YoloV4、Ubuntu、Jetson Nano、Object Detection、Object Tracking、Centroid Tracking、Tensorrt、Cuda、Cudnn、People Counting。
緣起
在人工智慧學校的時候,技術長表示人流計數這個題目在他們看來是蛋糕一片,因此要求我們這組必須額外增加功能或將功能實作到 Edge Device 上,也因為剛好學校有設備可以提供,我們最後選擇了實作在 Edge 上,孰不知這個選擇讓整個專題難度從5變成10(假設難度由易到難是1~10),加上我們這組只有3個人,指導的助教也不是 Jetson nano 派專長,我們三個差點畢不了業。4/10畢業,我一路從2/28連假崩潰到畢業前一個星期,這對於 Coding 能力本來就不弱的我無疑是一大打擊,原來這世上還是有程式能力強卻無法跨越的門檻。最後是開了10倍界王拳把東西趕出來達到及格邊緣…
筆記開始
在我實作方法的前提下我認為要實作人流計算必須要達到幾個要件:
- 準確率不差的物件偵測模組
- 有效的物件追蹤模組(我在這邊是用 Centroid Tracking)
- 能夠客製化人流計算邊線的能力
物件偵測準確才能在連續的 frame 偵測中保持行人偵測外框穩定呈現,避免影響物件追蹤模組的計算,準確率太差會造成預測的框與 ground truth 的框距離差太多、跳動或是偵測框時有時無導致物件追蹤的配對出問題。
物件追蹤其實指的就是 frame 與 frame 之間的行人 re-id 作業,前一張出現的行人,在下一張分別是那些行人的配對,藉由找出這樣的關係,就能夠搭配自己畫的線判斷是不是有跨越,進而計算人數。然而經過我們的驗證與網路上大家實作的結果,在物件追蹤部分其實會占掉最多的計算時間(因為要做 feature extraction 進行配對),我們也是到畢業前夕才發現在 jetson nano 上要實作這功能根本會不能用…FPS 0.3 低的可憐(https://spyjetson.blogspot.com/2020/06/jetson-nano-yolov4-object-tracking.html?m=1)

因此我退而求其次,物件追蹤模組我改以 Centroid Tracking 取代,大幅度提升 FPS 至25上下,幾乎達到 near realtime(https://www.pyimagesearch.com/2018/08/13/opencv-people-counter/)。不過我只用了他 id 配對的部分,counting 的線和計算是我自己寫的(因為我發現他的 counting 有 bug),但這種簡單的方法會有一些缺點例如 id switch,攝影機的角度與環境必須單純一點比較不會發生。
程式流程大概是這樣:
while(true):
img = cv2.read() #讀取影像
boxes, confs, clss = trt_yolo.detect(img, conf_th) #使用yolo推論
objects = CentroidTracker.update(boxes) #根據推論結果分配id
for (objectID, centroid) in objects.items():
→ compare previous and current #比較同一個id前一個記錄位置與現在位置
→ counting #依據平面點線關係計算counting
key = cv2.waitKey(1)
if key == 27:
break
除了偵測人流,我們也希望能夠紀錄畫面上那些族群會停留在我們希望偵測的區域,因此需要擷取人臉做性別年齡的計算,因此我們 Yolo 模組需求就變成要偵測行人+人臉,為了達到這個目的我們使用了 crowdHuman 資料集(https://github.com/jkjung-avt/yolov4_crowdhuman)用 darknet(https://github.com/AlexeyAB/darknet)進行 training。
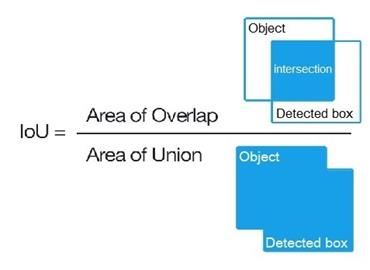
Yolo 的評估標準是看 IOU 與 mAP,使用 ground truth 與預測的 bounding box 之間的交集與聯集分別做計算,並同時評估 IOU 與 MAP,一般來說在 IOU 高於0.5的情況下 MAP 也要高於0.5,表示成 mAP@0.5。
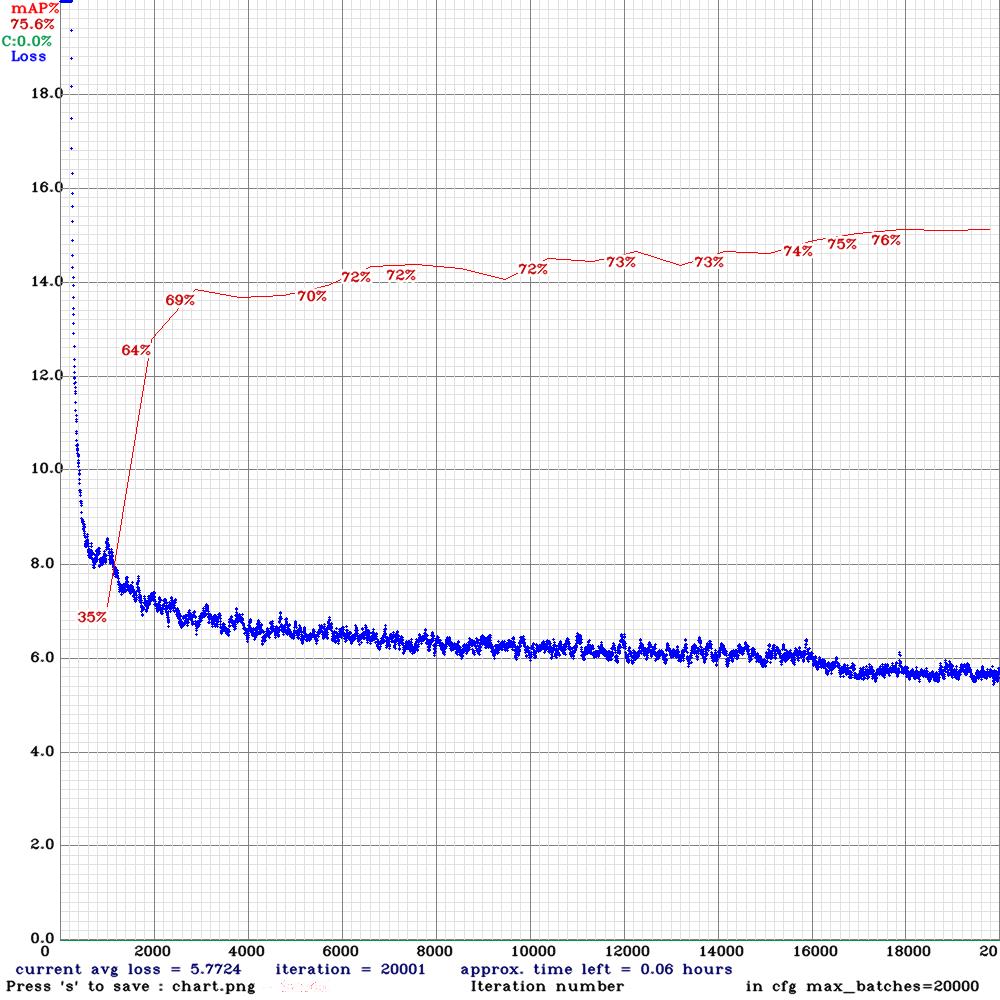
我選了幾個 pre-trained weight 進行 yolov4-tiny 的 training,最後選用 conv.29 的 model 轉成 tensorrt 的格式增加推論速度,到後面我是用我自己架的機器用 nvidia MX150 顯卡硬 train(因為我在做這段時我已從 人工智慧學校畢業,無 training 資源可用),附帶一提,我 train 的 yolov4-tiny 是3層 yolo layer,不是一般的2層,所以 MAP 會比較高。
| Pre-trained weight | head AP | person AP | mAP | mIOU |
| yolov4.conv.137 | 74.33% | 65.59% | 69.96% | 54.68% |
| yolov4-csp.conv.142 | 77.64% | 69.67% | 73.65% | 57.91% |
| yolov4-tiny.conv.29 | 78.94% | 72.26% | 75.60% | 60.35% |
| Yolov4-tiny-origin-weights | 78.30% | 71.35% | 74.82% | 58.81% |

將重新訓練好的模型實際應用到系統上計算人流,並增加特定區域人數偵測,可以看到在遠處的行人偵測上有更好的效果(這個 FPS 是在我自己的 ubuntu 上實現的,不是在 Jetson Nano 上),原本計算人流的線由1條變成2條,這是為了克服 tiny 模型在準度上的缺陷(推論速度快但準度較差),預測的框變動太大導致質心不斷跳動,人在經過線時有可能因為質心跳動而誤算。

心得與後記
從學校畢業後,我一直想要把 Centroid Tracking 換成其他可以轉成 tensorrt 的模型做 re-id,現在仍在努力中。
我在學校後期其實一直很擔心畢業後我沒有環境可以繼續學習摸索,我知道 google 的 colab 可以用,但他有時間限制,且一旦發現你是拿來 training 模型,會被鎖幾個小時不能用,非常不方便,幸好我在畢業前兩天終於自己在 ubuntu 的環境下把 CUDA 相關的環境做好,今天才有這篇網誌的誕生(我本來要跟 Jacky 助教要環境的 img 我拿回家直接裝,但他說他都用 docker 直接弄,他自己也沒有像我這樣裝過…)
感謝我的組長與另一位組員在這期間不斷給我鼓勵與點子,也感謝 Jacky 助教在過程中的指導(他不是我們這組的助教,但我們卻一直煩他XD),我們才能順利畢業。
就結果來說也許呈現上沒有其他組來的好,但就學習到的東西來說,我們可是比別組多很多,畢竟踩了一堆坑嘛,變強不會是偶然,是必然。