延續Part1,這篇會對於Feature Engineering & Building Model解說
一. Feature Engineering
## function for preparing features
def prepare_features(df, gap):
#(確診 - 死亡 - 康復) / 確診
df["perc_1_ac"] = (df[f"lag_{gap}_cc"] - df[f"lag_{gap}_ft"] - df[f"lag_{gap}_rc"]) / df[f"lag_{gap}_cc"]
#確診 / 人口
df["perc_1_cc"] = df[f"lag_{gap}_cc"] / df.population
#1~3天,前後確診差
df["diff_1_cc"] = df[f"lag_{gap}_cc"] - df[f"lag_{gap + 1}_cc"]
df["diff_2_cc"] = df[f"lag_{gap + 1}_cc"] - df[f"lag_{gap + 2}_cc"]
df["diff_3_cc"] = df[f"lag_{gap + 2}_cc"] - df[f"lag_{gap + 3}_cc"]
#1~3天,前後死亡差
df["diff_1_ft"] = df[f"lag_{gap}_ft"] - df[f"lag_{gap + 1}_ft"]
df["diff_2_ft"] = df[f"lag_{gap + 1}_ft"] - df[f"lag_{gap + 2}_ft"]
df["diff_3_ft"] = df[f"lag_{gap + 2}_ft"] - df[f"lag_{gap + 3}_ft"]
#1~3天,確診與死亡平均差
df["diff_123_cc"] = (df[f"lag_{gap}_cc"] - df[f"lag_{gap + 3}_cc"]) / 3
df["diff_123_ft"] = (df[f"lag_{gap}_ft"] - df[f"lag_{gap + 3}_ft"]) / 3
#1~2天、2~3天,死亡差的比例
df["diff_change_1_cc"] = df.diff_1_cc / df.diff_2_cc
df["diff_change_2_cc"] = df.diff_2_cc / df.diff_3_cc
#1~2天、2~3天,確診差的比例
df["diff_change_1_ft"] = df.diff_1_ft / df.diff_2_ft
df["diff_change_2_ft"] = df.diff_2_ft / df.diff_3_ft
#1~2天、2~3天,確診差的比例平均
#1~2天、2~3天,死亡差的比例平均
df["diff_change_12_cc"] = (df.diff_change_1_cc + df.diff_change_2_cc) / 2
df["diff_change_12_ft"] = (df.diff_change_1_ft + df.diff_change_2_ft) / 2
#1~3天,確診比例
df["change_1_cc"] = df[f"lag_{gap}_cc"] / df[f"lag_{gap + 1}_cc"]
df["change_2_cc"] = df[f"lag_{gap + 1}_cc"] / df[f"lag_{gap + 2}_cc"]
df["change_3_cc"] = df[f"lag_{gap + 2}_cc"] / df[f"lag_{gap + 3}_cc"]
#1~3天,死亡比例
df["change_1_ft"] = df[f"lag_{gap}_ft"] / df[f"lag_{gap + 1}_ft"]
df["change_2_ft"] = df[f"lag_{gap + 1}_ft"] / df[f"lag_{gap + 2}_ft"]
df["change_3_ft"] = df[f"lag_{gap + 2}_ft"] / df[f"lag_{gap + 3}_ft"]
#N、N+3天,確診比例
#N、N+3天,死亡比例
df["change_123_cc"] = df[f"lag_{gap}_cc"] / df[f"lag_{gap + 3}_cc"]
df["change_123_ft"] = df[f"lag_{gap}_ft"] / df[f"lag_{gap + 3}_ft"]
for case in DAYS_SINCE_CASES:
df[f"days_since_{case}_case"] = (df[f"case_{case}_date"] - df.Date).astype("timedelta64[D]")
df.loc[df[f"days_since_{case}_case"] < gap, f"days_since_{case}_case"] = np.nan
df["country_flag"] = df.Province_State.isna().astype(int)
df["density"] = df.population / df.area
#取log看出差異化
df["target_cc"] = np.log1p(df.ConfirmedCases) - np.log1p(df[f"lag_{gap}_cc"])
df["target_ft"] = np.log1p(df.Fatalities) - np.log1p(df[f"lag_{gap}_ft"])
features = [
f"lag_{gap}_cc",
f"lag_{gap}_ft",
f"lag_{gap}_rc",
"perc_1_ac",
"perc_1_cc",
"diff_1_cc",
"diff_2_cc",
"diff_3_cc",
"diff_1_ft",
"diff_2_ft",
"diff_3_ft",
"diff_123_cc",
"diff_123_ft",
"diff_change_1_cc",
"diff_change_2_cc",
"diff_change_1_ft",
"diff_change_2_ft",
"diff_change_12_cc",
"diff_change_12_ft",
"change_1_cc",
"change_2_cc",
"change_3_cc",
"change_1_ft",
"change_2_ft",
"change_3_ft",
"change_123_cc",
"change_123_ft",
"days_since_1_case",
"days_since_10_case",
"days_since_50_case",
"days_since_100_case",
"days_since_500_case",
"days_since_1000_case",
"days_since_5000_case",
"days_since_10000_case",
"country_flag",
"lat",
"lon",
"continent",
"population",
"area",
"density",
"target_cc",
"target_ft"
]
return df[features]
上一篇最後講到了變數擴增,在原始資料給的變數之少情況下,
我們必須要做變數的延展,這部分真的就需要經驗的累積加上專業知識,
也就是所謂的Knowhow,當然我也不是這方面的專長,必要時也需要去找相關文章去研讀,
整個過程一共增加了43個變數,程式碼我都有註解應該是很清楚了,我就不加以描述。
二. Building Model
接下來就是要開始建模,這次我選擇的是用LightGBM ,以下會簡單介紹LightGBM
LightGBM (GB指gradient boosting) 其實是進階版的Decision Tree,只是它的分枝是採用Leaf-wise(best-first),而不是傳統的Level-wise(depth-first)。
簡單介紹一下 Leaf-wise(best-first) & Level-wise(depth-first)。
Level-wise(depth-first)會每一層每一層建立整個tree,屬於低效率的方式 = > Xgboost
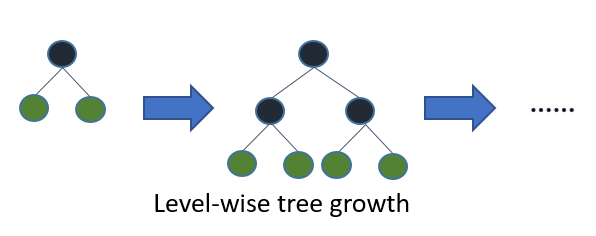 |
| https://lightgbm.readthedocs.io/en/latest/Features.html |
Leaf-wise(best-first)針對具有最大 delta loss 的葉節點來生長,所以相對於每一層每一層,它會找一枝持續長下去。
要小心的是在data比較少的時候,會有可能會造成過擬合狀況,不能讓它一直長下去,所以可以用max_depth做一些限制。
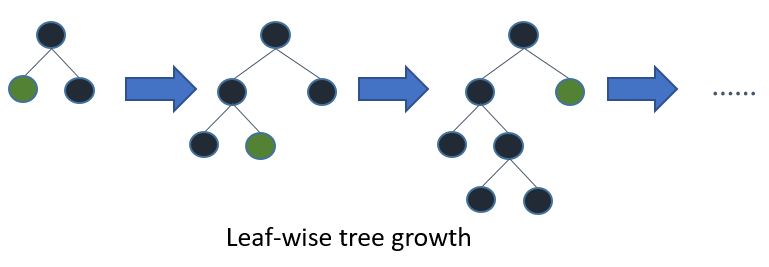 |
| https://lightgbm.readthedocs.io/en/latest/Features.html |
因此在分析巨量資料時LightGBM能提供更快、更有效的訓練方式,並達到一定的準確率,所以在Kaggle比賽中有慢慢取代Xgboost的味道。
再為LGBM構造資料集之前,必須將分類特徵轉換為integer。即使你通過categorical_feature傳遞引數,它也不接受字串值。
而我常用字串轉數值的方法如下:
- LabelEncoder(le)
例如:把"星期"欄位改成1, 2, 3, 4, 5, 6, 7 - OneHotEncoder(ohe) / dummy variables
例如:把一欄"性別"欄位的男跟女改成兩欄"男"跟"女"(值分別是0跟1) - Feature hashing (a.k.a the hashing trick)
很像OHE但降低維度
三種方式都能達到目標,就看自己習慣哪一套。
接下來,簡單介紹一下如何使用Python去建LightGB模型
#載入套件
import lightgbm as lgb
def build_predict_lgbm(df_train, df_test, gap):
#gap為間隔天數
df_train.dropna(subset = ["target_cc", "target_ft", f"lag_{gap}_cc", f"lag_{gap}_ft"], inplace = True)
target_cc = df_train.target_cc
target_ft = df_train.target_ft
test_lag_cc = df_test[f"lag_{gap}_cc"].values
test_lag_ft = df_test[f"lag_{gap}_ft"].values
#刪除"target_cc"、"target_ft"
df_train.drop(["target_cc", "target_ft"], axis = 1, inplace = True)
df_test.drop(["target_cc", "target_ft"], axis = 1, inplace = True)
categorical_features = ["continent"]
# 這邊參數我都調校過了(使用GridSearchCV)
LGB_PARAMS = {"objective": "regression",
"num_leaves": 40,
'max_depth' : 15,
"learning_rate": 0.009,
"bagging_fraction": 0.6,
'min_child_samples':22,
'min_child_weight':0.001,
"feature_fraction": 0.9,
'bagging_freq' : 2,
"reg_alpha": 0.2,
"reg_lambda": 0.2,
"metric": "rmse",
"seed": SEED
}
#產生dataset
dtrain_cc = lgb.Dataset(df_train, label = target_cc, categorical_feature = categorical_features)
dtrain_ft = lgb.Dataset(df_train, label = target_ft, categorical_feature = categorical_features)
#訓練模型
model_cc = lgb.train(LGB_PARAMS, train_set = dtrain_cc, num_boost_round = 200)
model_ft = lgb.train(LGB_PARAMS, train_set = dtrain_ft, num_boost_round = 200)
# 將最後一筆的值取log & inverse
y_pred_cc = np.expm1(model_cc.predict(df_test, num_boost_round = 200) + np.log1p(test_lag_cc))
y_pred_ft = np.expm1(model_ft.predict(df_test, num_boost_round = 200) + np.log1p(test_lag_ft))
return y_pred_cc, y_pred_ft, model_cc, model_ft
三. Predict Data
預測資料使用MAD(平均絕對偏差)產出
這邊也可以做變化,你想要用decay、average都可以
def predict_mad(df_test, gap, val = False):
df_test["avg_diff_cc"] = (df_test[f"lag_{gap}_cc"] - df_test[f"lag_{gap + 3}_cc"]) / 3
df_test["avg_diff_ft"] = (df_test[f"lag_{gap}_ft"] - df_test[f"lag_{gap + 3}_ft"]) / 3
if val:
y_pred_cc = df_test[f"lag_{gap}_cc"] + gap * df_test.avg_diff_cc - (1 - MAD_FACTOR) * df_test.avg_diff_cc * np.sum([x for x in range(gap)]) / VAL_DAYS
y_pred_ft = df_test[f"lag_{gap}_ft"] + gap * df_test.avg_diff_ft - (1 - MAD_FACTOR) * df_test.avg_diff_ft * np.sum([x for x in range(gap)]) / VAL_DAYS
else:
y_pred_cc = df_test[f"lag_{gap}_cc"] + gap * df_test.avg_diff_cc - (1 - MAD_FACTOR) * df_test.avg_diff_cc * np.sum([x for x in range(gap)]) / n_dates_test
y_pred_ft = df_test[f"lag_{gap}_ft"] + gap * df_test.avg_diff_ft - (1 - MAD_FACTOR) * df_test.avg_diff_ft * np.sum([x for x in range(gap)]) / n_dates_test
return y_pred_cc, y_pred_ft
四. Output
預測出來比預期好上許多,本來以為誤差起伏會較大(因為不確定的因素太多)
p.s 上述的gap參數我是取1、14、28天,有興趣的人可以嘗試換不同天數
| 日期 | WHO數據 | 模型預測 | 誤差率 |
| 2020/4/20 | 2314621 | 2302479 | 0.52458% |
| 2020/4/21 | 2397216 | 2380246 | 0.70790% |
| 2020/4/22 | 2471136 | 2468596 | 0.10279% |
| 2020/4/23 | 2544729 | 2552663 | -0.31178% |
| 2020/4/24 | 2626321 | 2645990.471 | -0.74894% |
| 2020/4/25 | 2719897 | 2709938.601 | 0.36613% |
| 2020/4/26 | 2804796 | 2798879.723 | 0.21093% |
| 2020/4/27 | 2878196 | 2894055.231 | -0.55101% |
| 2020/4/28 | 2954222 | 2992850.934 | -1.30758% |
| 2020/4/29 | 3018952 | 3065029.782 | -1.52628% |
| 2020/4/30 | 3090445 | 3125788.941 | -1.14365% |
| 2020/5/3 | 3349786 | 3344373.186 | 0.16159% |
| 2020/5/4 | 3435894 | 3436680.301 | -0.02288% |
| 2020/5/5 | 3517345 | 3521484.261 | -0.11768% |
| 2020/5/6 | 3588773 | 3598501.069 | -0.27107% |
| 2020/5/7 | 3672238 | 3671038 | 0.03268% |
| 2020/5/8 | 3759255 | 3749538.337 | 0.25847% |
| 2020/5/9 | 3855788 | 3845811.165 | 0.25875% |
| 2020/5/10 | 3917366 | 3942865.94 | -0.65095% |
| 2020/5/11 | 4006257 | 4041084.403 | -0.86933% |
| 2020/5/12 | 4088848 | 4125929.685 | -0.90690% |
| 2020/5/13 | 4170424 | 4198747.669 | -0.67916% |
| 2020/5/14 | 4248389 | 4268651.178 | -0.47694% |