基於大數據議題越來越火熱,而數據取得變得非常重要,如果使用企業提供資料就不用煩惱這問題,
但像我預測各大運動賽事賽果,網路上都可以取得,而且是非常詳細之數據(重點是幫公司省錢阿) 。
因此這系列文章會介紹大家如果使用python來爬取網站,也會直接拿實例作示範。
開始前,先灌輸給大家一些爬網的觀念
- 當有禮貌的爬蟲家, 不要傳送密集大量的請求以免造成伺服器壓力過大。
- 如上述,當我對此網站有大量需求,本身會設定time.sleep間隔。
- 只抓取網站需求資料,而並非為了方便全部抓取,要的是深度而非廣度。
- 你所寫得爬蟲程式碼,並非能一直作業,一旦網站調整網頁結構,就需要調整。
#事前準備
- python2.7
- package:BeautifulSoup
- 爬取網站:http://www.basketball-reference.com/boxscores/201611230BRK.html
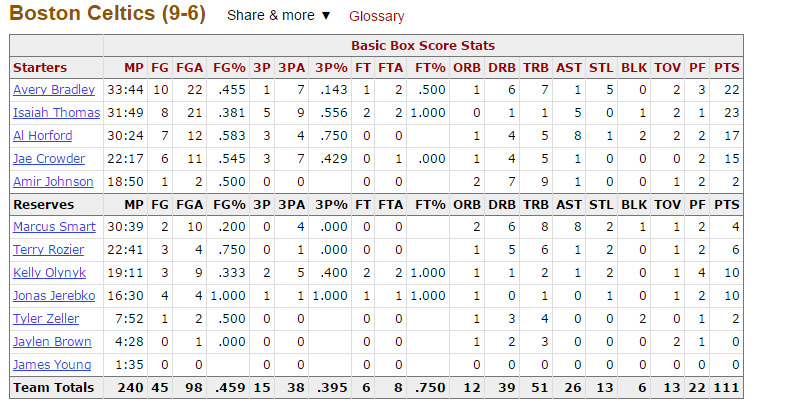
- 爬取內容:如下圖
#程式碼
import cx_Oracle
import requests
from bs4 import BeautifulSoup
NBA_url='http://www.basketball-reference.com/boxscores/201611230BRK.html'
res=requests.get(NBA_url)
soup=BeautifulSoup(res.text)
#print soup
#step1
Bos_Basic=soup.findAll('div',{'id':'all_box_bos_basic'})[0].findAll('tbody')
print Bos_Basic
Step1解說:
1.res=requests.get(NBA_url)
- 選取你要爬取網頁,透過HTTP協定中的get方法送出一個請求(Request)到遠端的伺服器(Server),伺服器接受請求後,就會回應(Response)並回傳網頁內容(原始碼)的檔案回來
2.soup=BeautifulSoup(res.text)
- 我們將內容(原始碼)套入BeautifulSoup方法,已利於我們做Regular expression來判斷與過濾
- 你可以print出來看看裡面的架構,他就是網頁所有的內容(這邊我先注解掉了)
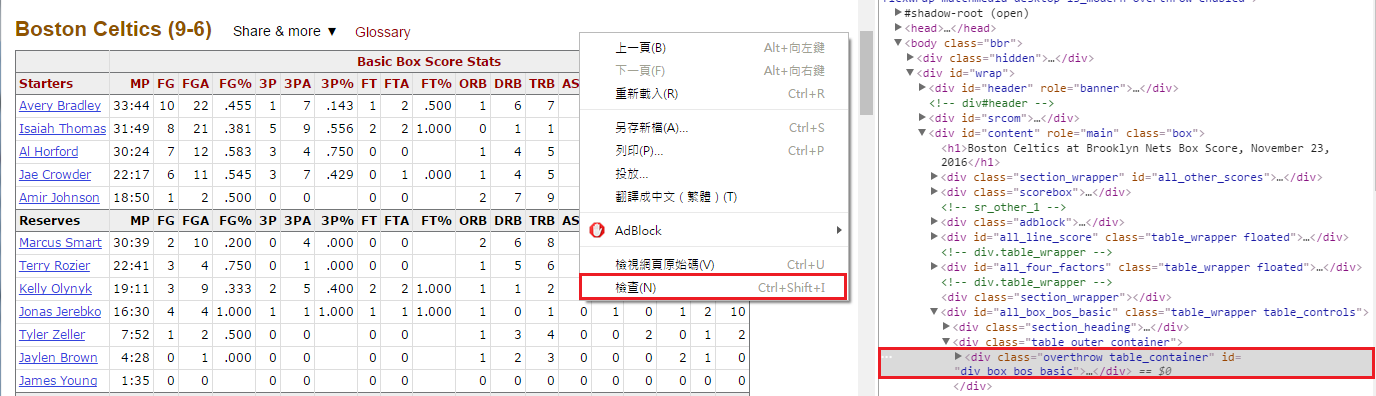
3.這網頁的表格這麼多,我只要爬取我想要的表格,就必須要知道這表格的原始碼在哪一段,如下圖1
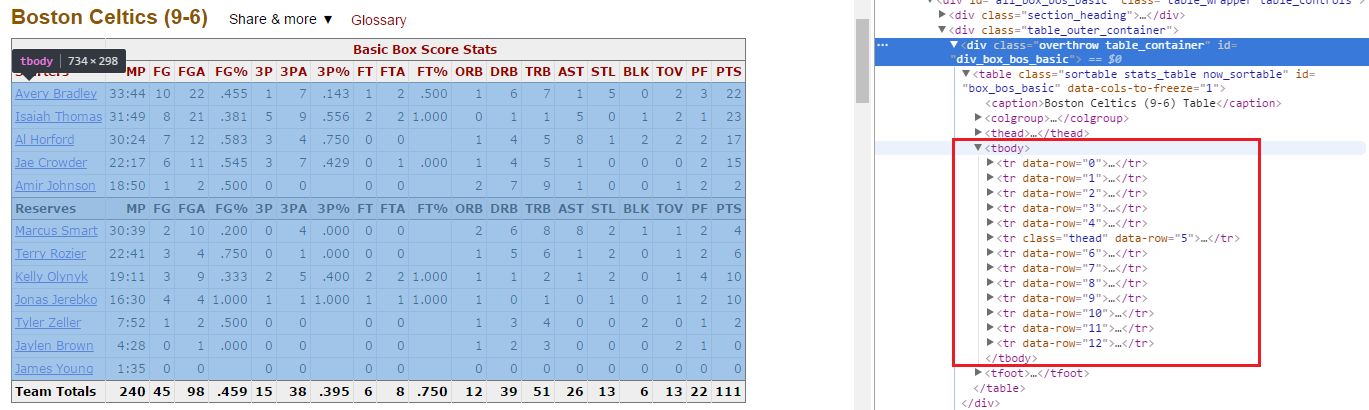
4.從圖1得知id=all_box_bos_basic,圖2得知整個資料都放在tbody架構裡,利用findAll方法,我們把這些資料抓出來,一樣可以pinrt出來看一下內容(這邊就不展示了)
#step2
NBA_data=[]
Play_stat_row=Bos_Basic[0].findAll('tr')
for i in range(0,len(Play_stat_row)):
if i==5:
pass
else:
print Play_stat_row[i].text
Step2解說:
1.上一步驟你抓出來的只事表格架構原始碼,那接下來就是把你想要的數據資料給抓出來了
2.Play_stat_row這邊我需要知道這張表的ROW的長度(也就是幾列,從上圖看會比較清楚)
3.用for迴圈把整個資料給印出來,這邊有設條件限制是因為表中間那一行沒數字的我不要
Output:
Avery Bradley33:441022.45517.14312.5001671502322 Isaiah Thomas31:49821.38159.556221.0000115012123 Al Horford30:24712.58334.750001458122217 Jae Crowder22:17611.54537.42901.0001451000215 Amir Johnson18:5012.5000000279100122 Marcus Smart30:39210.20004.00000268821124 Terry Rozier22:4134.75001.00000156120126 Kelly Olynyk19:1139.33325.400221.0001121201410 Jonas Jerebko16:30441.000111.000111.0001010101210 Tyler Zeller7:5212.5000000134002012 Jaylen Brown4:2801.0000000123000210 James Young1:35000000000000000
#step3
NBA_Team_data=[]
for i in range(0,len(Play_stat_row)):
NBA_Player_data=[]
NBA_Player_Stat=Bos_Basic[0].findAll('tr')[i].findAll('td')
NBA_Play_name=Bos_Basic[0].findAll('tr')[i].findAll('th')
for j in range(0,len(Play_stat_col)):
if i==5:
pass
else:
NBA_Player_data.append(NBA_Player_Stat[j].text)
NBA_Player_data.insert(0,NBA_Play_name[0].text)
NBA_Team_data.extend([NBA_Player_data])
print NBA_Team_data
Step3:
1.上一步驟Output結果有沒有發現數字全部都擠在一塊,那是因為你一次取一列整個列出來,並未將每一列再切割成每一欄位
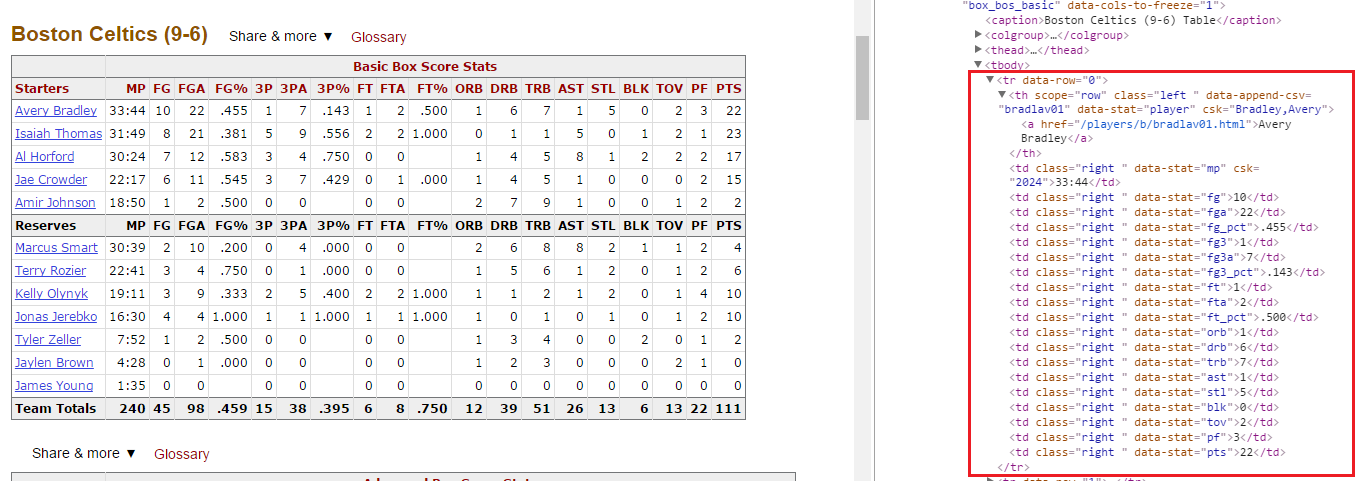
2.從下圖3紅色框部分,我們把tr展開來,可以看到td框架,這就是我們要的欄位 ,並進行動作=>NBA_Player_Stat=Bos_Basic[0].findAll('tr')[i].findAll('td')
3.我們發現球員名稱是在th框架,進行動作=>NBA_Play_name=Bos_Basic[0].findAll('tr')[i].findAll('th')
Output:
[[u'Avery Bradley', u'33:44', u'10', u'22', u'.455', u'1', u'7', u'.143', u'1', u'2', u'.500', u'1', u'6', u'7', u'1', u'5', u'0', u'2', u'3', u'22'], [u'Isaiah Thomas', u'31:49', u'8', u'21', u'.381', u'5', u'9', u'.556', u'2', u'2', u'1.000', u'0', u'1', u'1', u'5', u'0', u'1', u'2', u'1', u'23'], [u'Al Horford', u'30:24', u'7', u'12', u'.583', u'3', u'4', u'.750', u'0', u'0', u'', u'1', u'4', u'5', u'8', u'1', u'2', u'2', u'2', u'17'], [u'Jae Crowder', u'22:17', u'6', u'11', u'.545', u'3', u'7', u'.429', u'0', u'1', u'.000', u'1', u'4', u'5', u'1', u'0', u'0', u'0', u'2', u'15'], [u'Amir Johnson', u'18:50', u'1', u'2', u'.500', u'0', u'0', u'', u'0', u'0', u'', u'2', u'7', u'9', u'1', u'0', u'0', u'1', u'2', u'2'], [u'Marcus Smart', u'30:39', u'2', u'10', u'.200', u'0', u'4', u'.000', u'0', u'0', u'', u'2', u'6', u'8', u'8', u'2', u'1', u'1', u'2', u'4'], [u'Terry Rozier', u'22:41', u'3', u'4', u'.750', u'0', u'1', u'.000', u'0', u'0', u'', u'1', u'5', u'6', u'1', u'2', u'0', u'1', u'2', u'6'], [u'Kelly Olynyk', u'19:11', u'3', u'9', u'.333', u'2', u'5', u'.400', u'2', u'2', u'1.000', u'1', u'1', u'2', u'1', u'2', u'0', u'1', u'4', u'10'], [u'Jonas Jerebko', u'16:30', u'4', u'4', u'1.000', u'1', u'1', u'1.000', u'1', u'1', u'1.000', u'1', u'0', u'1', u'0', u'1', u'0', u'1', u'2', u'10'], [u'Tyler Zeller', u'7:52', u'1', u'2', u'.500', u'0', u'0', u'', u'0', u'0', u'', u'1', u'3', u'4', u'0', u'0', u'2', u'0', u'1', u'2'], [u'Jaylen Brown', u'4:28', u'0', u'1', u'.000', u'0', u'0', u'', u'0', u'0', u'', u'1', u'2', u'3', u'0', u'0', u'0', u'2', u'1', u'0'], [u'James Young', u'1:35', u'0', u'0', u'', u'0', u'0', u'', u'0', u'0', u'', u'0', u'0', u'0', u'0', u'0', u'0', u'0', u'0', u'0']]
自己是希望用簡單的範例,讓大家了解爬蟲的運作原理,part1部分就到這邊,
之後會分享在不同情況下使用不同爬蟲方法,我都會以我爬過網站做分享,
大多都是運動資料,有問題都可以互相交流,謝謝。