一直沒有把腦袋的東西好好的整理起來,這邊會從我開始當DBA後所學的東西慢慢寫成文章。
還記得剛當DBA時,先認識了SQL Server的架構,故首發想先跟大家簡單的分享SQL Server的架構,如有錯誤或是需要補充的歡迎在下面留言讓我知道。
從宏觀來看,SQL Server裡由四個部分組成,分別是:Protocols、Query Processor 、Storage Engine 、SQL OS。如下圖:(圖片來源)
{kind=link}
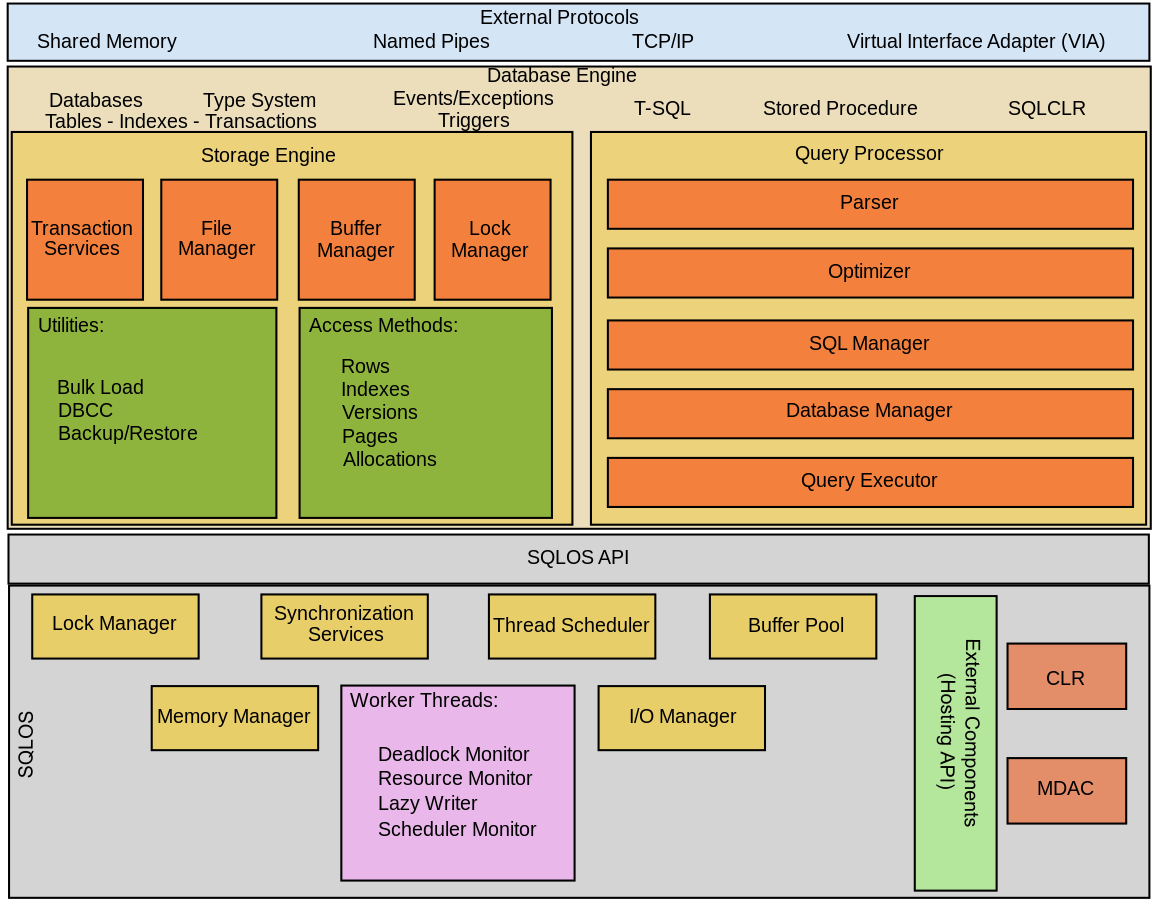
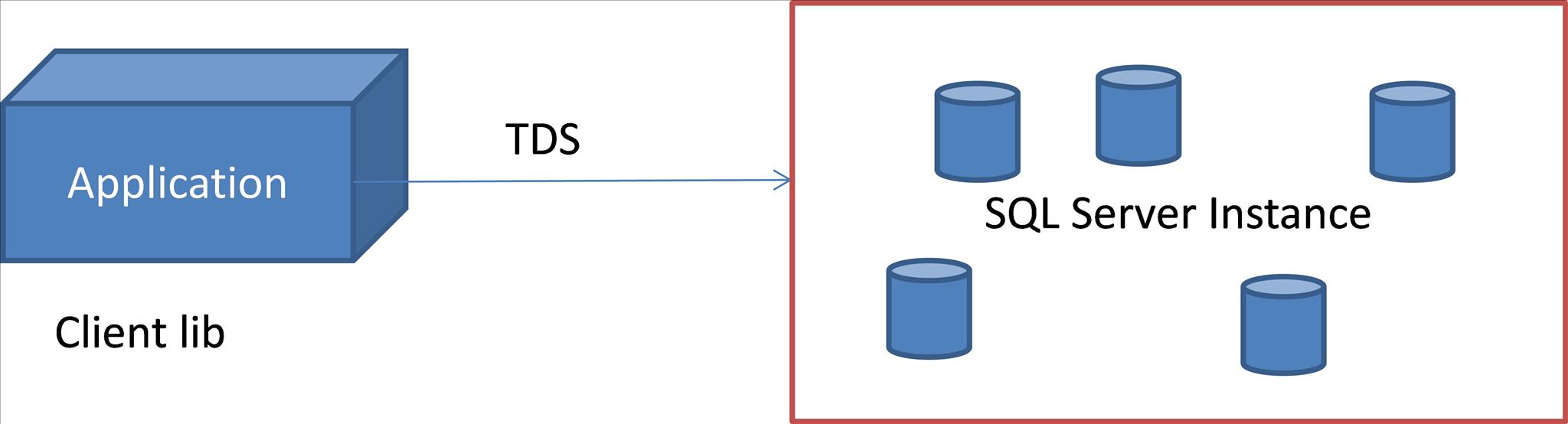
協議層,為SQL Server最外層,是應用程序(application)向SQL Server訪問的接口。
其中,Protocols是使用TDS來規範通訊格式 (TDS是一種資料格式,用來給protocols接收/解析data),故application需要把自己想發的資料轉成TDS的資料格式,才能再透過網路發給SQL Server接收,如下圖。
更細節的話,可以知道Protocols有分三種連接方式,分別是:Shared memory、Named Pipes、TCP/IP
- Shared memory:for Local server的application連接SQL Server用
- Named Pipes:for local area networks (LANs)
- TCP/IP:for Local 以外的所有application用的
故如果你的application連不上SQL Server,可以根據application的網域,去檢查相對應Protocol的是否有開啟。
查詢處理器,又稱關係引擎(Relational Engine),為SQL Server中間層也是最核心部分之一,用來分析Query和尋找適合的plan,並執行它(若在這過程中需要數據,則會向Storage Engine發送數據請求)。
大致上Query Processer的處理順序為
Parsing → Binding → Query Optimization → Query Execution → Query Results
詳細說明:
若現在有Query進來,則Query Processor的處理順序為
- 產生一個邏輯樹來分析T-SQL(判斷此語法要去哪個source拿資料,是否有join以及是否有filter條件)
- 分析後,把會用到的Object轉成ID並連結在一起
- 查看Buffer pool裡的Execution Plan Cache 是否有可用的Execution plan
- 若有則會直接用;若沒有則會產生Query Tree(語法樹)
- Query Tree會先判斷此Query是否可優化,若是不可再優化的語法則會直接執行(e.g. DDL);若是可再優化的語法(e.g. DML)則會先mark起來,丟給Query Optimization優化
- 再由Query Optimization產生所有可能的plans,並篩選出最後的Execution plan (過程中若有需要則會向Storage Engine中的Access Methods互相要數據或修改數據)
- 執行最後的Execution plan,並把此plan放入Buffer pool中,以及把剛剛使用到的數據還給Storage Engine
- 以TDS的資料格式將結果傳回給application
PS: Buffer pool裡有Execution plan cache和data cache
存儲引擎,裡面包含了Access Methods、Transaction services、Buffer Manager...等等
Access Methods:
- 創建與掃描資料頁和index頁
- 對buffer manager發出請求要資料
...
Transaction services: 大致上來說為確保資料正確性
Buffer Manager:管理Buffer Pool的數據
單獨的應用層,位在SQL Server的最底層。
主要功能為調度資源、分配內存、管理schedule...等等。
如果SQL Server需要用到SQL OS時,SQL OS會分配工人去處理工作,而Processor、Scheduler、Thread的關係則改天再詳細說明。
或是可以參考此篇文章
常用的語法為
- sys.dm_os_schedulers:查看現在SQL Server有哪些scheduler
- sys.dm_os_waiting_tasks:可以看到哪些task是正在排隊中,以及看到他們在等什麼resource