Random Forest是一個好理解、實用,很常用來做大量數據的分析之方法,
對於初學者來說是很好上手的一種Machine Mearning方法。
Random Forest顧名思義,是用隨機的方式建立一個森林,森林裡面有很多的決策數(分類器)所組成,
隨機森林的每一棵決策樹之間是沒有關聯的,也就是樹與樹之間是相互獨立的。
(比較白話的意思就是當有一個新的樣本進入的時候,就讓森林中的每一棵決策樹分別進行一下判斷,
看看這個樣本應該屬於哪一類,假設此樣本被每一棵決策樹選擇較多次為A類別,則就會預測這個樣本屬於A類別。)
剛剛說到樹與樹之間是相互獨立的,接下來的問題是如何獲取多個獨立的樹(分類器)呢?
以下兩種方法:
Bagging
這是1996年由Breiman提出(Bagging是Bootstrap aggregating的縮寫)
特性:訓練出有差異性的分類器(Tree)
N:Training data資料數
M:bag數量
K:一個bag資料數量
從訓練資料中取M個樣本,M個樣本訓練出M個分類器(Tree),每次取的K資料數量都會放回訓練資料中,
因此達到每個分類器的差異性,也稱作Bootstrap抽樣。簡單的說,N中取M,M個數=M個Tree,K皆會放回N中。
整個順序 : 隨機取100筆資料訓練出一個分類器 => 將100筆資料放回 => 再隨機取100筆資料訓練第二個分類器,以此類推。
因此每一個分類器彼此間都會有差異性。
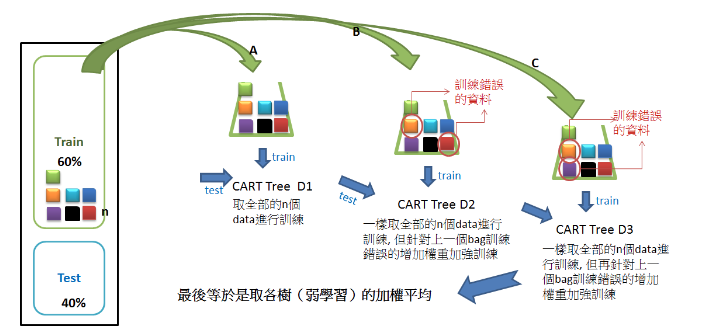
Boosting
特性:將學習力較弱的分類器逐步加強訓練成較強的分類器
對一份訓練資料,建立X個模型, 而每次分類都會將上一次分錯的資料加重權重再進行下一次分類,
這樣最終得到的分類器在測試資料與訓練資料都會有不錯的結果,如下圖。
Random Forest優點
相較於其它的學習模型,隨機森林的優點是:(參考自wikipedia)
- 對於很多種資料,它可以產生高準確度的分類器。
- 它可以處理大量的輸入變數。
- 它可以在決定類別時,評估變數的重要性。
- 在建造森林時,它可以在內部對於一般化後的誤差產生不偏差的估計。
- 它包含一個好方法可以估計遺失的資料,並且,如果有很大一部分的資料遺失,仍可以維持準確度。
- 它提供一個實驗方法,可以去偵測variable interactions。
- 對於不平衡的分類資料集來說,它可以平衡誤差。
- 它計算各例中的親近度,對於數據挖掘、偵測偏離者(outlier)和將資料視覺化非常有用。
- 使用上述。它可被延伸應用在未標記的資料上,這類資料通常是使用非監督式聚類。也可偵測偏離者和觀看資料。
- 學習過程是很快速的。
參考網址:https://kknews.cc/zh-tw/news/brzmvj.html、https://read01.com/QAneJm.html