同事們程式上很常遇到在SSMS上執行查詢很快,
由程式執行相同條件的查詢後非常的慢,在這邊紀錄一下問題。
同事設計一個簡單的查詢,目的為了查出Primary Key為空白值的合約號跟客戶類型
SELECT ContractNumber, CustomerType FROM Customer WHERE CustomerID = ''
同事寫的C#,裡面是很簡單的查詢
oCmd.CommandText = "select ContractNumber,CustomerType from Customer where CustomerID=@CustomerID";
oCmd.Parameters.Clear();
oCmd.Parameters.AddWithValue("@CustomerID", row["CustomerID"].ToString().Trim());
oDR1 = oCmd.ExecuteReader();
資料表大約如下,裡面近130萬筆資料。
CREATE TABLE Customer (
CustomerID char (5) NOT NULL,
CustomerType char (2) NOT NULL,
ContractNumber int NULL,
CustomerStatus char (1) NULL,
SalesDesc char (500) NULL,
CONSTRAINT PK_Customer PRIMARY KEY CLUSTERED
(CustomerID ASC)
)
我們從SSMS上去執行查詢,且實際執行後查詢看起來並不慢
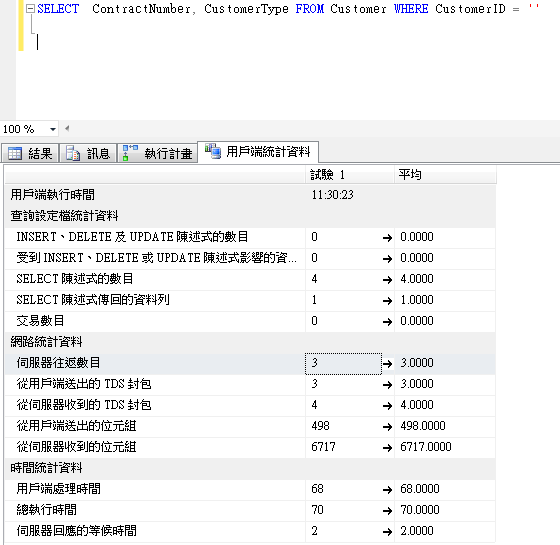


透過SQL Profiler 去觀察到的查詢字串如下
EXEC sp_executesql N'select ContractNumber,CustomerType from Customer where CustomerID=@CustomerID',
N'@CustomerID nvarchar(4000)',
@CustomerID = N''
因程式未設定變數的型別跟長度,所以採用了nvarchar (4000)。
我們將這段查詢在SSMS上執行,結果如下。

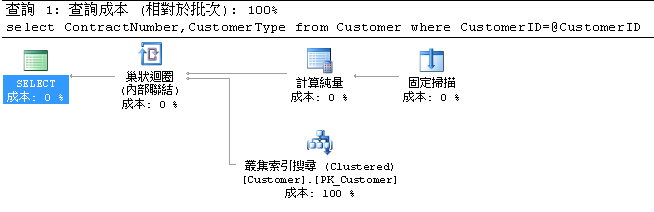

很明顯的看出執行時間變長了,Client與Server間的資料傳送量變高,且邏輯讀取也明顯提高。

執行計畫中述詞進行轉換後還是採用nchar(5)。
問題\在於型別的不正確,我們不動長度,但是將nvarchar改為資料表上的char
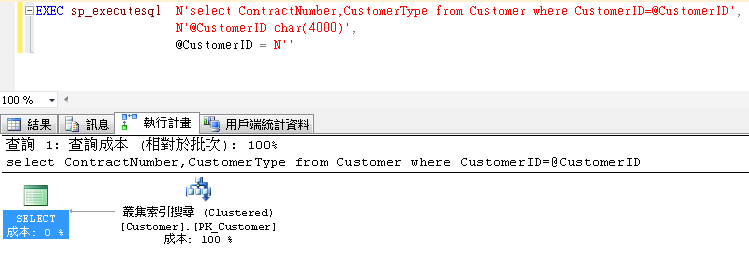
查詢已經改用執行計畫了,由此可見Parameter;上的型別差異其實會影響到查詢效率,
實際上Unicode的2byte對資料表的搜尋效率影響其實很大,相關資訊可以參考MSDN內容。
https://msdn.microsoft.com/en-us/library/yy6y35y8(v=vs.110).aspx
