簡單介紹何謂overfitting,
哪種情況常出現overfitting,
如何去預防overfitting。
overfitting,或稱過度擬合 from wiki
我對overfitting定義為模型在訓練時會很好的結果,但往往在test或是predict的時候效果差。
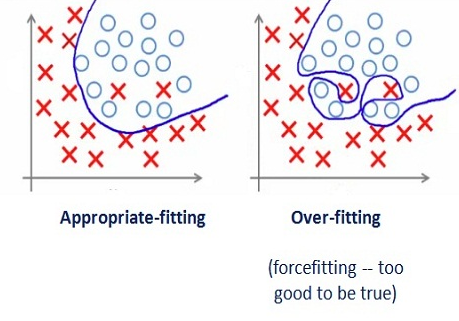
用下圖來看會比較好理解,右邊為overfitting的情況,模型在訓練時找一條完美曲線可以切割X與O,
會不會有人會覺得說這不是很好嗎?這模型很厲害可以完美分類資料!!當然每個人都想訓練出完美模型,
但個人經驗來看,這是無法實現的,尤其在資料大非常龐大的時候,我們只需要追求高準確度(越高越好)而非完美精準度(達到最頂點),
因此左邊的圖才是比較符合標準模型。
避免 overfitting 的方式
1. 降低 features 的數量.
a. 手動選擇要保留或要捨棄哪些 features.
b. 採用 model selection algorithm 決定要保留或要捨棄哪些 features.
這個作法的缺點是, 捨棄 features 的同時, 也捨棄了一些可能有用的資訊.
2. 正規化 (regularization).
保留所有的 features, 但降低 parameters θj 的大小.
這個作法適用於有許多 features, 且每個 features 對於預測 y 都有一點點貢獻.
3.使用資料清洗(Data Cleaning/Pruning),將錯誤的 label 修正,或直接刪除錯誤的數據。
4.製造資料(Data Hinting),當資料很少時,overfitting的情況是很常發生的,因此使用合理的方法將原來手的的資料變得更多是可行的方式,
比如在數字識別的這個問題將已有的數字透過平移、旋轉來製造出更多資料。
5.Cross Validation
以上這5種方式都可以有效去避免掉overfitting,分享一些ML方法是本身方法就可以避免掉overfitting,像是LASSO、Ridge regression、Random Forest、Ensemble Model等等
這些ML在運算過程中都可以有效避免掉overfitting,供各位參考之。