Coding KMeans Clustering Using Scala with Spark。
這篇原則上是我的工作筆記,簡單實作一下 KMeans 分群並大概說明其用法和用途。
假設今天我們想要了解我們客戶的生活作息,我們可以用很多種特徵去描述該客戶是屬於哪個生活型態的人。
例如郊外踏青族、Shopping 族、朝九晚五族、夜貓族...等。
這裡就用一個很簡單的方式來去描述一個人的作息行為。
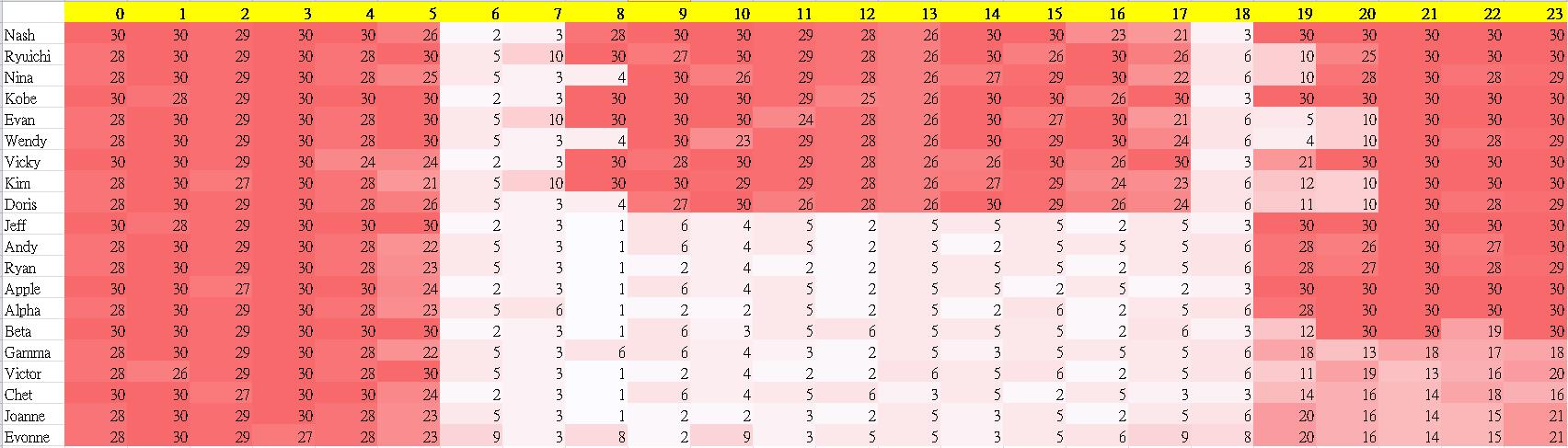
首先我們先準備一個簡單的表,如下。
每列代表一個人在一個月當中每天24小時的移動狀態,數字越大顏色越深代表那個人在當月的那個小時大多處於停滯不動的狀態。
舉例,Nash 這個人照他的資料來看,幾乎有很大的可能就是個朝九晚五坐辦公室的上班族,他的移動時間大多只出現在6~7點(上班)與18點(下班)。
而 Jeff 這個人則有很大的機會是屬於業務型態,或是做物流業的司機,在白天的時段幾乎不斷在移動。
Joanne 這個人除了在上班時段不斷移動外,下了班之後似乎也有一半的時間也是處於移動狀態,可推測可能是上班時間比較長或是下班後夜生活豐富。
但我們總不能用肉眼去看每一筆資料,用規則去規定哪個客戶是屬於哪一個族群。
此時 KMeans 分群就派上用場。
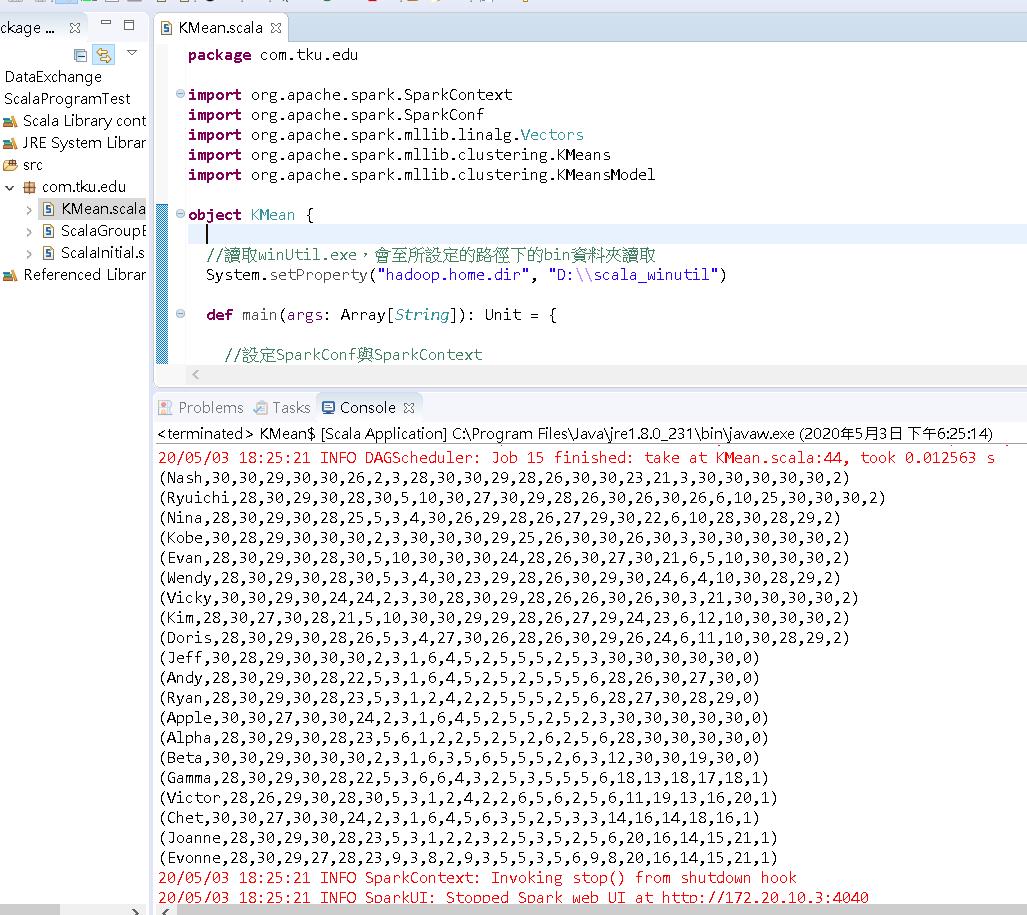
將上述資料以 CSV 的方式儲存後,便可以開始以 KMeans 進行分群,讓模型自動幫我們做貼標的動作,程式碼實作如下。

import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.clustering.KMeans
import org.apache.spark.mllib.clustering.KMeansModel
object KMean {
//讀取winUtil.exe,會至所設定的路徑下的bin資料夾讀取
System.setProperty("hadoop.home.dir", "D:\\scala_winutil")
def main(args: Array[String]): Unit = {
//設定SparkConf與SparkContext
val conf = new SparkConf().setAppName("").setMaster("local[1]")
val sc = new SparkContext(conf)
//讀檔案
var inHdfsUrl = "D:///time_line.csv"
val csvData = sc.textFile(inHdfsUrl)
//利用Vectors.dense將檔案弄成可以餵給KMeans吃的格式
val vectorData = csvData.map(csvLine => Vectors.dense(csvLine.split(",").slice(1, csvLine.split(",").length).map(_.toDouble)))
val kMeans = new KMeans
val numClusters = 3 //設定分3群
val maxIterations = 20
val initializationMode = KMeans.K_MEANS_PARALLEL
val numRuns = 1
val numEpsilon = 1e-4
kMeans.setK(numClusters)
kMeans.setMaxIterations(maxIterations)
kMeans.setInitializationMode(initializationMode)
kMeans.setRuns(numRuns)
kMeans.setEpsilon(numEpsilon)
vectorData.cache
val kMeansModel = kMeans.run(vectorData)
val kMeansCost = kMeansModel.computeCost(vectorData)
//kMeansCost 這個值要越小越好,代表每個資料與模型的距離平方和最小,也代表這個模型最能描述你的資料狀態
System.out.println(kMeansCost)
//將分群結果與原始資料做合併
val joinResult = csvData.map(x=>(x, kMeansModel.predict(Vectors.dense(x.split(",").slice(1, x.split(",").length).map(_.toDouble)))))
joinResult.take(100).foreach(println)
}
}
結果如下,每一個人的分群結果顯示在每一列的最後一個數字 0、1、2。
對照 Excel 看,你會發現同樣性質的人都被分在同一群了。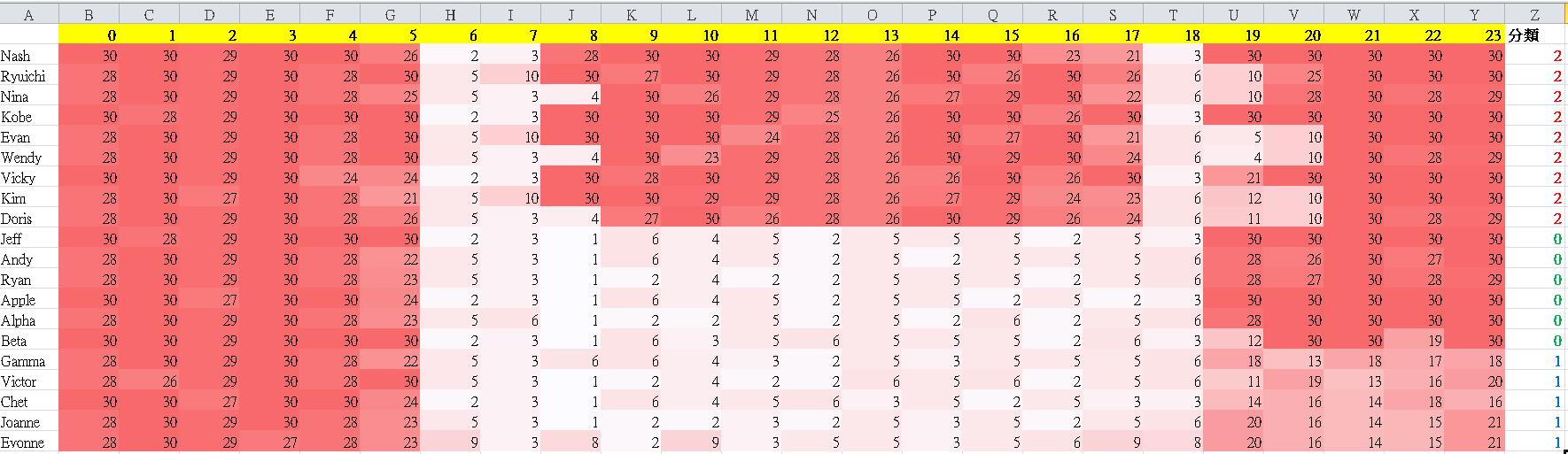
至於剛拿到資料不了解資料的狀態時,怎麼會知道要分幾群?
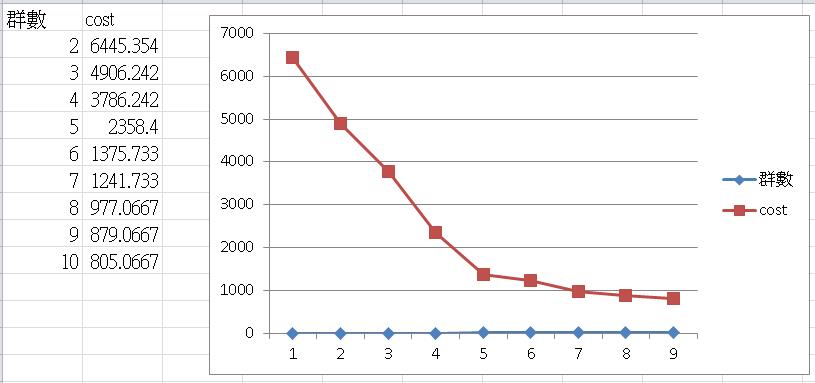
可以利用 Elbow Method 求解,如下圖,將分幾群的 Cost 畫成折線圖,就可以知道分幾群最可以描述這團資料。
以此篇做的範例,分 5 群可以得到最佳解(群內差異小,群間差異大),超過 5 群,Cost 減少的狀況沒有很明顯。
原則上分越多群 Cost 本來就會越低,但會造成模型 OverFitting,同時群數太多你也會解釋不出來,這都不是我們要的作法。
分的群數有辦法描述資料,且分群的人本身有辦法去解釋分群結果,這才是比較實務上的做法。