最近專案在對英雄聯盟進行比賽預測,由於用了各種演算法進行測試都得不到好的結果,所以只好搬出大絕招,用super learning來對付!
一.基本概念
Stack又稱super learning,很常玩Kaggle的人對它應該不陌生,其實不用把它想的很複雜,它就是一個三個臭皮匠勝過一位諸葛亮的概念
我們通常分析資料都是用單一模型去進行預測,而Stack就是將多個單一模型組合為一的技術。以下會用我個人理解去簡單的介紹。
二.Stack的運作流程
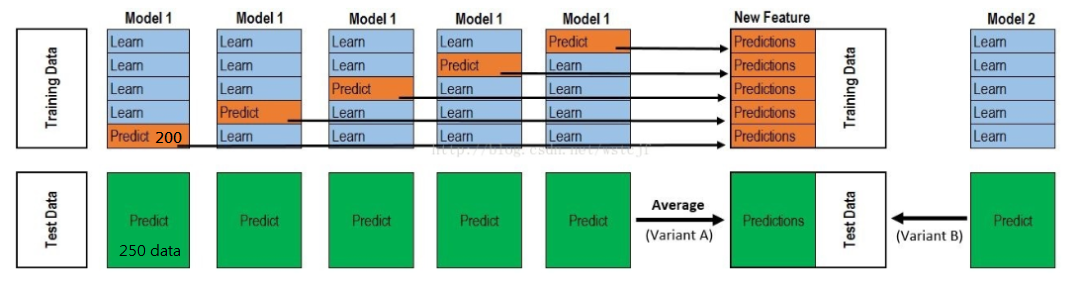
1 . 利用Basic Model(你可以選擇用Random Forest、GLM、GBM,等等 )進行5-fold交叉驗證,例如:用GBM作為Basic Model1,5-fold就是先拿出4折作為Training Data,另外一折作為Testing Data。
注意:在Stack中此部分會用到整個Data Set。例如:假设Training Set為1000行數據,Testing Set為250行數據,總共1250的Data Set,每一次的交叉驗證中會對Training Set進行劃分(5-fold)
Training data會是800行,Testing data是200行。
2 . 每一次的交叉驗證包含兩個過程
- 基于Training data訓練模型;
- 生成的模型對Testing data進行預測
在第一次的交叉驗證完成之后我們會得到當前Testing data的預測值,(一维200行的數據,簡稱P1)。
注意!這部分進行完後,我們還要Data Set的Testing Set進行預測,過程會產生250行預測值(一维250行的數據,簡稱K1),這部分預測值將會作為Testing data的一部分,
由於我們進行的是5-fold,所以以上提及的過程將會進行5次,最終會生成Testing data預測的5列200行的數據P1~5,對Testing set的預測是5列250行數據K1~5。
3 . 將P1~5合併起来,會形成一個1000行一列的矩陣,稱PA1。而K1~5數據,我們每一列的每一行取平均,得到一个250行一列的矩陣,稱KA1。
以上就是Stack中一個模型的完整流程,Stack中通常包含多個模型,假設
- Model2 : GLB
- Model3:RF
- Model4: XGboost
- Model5:SVM
對於其他模型,我們重複以上步驟,可以得到新的PA1~5,KA1~5矩陣。
並把PA1~5合併得到一個1000行五列的矩陣作為Training data,KA1~5合併得到一個250行五列的矩陣作為Testing data。再提供給下一層模型作訓練,以此類推。
三.經驗分享
再進行建模時,我都會對每個模型進行HyperParameter,這點之後會再進行教學,主要是對個模型參數調到滿意的程度
經驗法則下來,個人對於Basic model的組合為 GBM*2~3 、 GLB*1 、 RF*2~3 、DL*1 ,當然這會因資料有所不同,但分析許多資料我都用以這組為優先也都得到不錯的結果。