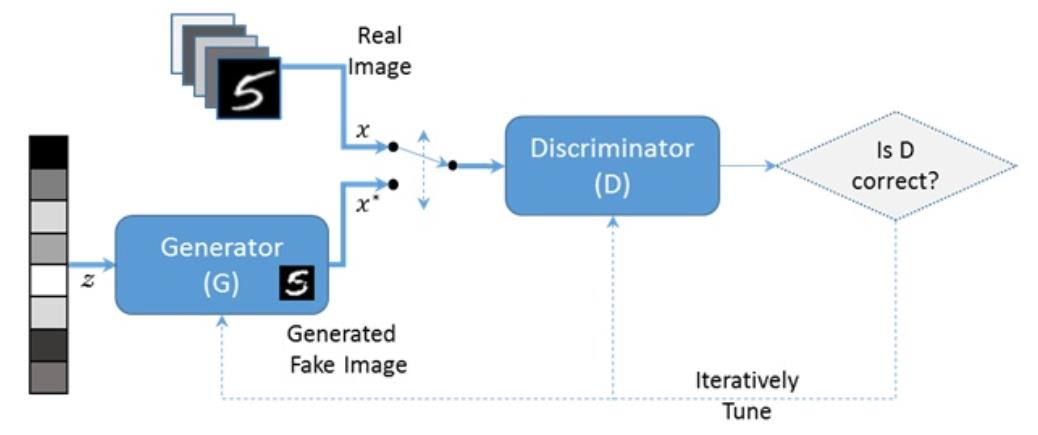 Generator 與 Discriminator 實作
Generator 與 Discriminator 實作
class Generator(Model):
def __init__(self, z_dim):
super(Generator, self).__init__()
self.model = Sequential()
# [z_dim] => [7, 7, 128]
self.model.add(Dense(7 * 7 * 128, use_bias=False, input_shape=(z_dim,)))
self.model.add(LeakyReLU())
self.model.add(Reshape((7, 7, 128)))
# [7, 7, 128] => [14, 14, 64]
self.model.add(Conv2DTranspose(64, 5, strides=2, padding='same'))
self.model.add(LeakyReLU())
# [14, 14, 64] => [28, 28, 1]
self.model.add(Conv2DTranspose(1, 5, strides=2, padding='same', activation='tanh'))
def call(self, x):
return self.model(x)
class Discriminator(Model):
def __init__(self):
super(Discriminator, self).__init__()
self.model = Sequential()
# [28, 28, 1] => [14, 14, 64]
self.model.add(Conv2D(64, 5, strides=2, padding='same', input_shape=(28, 28, 1)))
self.model.add(LeakyReLU())
# [14, 14, 64] => [7, 7, 128]
self.model.add(Conv2D(128, 5, strides=2, padding='same'))
self.model.add(LeakyReLU())
# [7, 7, 128] => [4, 4, 256]
self.model.add(Conv2D(256, 5, strides=2, padding='same'))
self.model.add(LeakyReLU())
# [4, 4, 256] => [1]
self.model.add(Flatten())
self.model.add(Dense(1))
def call(self, x):
return self.model
def gan_loss(d_real_logits, d_fake_logits):
# d_real_logits 為 discriminator 看了真實資料的 output,
# d_fake_logits 為 discriminator 看了 generator 製造的假資料的 output
# 定義 cross entropy 作為衡量標準,from_logits 是指要將 input 作 sigmoid 處理
cross_entropy = BinaryCrossentropy(from_logits=True)
# discriminator loss
d_loss_real = cross_entropy(tf.ones_like(d_real_logits), d_real_logits)
d_loss_fake = cross_entropy(tf.zeros_like(d_fake_logits), d_fake_logits)
d_loss = d_loss_real + d_loss_fake
# generator loss
g_loss = cross_entropy(tf.ones_like(d_fake_logits), d_fake_logits)
return d_loss, g_loss
剛開始是慘不忍睹!==> 完全看不出是數字,但必需要有耐心!

模型訓練
generator = Generator(z_dim)
discriminator = Discriminator()
g_optimizer = Adam(learning_rate)
d_optimizer = Adam(learning_rate)
@tf.function
def train_step(real_images, generator, discriminator, g_optimizer, d_optimizer):
noise = tf.random.normal([BATCH_SIZE, z_dim])
with tf.GradientTape() as g_tape, tf.GradientTape() as d_tape:
fake_images = generator(noise)
d_real_logits = discriminator(real_images)
d_fake_logits = discriminator(fake_images)
d_loss, g_loss = gan_loss(d_real_logits, d_fake_logits)
g_gradients = g_tape.gradient(g_loss, generator.trainable_variables)
d_gradients = d_tape.gradient(d_loss, discriminator.trainable_variables)
g_optimizer.apply_gradients(zip(g_gradients, generator.trainable_variables))
d_optimizer.apply_gradients(zip(d_gradients, discriminator.trainable_variables))
return d_loss, g_loss
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
for image_batch in dataset:
d_loss, g_loss = train_step(image_batch, generator, discriminator,
g_optimizer, d_optimizer)
# 產生圖片
print('Time for epoch {} is {} sec'.format(epoch + 1, time.time() - start))
print('discriminator loss: %.5f' % d_loss)
print('generator loss: %.5f' % g_loss)
generate_and_save_images(generator, epoch + 1, seed, save_dir)
# 每 25 個 epochs 存一次模型
if (epoch + 1) % 25 == 0:
checkpoint.save(file_prefix=checkpoint_prefix)
# 在最後一個 epoch 再產生一次圖片與儲存一次權重
generate_and_save_images(generator, epochs, seed, save_dir)
checkpoint.save(file_prefix=checkpoint_prefix)
%%time
train(train_dataset, EPOCHS)

在一顆 GPU的條件下,經過了一小時 200個 Epoches的圖像生成,我們發現看似簡單低解析度的0~9數字,其實在筆劃比較複雜的數字5跟8上,還是存在著圖像生成中先天上的技術門檻需要被克服。
接下來我們嚐試使用透過 Weight clipping 類型的優化方式,再戰200個 Epoches (比原來的一個小時更久)。
平心而論,這是一個同時往天秤二端拉扯的方法。雖然它的效果可以讓 Discriminator 變得比較平滑來接近 1-Lipschitz function,然後在DNN的隱藏層各層之間,將會出現梯度爆炸與消失, 所以結果會很靠運氣。
 感覺上數字的曲折度有增加,但對於數字5、8的生成還是不行!
感覺上數字的曲折度有增加,但對於數字5、8的生成還是不行!
最後我們用 Gradient penalty 來取代 Weight clipping 嚐試再繼續優化它,繼戰 200個 Epoches(比原來的一個小時更久)
 發現數字5與8部份有了好轉,但效果還是不能有一致的水準!
發現數字5與8部份有了好轉,但效果還是不能有一致的水準!
結論:
在2018年10月25日,一幅名為Edmond de Belamy的AI 藝術畫作在佳士得拍賣會最終以美金43萬2000成交,一舉打破了AI藝術品的世界記錄。這還只是GAN 圖像生成 La Famille de Belamy家族的一員而已,另外還有待價成沽的白爵、男爵、主教…等10個成員。
雖然這則AI 藝術創作的新聞,可能會引領絕大部份的人,現代的AI 科技已能生產出高品質且高價的新氣象。在我來看,原本不帶一絲情感的AI 創作,卻因為人類主觀地對作品進行欣賞、審美、鑑價…等動作上,自行附加了一些意義,而讓它有了不同的結果。
綜合來看, 大部份 AI 所產生各種藝術作品(包含了畫作、劇本、音樂…等),在本質上藝術的水準與品質與 state of the art 的藝術家其實還有一段距離,而且只要你留心都能發現有一點點地小瑕疪。
另外,從工藝的角度來看,在藝術創作上,其中的架構設計與工藝技巧是佔著相當大的比重,沒有捷徑,只能亦步亦趨地地投入時間與精力,才能磨練出日趨成熟的技術水準。然後讓人望而卻步的藝術養成門檻,竟然剛好是類神經網路所擅長的而且能發揮的。也就是說,我們可以透過深度學會來萃取隱藏在圖片、音域、語言、空間、故事…這些藝術作品背後的統計結構,並且用數學來描述他們(求得 target function)。接著我們再仔細深究這些接近工匠等級的工藝技術成品,還是缺乏了主動性,類似AI 它可以寫出給定主題的作文,但是當老師說今天自由發揮時,它卻不曉得該從何開始?
基礎於演算法的本質是用已知(訓練資料)去預測未知,所以它並沒辦法體會人類的生活、情感寄託,以及對週遭世界的感知,它只能完成我們所指定的主題去工作,然後儘可能地發揮它所學過的工藝技術。所以AI 的核心價值,並不是要取代畫家、編劇家、作曲家,而是要協助他們能夠更省時省力而且聰明的工作。
希望在不久地將來,能看到更多膾炙人口且令人耳目一新的 AI夢幻逸品,出現在我們的生活周邊…
李秉錡 Christian Lee
Once worked at Microsoft Taiwan