Python函式庫:requests、BeautifulSoup、pandas。
網頁檢視工具:Win_x64_814947_chrome-win、SelectorGadget。
此篇為網路爬蟲 - Python 的課後作業,將使用到的技術實際應用並記錄起來。
作業內容:抓取自由時報即時新聞 (https://news.ltn.com.tw/list/breakingnews) 的標題、連結與時間。
如下圖,抓取紅框內每一個 Row 裡的資訊,我會寫兩種完成方法,一種是較直觀的取得方式,另一種是針對網頁呼叫 API 回傳的方式撈取完整資訊。
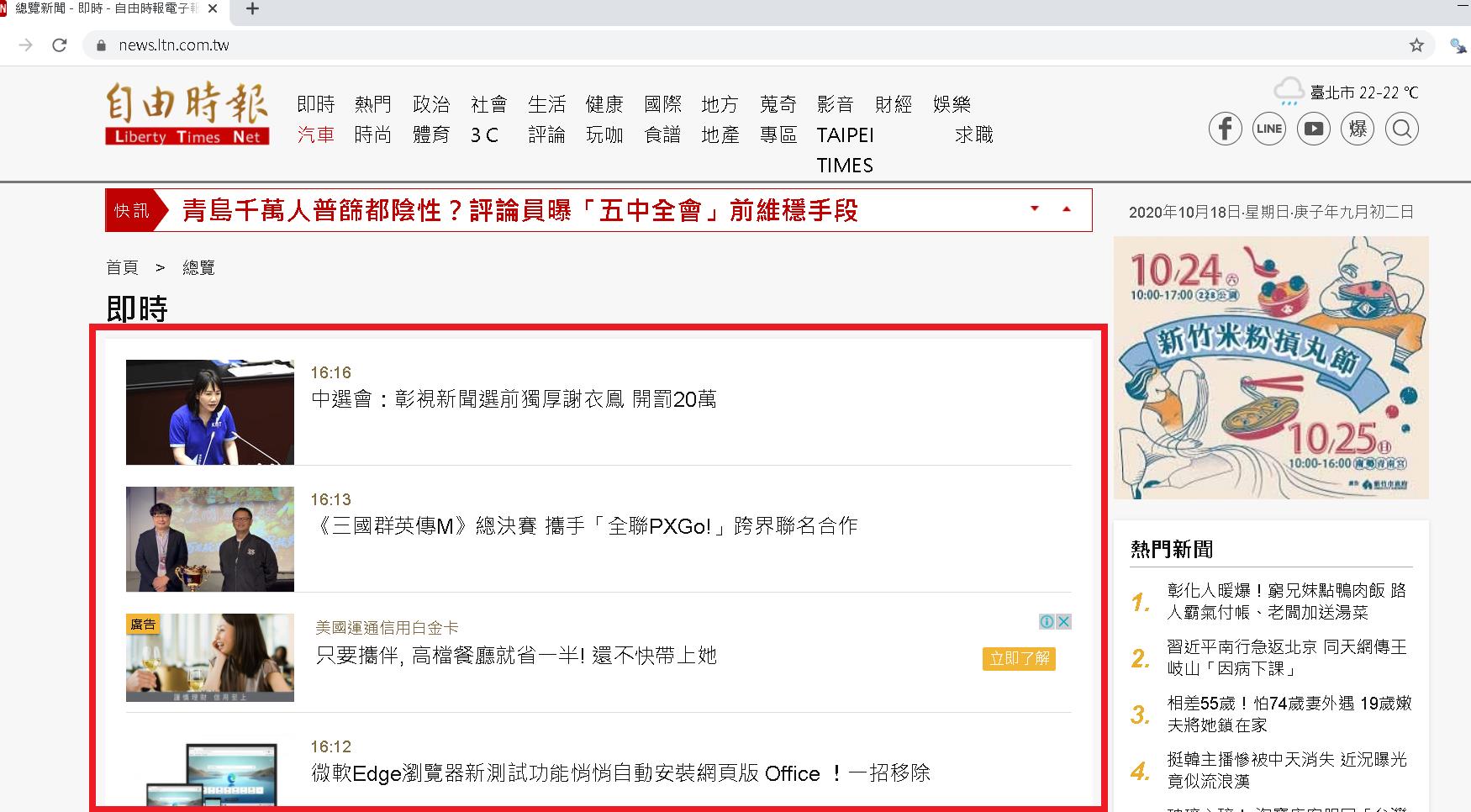
方法一:使用 SelectorGadget 抓出區域後抓取:
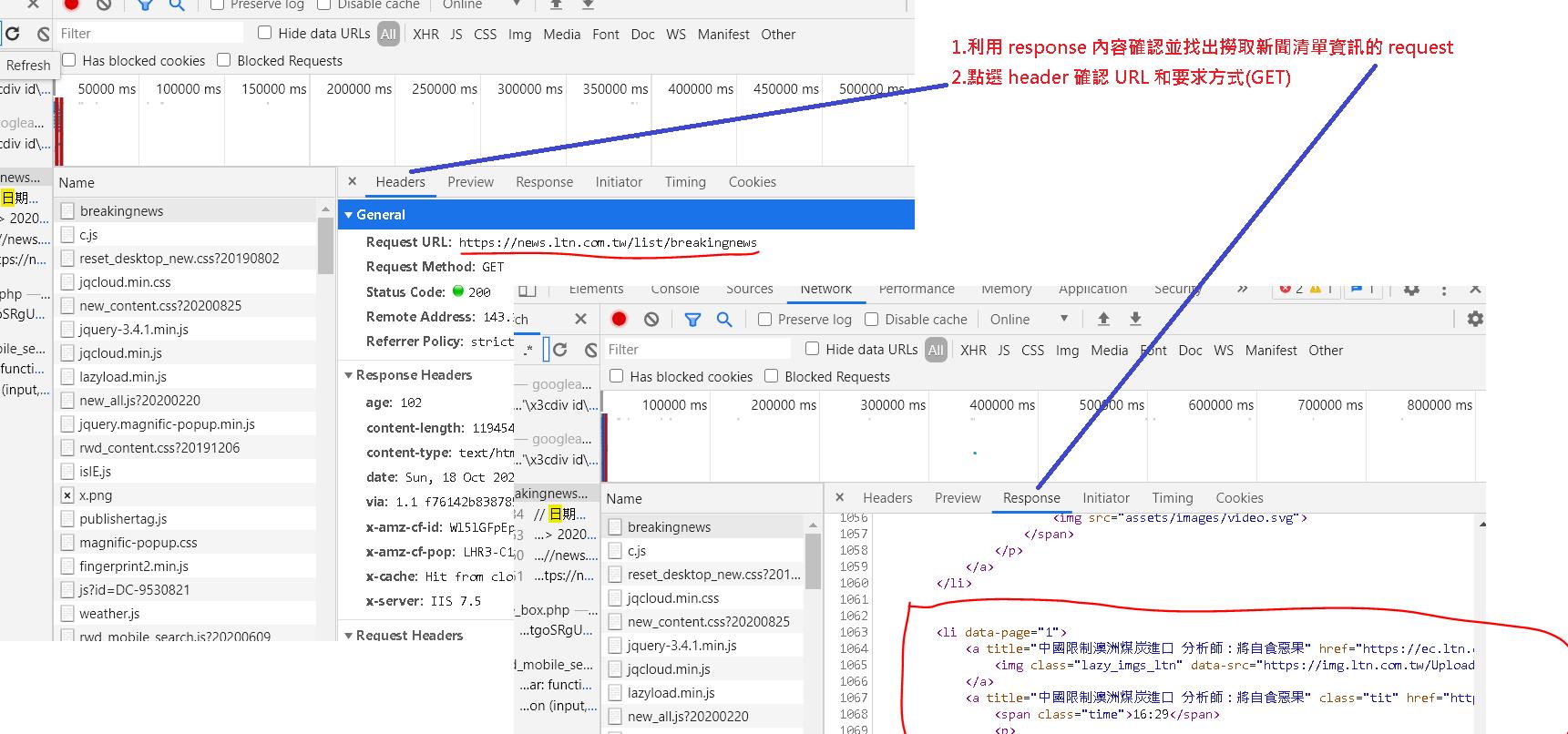
使用 chrome 的檢查功能,點選 headers 確認網頁是呼叫哪個 url 得到資訊,這裡找到就是跟網址一樣 https://news.ltn.com.tw/list/breakingnews。
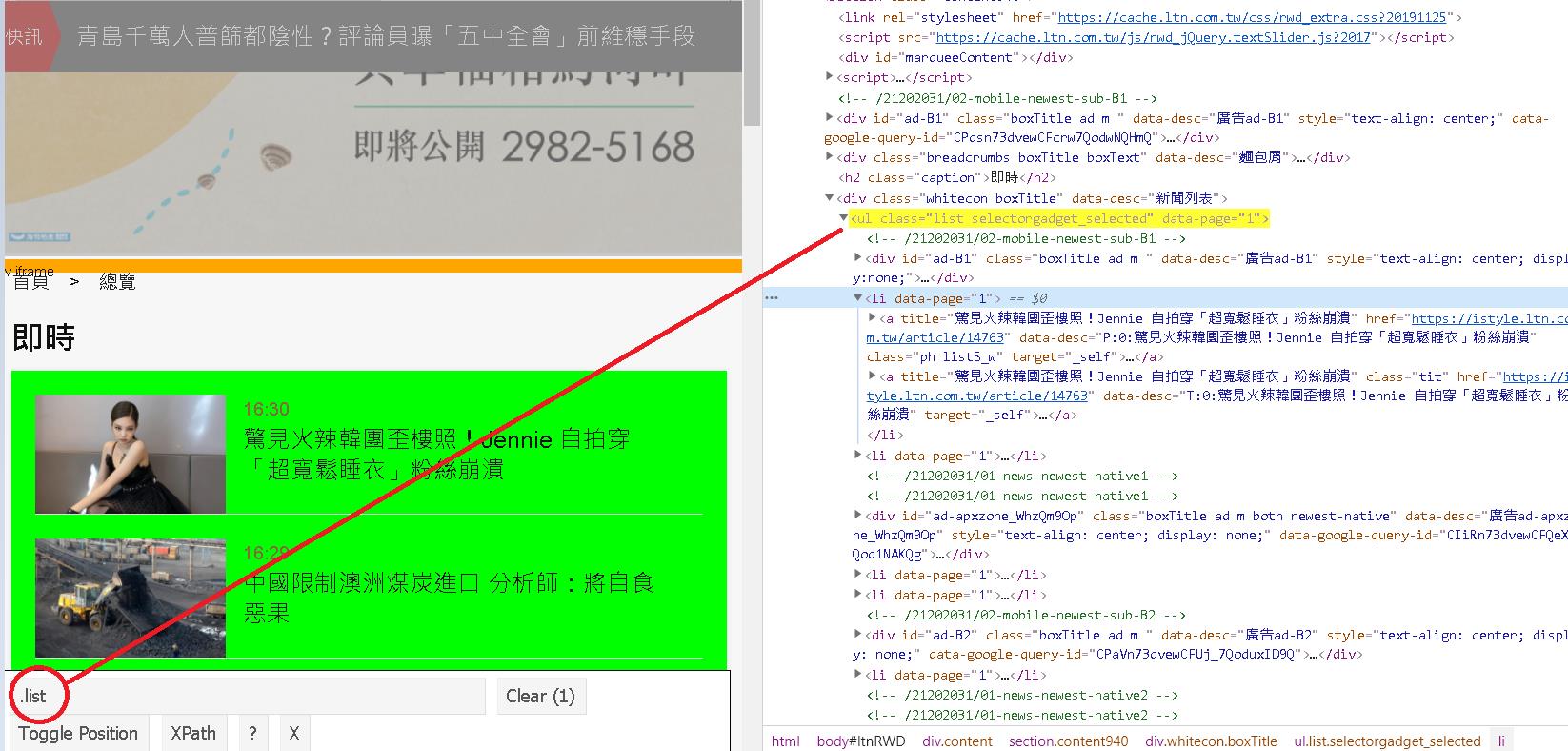
利用 SelectorGadget 點選找出用哪些 tag 可以找出該區域的資料,在此我們找到用 class 為 list 的字眼可以找到這個新聞清單區塊。
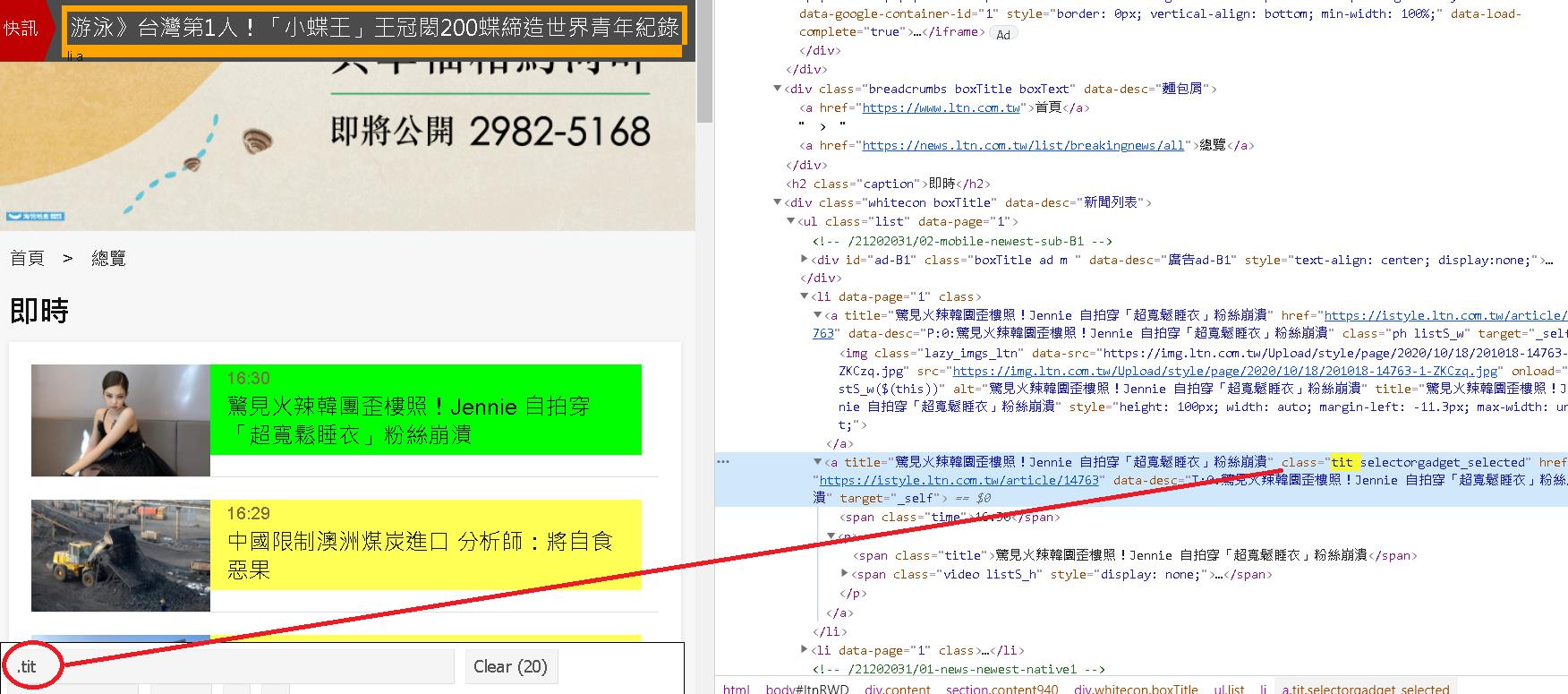
接著還可以用 SelectorGadget 繼續找出每個新聞的獨立區塊,工具推薦我們用的字眼為 tit。
了解結構後我們便可以進行程式的開發與測試,如下圖。

程式碼與執行結果如下。
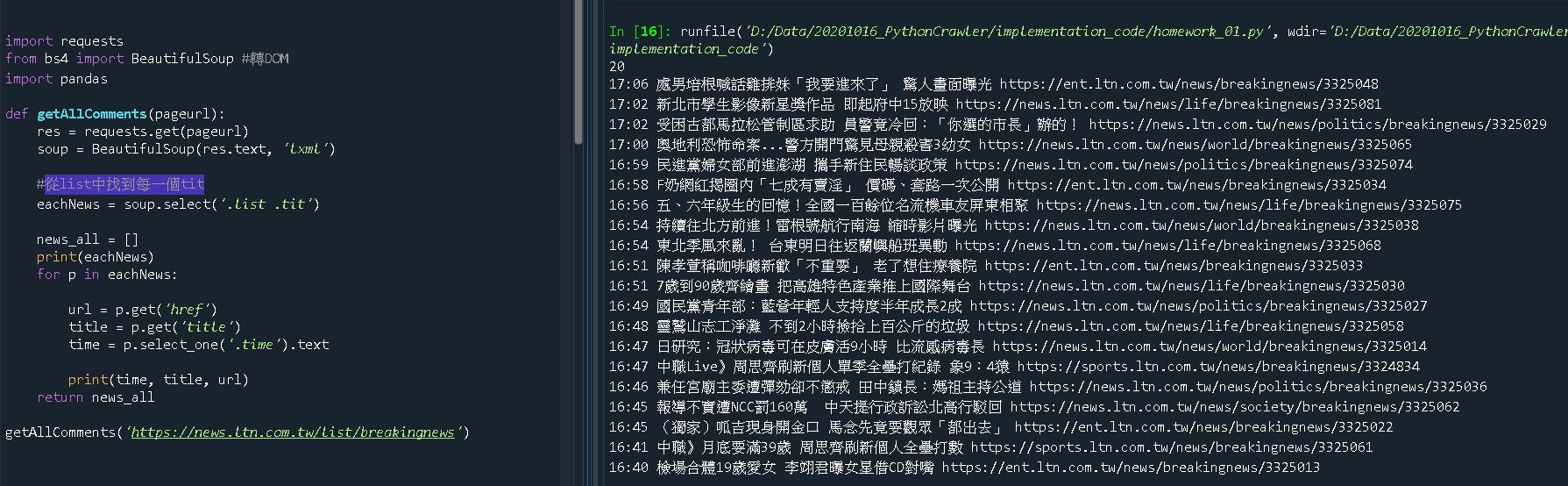
import requests
from bs4 import BeautifulSoup #轉DOM
import pandas
def getAllComments(pageurl):
res = requests.get(pageurl)
soup = BeautifulSoup(res.text, 'lxml') #老師建議無特殊需求的話都用lxml格式讀取
#從list中找到每一個tit
eachNews = soup.select('.list .tit')
news_all = []
print(eachNews)
for p in eachNews:
url = p.get('href')
title = p.get('title')
time = p.select_one('.time').text
print(time, title, url)
return news_all
getAllComments('https://news.ltn.com.tw/list/breakingnews')
方法二:我認為的完整解法:
會這樣下這標題是因為後來我發現,這網頁有陷阱,當你瀏覽網頁往下滾滑鼠時,它會動態帶出新的新聞,代表一開始進到這網頁時的資訊量並不是全部。
因此對於一個網頁爬蟲來說,方法一就不是個好解法,因為沒有把全部的資料都抓回來。
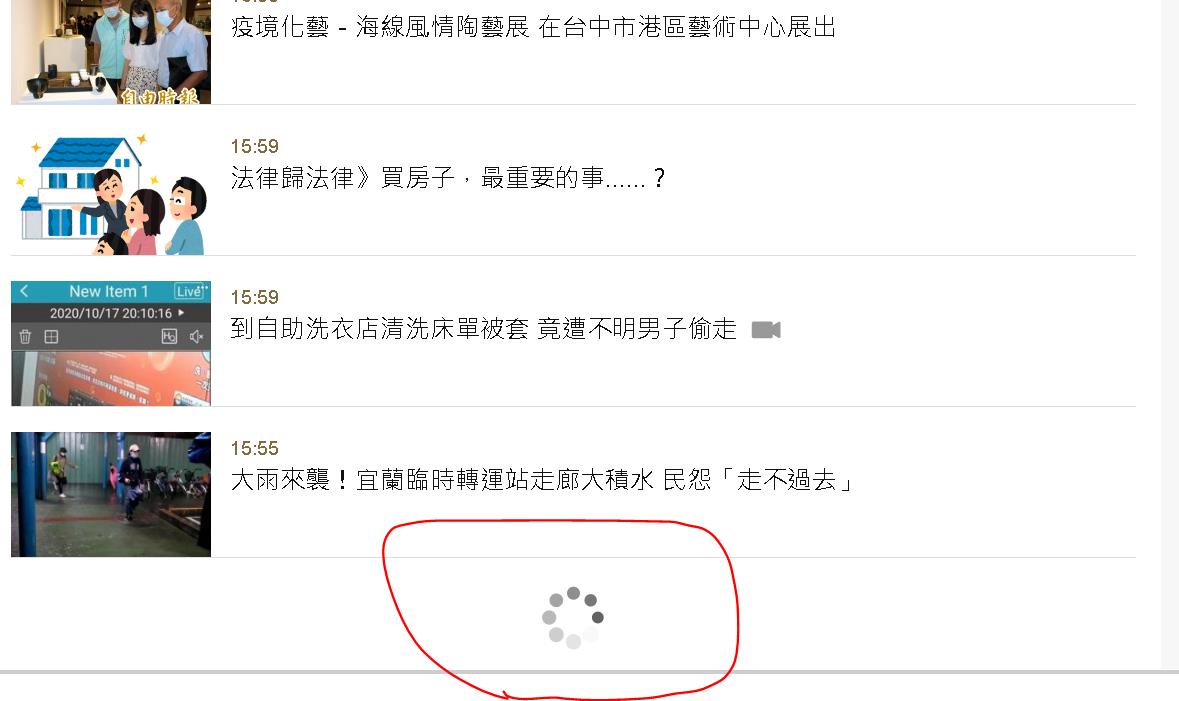
因此方法二的目的就是,將完整的資訊抓回來,我們可以在滑鼠滾輪往下滾的時候觀察 network 的變化,找出其實該網頁是用 API 呼 URL 的方式動態取得資料(https://news.ltn.com.tw/ajax/breakingnews/all/5)。
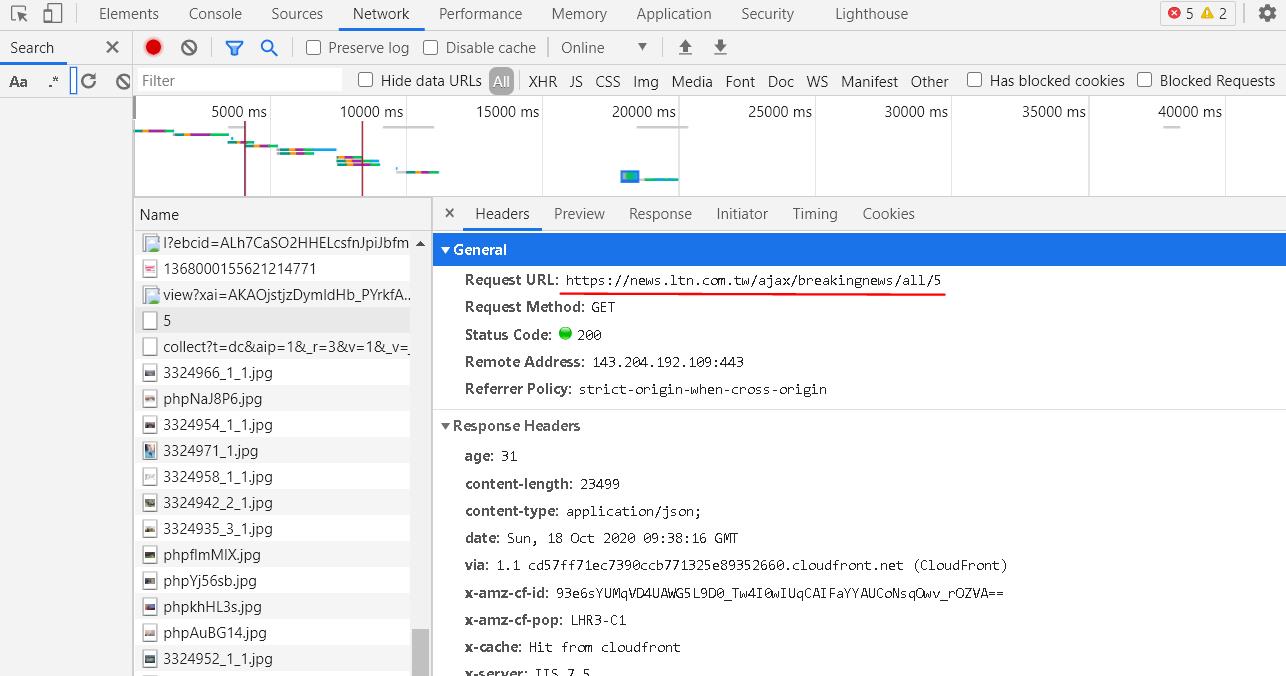
實際測試,只要在 all 後面改變數字就可以取得對應的資料,且格式是 JSON。
但我們並不知道後面的數字需要帶到多大才可以把所有的資料擷取回來,且我發現不同的數字,取回來的資料結構不太一樣,會有兩種格式。
譬如以 https://news.ltn.com.tw/ajax/breakingnews/all/1 和 https://news.ltn.com.tw/ajax/breakingnews/all/2 來說,2 之後的格式都會多帶一個數字字串的 key。
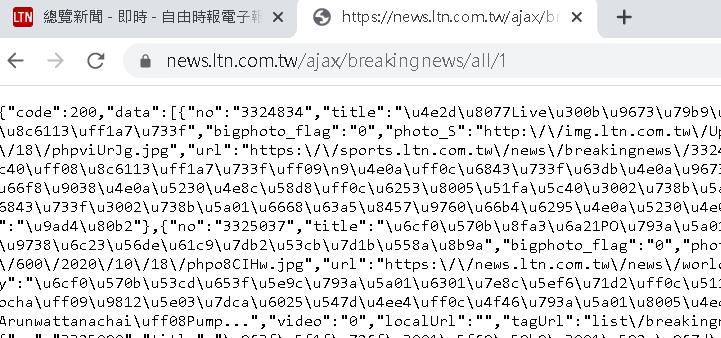
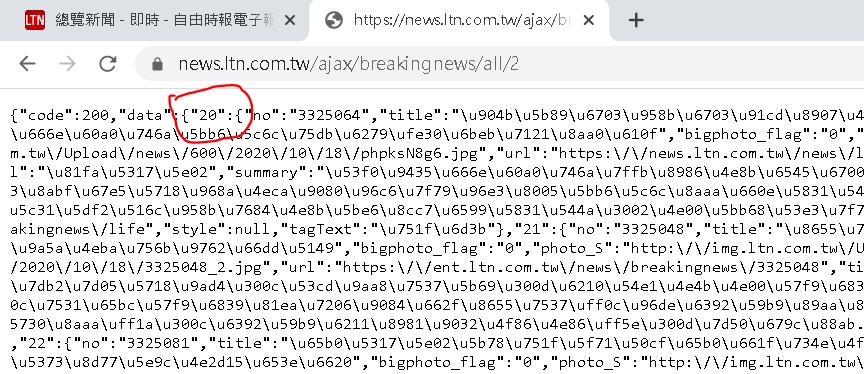
這在取得 data 底下的物件時,第一種會取得 list 物件,第二種會取得 dict 物件,這就是這題的第二個陷阱,因此我們需要在將物件取回後判斷物件格式,用對的方式取得內容。
了解物件回傳格式後我們便可以進行程式的開發,如下圖。
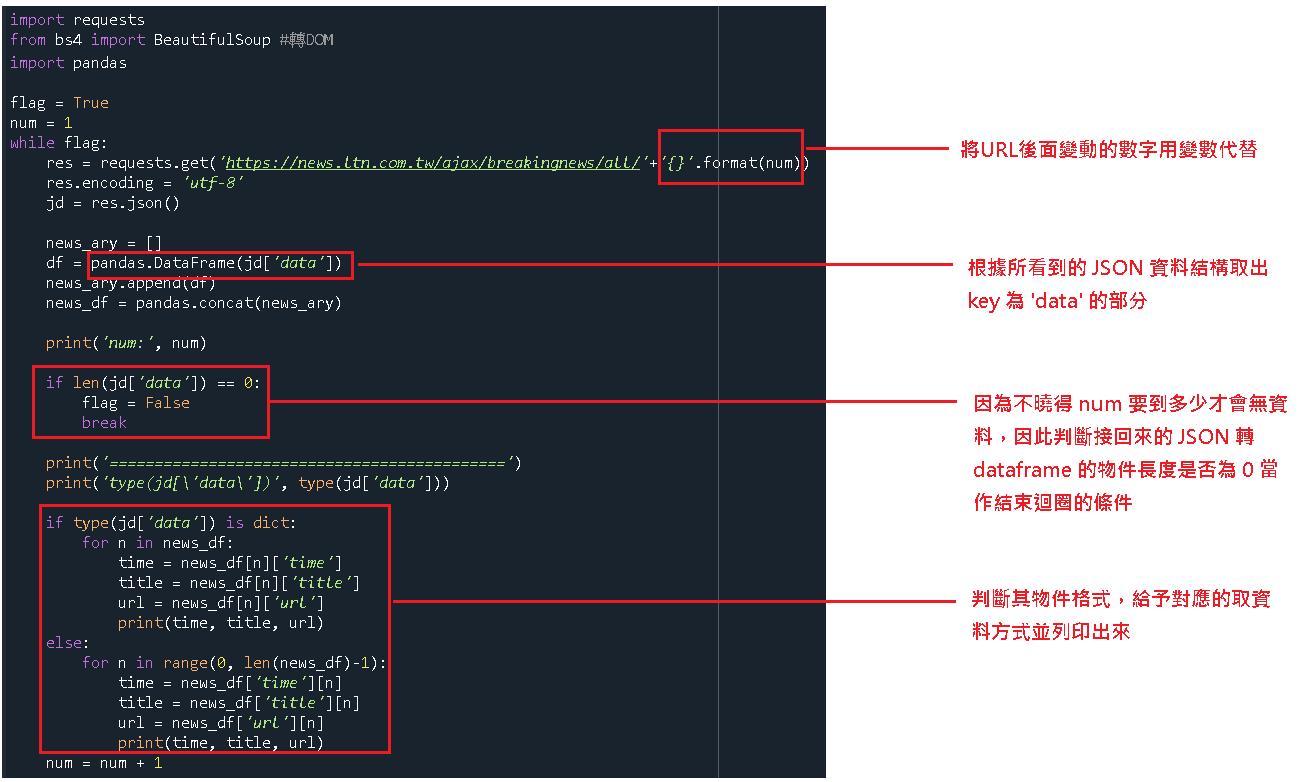
程式碼與執行結果如下。
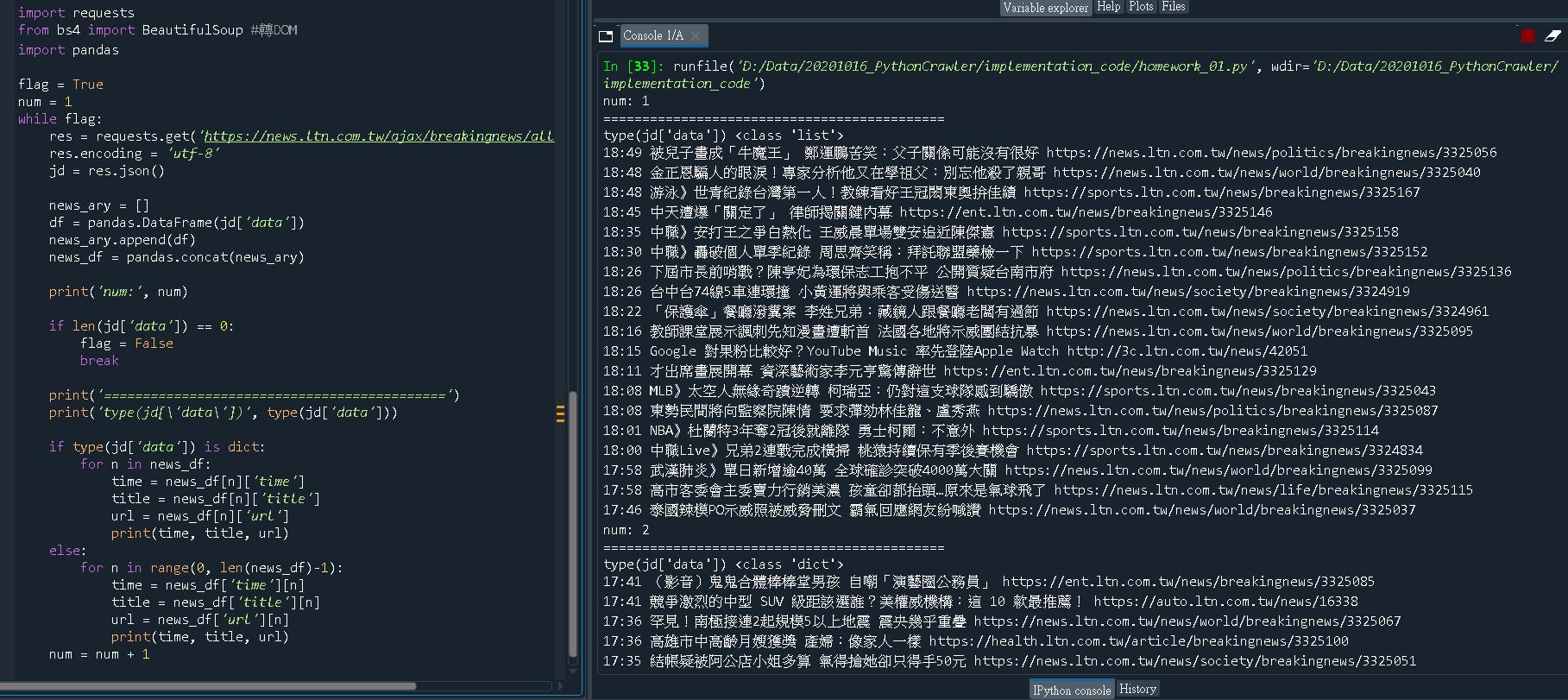
import requests
from bs4 import BeautifulSoup #轉DOM
import pandas
flag = True
num = 1
while flag:
res = requests.get('https://news.ltn.com.tw/ajax/breakingnews/all/'+'{}'.format(num))
res.encoding = 'utf-8'
jd = res.json()
news_ary = []
df = pandas.DataFrame(jd['data'])
news_ary.append(df)
news_df = pandas.concat(news_ary)
print('num:', num)
if len(jd['data']) == 0:
flag = False
break
print('============================================')
print('type(jd[\'data\'])', type(jd['data']))
if type(jd['data']) is dict:
for n in news_df:
time = news_df[n]['time']
title = news_df[n]['title']
url = news_df[n]['url']
print(time, title, url)
else:
for n in range(0, len(news_df)-1):
time = news_df['time'][n]
title = news_df['title'][n]
url = news_df['url'][n]
print(time, title, url)
num = num + 1