Coding KMeans Clustering Using Python with Spark。
在之前我寫過利用 Scala 撰寫 Kmeans 分群。
但 Scala 對於不是先學過 Java 的人來說太陌生了,加上參加了公司舉辦的工作社團後,發現其實一些不太寫程式的單位,要他們開始碰觸 AI 大多都習慣從 python 下手。
因此心血來潮研究並找了一下如何使用 python 做分群,並將其技術寫成技術網誌。
此篇並不是引用 matplotlib 做分群撰寫,而是分享如何使用 pyspark 於本機端撰寫可以執行的 code。
未來在真正的叢集上開發時,程式碼可以幾乎無痛的移轉使用。
程式碼有參考此連結 https://dblab.xmu.edu.cn/blog/1779-2/,但我有自己實驗並加以調整使用 Spyder 可進行本機端開發。
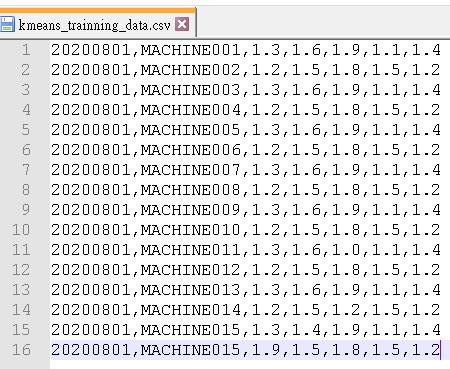
1.資料集
首先我們準備要使用的資料集,如下圖。
假設我們今天是要為某一天工廠的機器依據其內部的5個狀態值做分類,藉由分群的結果判斷該機器是否該做維修或調整。
內容就包含日期、機器名稱、5個狀態值。
2.程式碼圖解說明
因為用 pyspark 寫其實程式碼很簡潔,我就不一段一段說明,直接用圖文的方式簡述,最後面在附上程式碼。
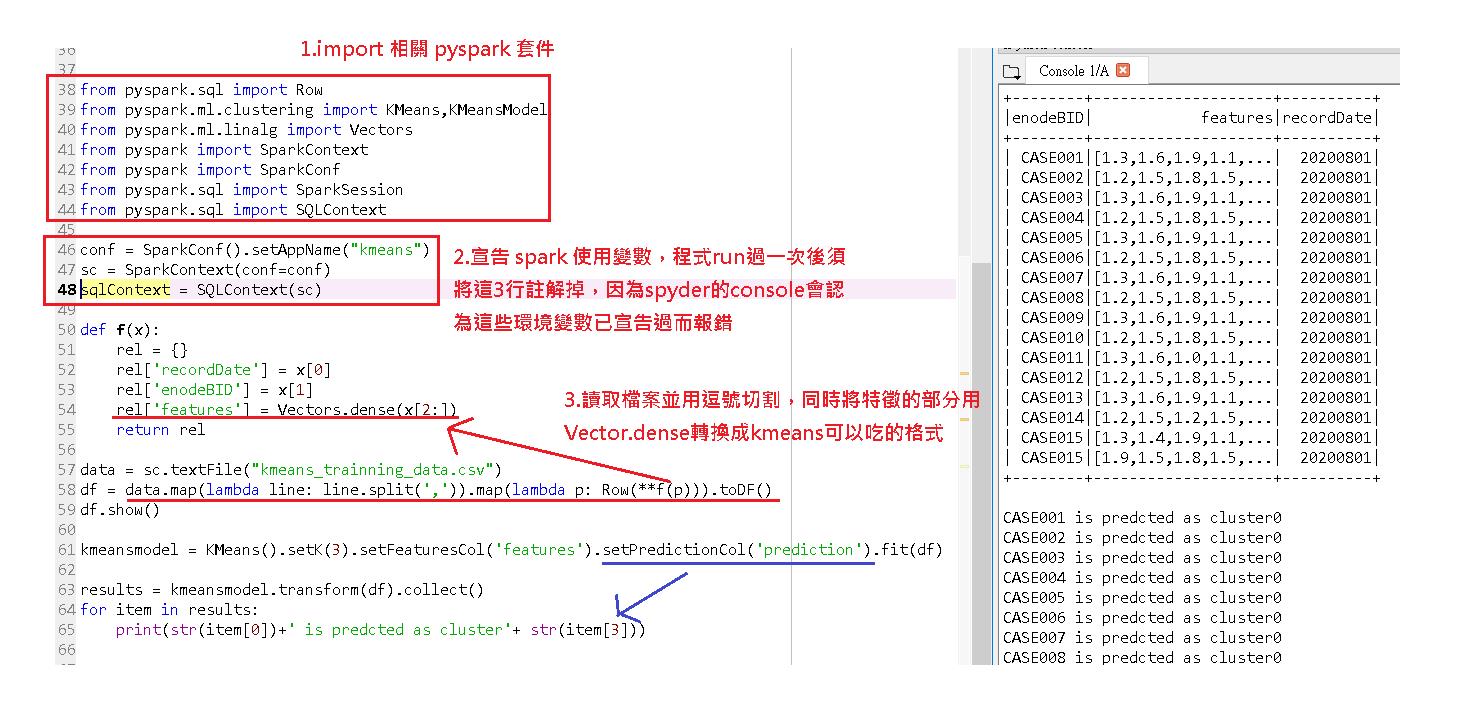
補充:第二步如果在執行第二次以上時沒註解掉的話,你的 spyder console 就會跳下面的錯誤:
ValueError: Cannot run multiple SparkContexts at once; existing SparkContext(app=kmeans, master=local[*]) created by __init__
3.程式碼
from pyspark.sql import Row
from pyspark.ml.clustering import KMeans,KMeansModel
from pyspark.ml.linalg import Vectors
from pyspark import SparkContext
from pyspark import SparkConf
from pyspark.sql import SparkSession
from pyspark.sql import SQLContext
conf = SparkConf().setAppName("kmeans")
sc = SparkContext(conf=conf)
sqlContext = SQLContext(sc)
def f(x):
rel = {}
rel['recordDate'] = x[0]
rel['enodeBID'] = x[1]
rel['features'] = Vectors.dense(x[2:])
return rel
data = sc.textFile("kmeans_trainning_data.csv")
df = data.map(lambda line: line.split(',')).map(lambda p: Row(**f(p))).toDF()
df.show()
kmeansmodel = KMeans().setK(3).setFeaturesCol('features').setPredictionCol('prediction').fit(df)
results = kmeansmodel.transform(df).collect()
for item in results:
print(str(item[0])+' is predcted as cluster'+ str(item[3]))