$(date -d "$saveFileDate -1 days" +'%Y%m%d')
雖然本人已由前端純軟體工程師慢慢轉職為資料工程師,但在轉型的過程中發現,只有單純寫數據處理的 code 對一個資料工程師的完成型似乎是不夠的。
在叢集上處理完大數據的分析結果,最終還是得 pass 到前端做應用,而這樣的過程就必須牽扯到資料介接,然而最常使用的方式就是寫 Shell Script 將結果做儲存與回傳。
因此開一個系列,將研究出的 Shell Script 做個系列整理並記錄下來,供日後做技術庫查詢使用,同時也分享給需要的人。
大數據的處理,常常會設定每日固定啟動的排程去計算前一天的資料當作今日資料的結果。
假設我要產出 20201004 的資料,但實際上我使用的是 20201003 的資料當作計算基礎。
也就是我使用資料時用 20201003,但存檔時檔名需存成 20201004。
實務上在撰寫 shell 時,我發現有些工程師會犯一個錯誤,取檔案與存檔的日期分開用$(date '+%Y%m%d')取。
這會產生一個問題,當我一個 shell 執行時間跨天時,讀檔與存檔取的日期字串基礎就會不一樣。
saveFileDate=$(date '+%Y%m%d')
[Shell 資料處理細節.....]
referencedFileDate=$(date -d "-1 days" +'%Y%m%d')
以上面的 code 為例,當 [Shell 資料處理細節.....] 這段程式碼處理超過 1 天時(以大數據的資料量是很有可能發生的),referencedFileDate 和 saveFileDate 對應的日期串便會搭不起來。
本來預期 saveFileDate 是 20201004,referencedFileDate 是 20201003。
但因為執行太久跨天了,執行到 referencedFileDate=$(date -d "-1 days" +'%Y%m%d') 這段 code 時,referencedFileDate卻變成 20201004,這就不是我們要的結果。
或許會有人說"那我直接把 saveFileDate 和 referencedFileDate 都寫在 shell 最前面不就好了?"
但這也會有種很極端的情況,當 saveFileDate 和 referencedFileDate 這兩行 code 執行跨天時,日期基準依然會跑掉(當你的系統非常忙碌時的確有可能發生這種窘境)。
雖然是很小的細節,但一出錯會造成很多後續資料的計算有問題。
因此在撰寫時因該要以同一個日期變數當作處理基準。
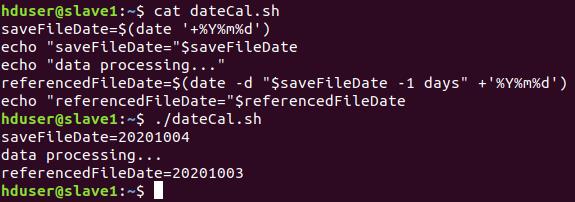
實際撰寫 code 並列印結果:
saveFileDate=$(date '+%Y%m%d')
echo "saveFileDate="$saveFileDate
echo "data processing..."
referencedFileDate=$(date -d "$saveFileDate -1 days" +'%Y%m%d')
echo "referencedFileDate="$referencedFileDate