Cluster Disk Failed, Shared Storage, failover fail
今天遇到Cluster Disk failed,因為是用shared storage所以SQL cluster無法切到別的Node,SQL Service down的問題
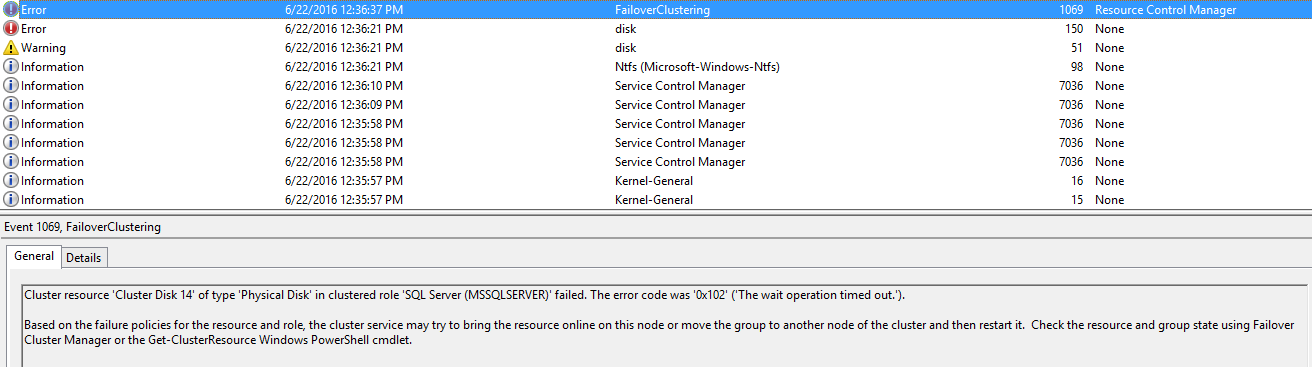
線索是在此之前有兩個disk crossed a capacity utilization threshold
是否因此挑上可能是Thin-provisioned的Cluster Disk 把它offline?
根據: http://www-03.ibm.com/support/techdocs/atsmastr.nsf/c6192fb3a432612485256d970082de57/865fc1c7a50911a486257b16005b9ff2/$FILE/Microsoft_XIV_Space_Reclamation_Final_Draft.pdf
P.14
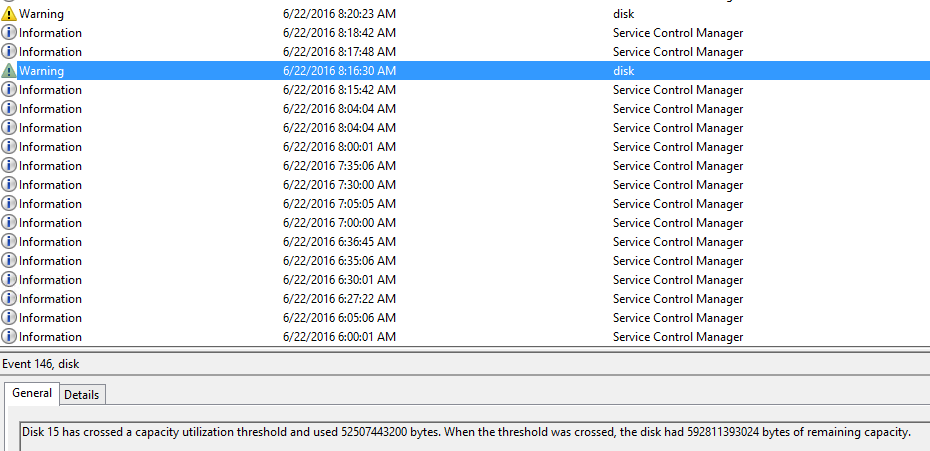
為何這兩個Disk會crossed a capacity utilization threshold ? 根據以下文件,
https://technet.microsoft.com/en-us/library/jj674351.aspx
A storage administrator can do this by using the vendor’s storage management tools
you want to use real-time space reclamation, but you have a thin-provisioned LUN that is used by a highly volatile application where large file deletions are common, we recommend that you convert the thin-provisioned LUN to a thick (or full) provisioned LUN.
有可能是在thin-provisioned LUN做太繁重的作業,但這台機器平時作業並不繁重...甚至算輕了
研究有心得再補上。
