環境與工具準備如下:
- 一個Hadoop的環境with Spark 2.4(Ubuntu)。
- Flume:apache-flume-1.9.0-bin.tar.gz → 用來模擬將資料傳到kafka topic。
- Kafka Server:confluent-7.0.1 → 建立 kafka。
- Jar包:kafka-clients-3.0.0.jar、spark-streaming-kafka-0-10_2.11-2.4.8.jar → 執行與編譯Spark Streaming程式用。
- Spark執行檔:spark-2.4.5-bin-hadoop2.7.tgz → 驅動Spark-Submit。
架構簡述
為了取代原本資料介接使用單純寫程式拉SFTP抓實體檔案進HDFS的方式(直傳技術可參考https://dotblogs.com.tw/Ryuichi/2020/11/07/175134),我開始研究使用kafka做串流介接。
網路上的kafka資訊太多了,也並不是每個都合用,真的要非常深入了解的話其實要看不少文件。
身為一個kafka初學者,以完成功能實作為優先目的,花了一些時間理解kafka的架設與運作原理後,我依據需求畫了一張簡圖如下:
簡單來說就是利用Flume將已落地的文字檔弄成串流上到kafka的topic內,再藉由hadoop叢集的力量啟spark streaming程式將資料傳進HDFS。
Producer端會選擇使用flume是因為實際工作上會用到的場景,上游端只會提供落地的檔案,這對於要實現串流其實是很大的麻煩。
Kafka實現串流會down到文字檔的每一個record,我們當然可以自行撰寫producer去讀取檔案內容後塞到topic裡面這沒有問題。
但實務上當上游產檔時,下游接資料端要把資料塞到topic就可能會遇到上游檔案正在寫,下游又同時在讀的冏境。
Flume可以幫忙解決檔案變化的問題,讓我們可以專心的實現consumer端spark streaming的程式。
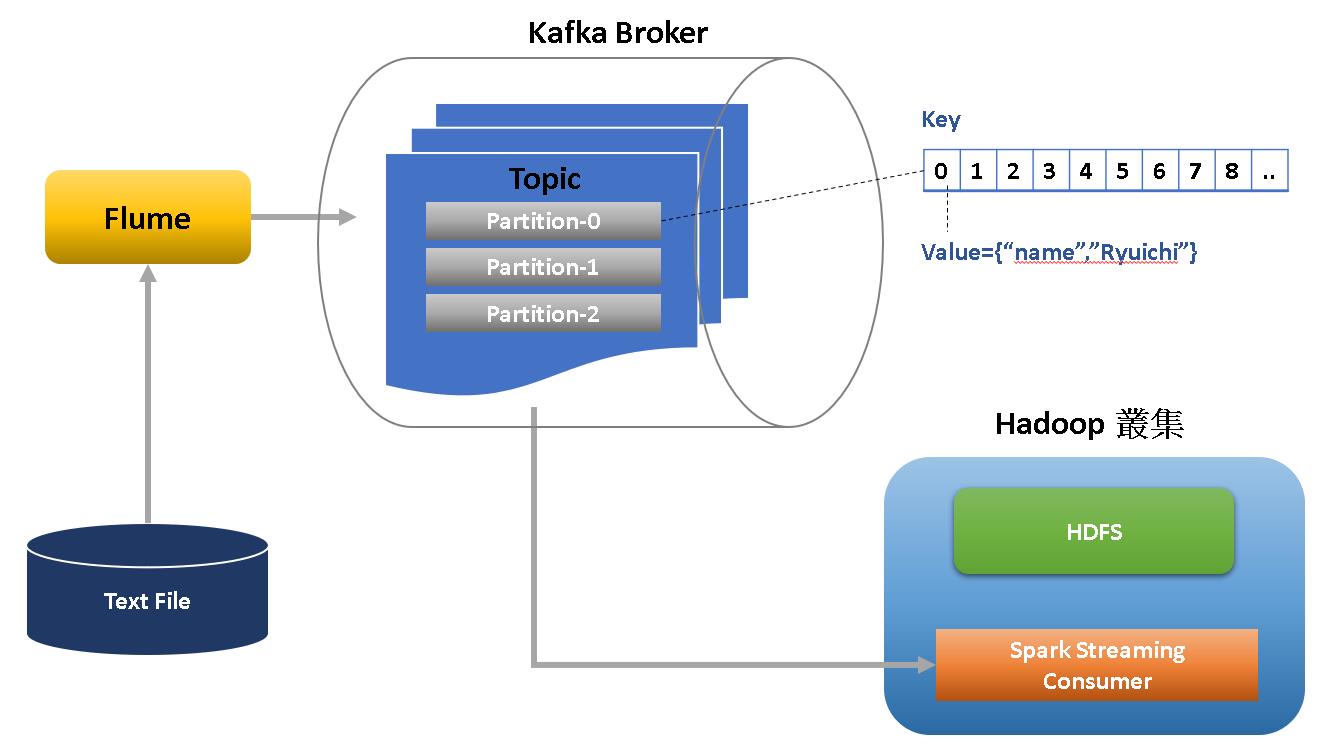
Kafka Server(或是稱作broker)上可以存在很多個topic,每個topic裡面可以拆分多個partition用以儲存producer提供的record。
每個partition上有key和value,key就類似index的概念。
consumer在處理時會依據index開始與結束將資料取出後做commit確認,下次再發動消費時則從上次結束的index往後拉取資料。
Consumer可以設定enavle.auto.commit為false,並在程式完成後加上stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)做commit動作。
下一段將簡述flume與kafka server的設定與啟用,接著介紹實作spark streaming的程式。
實作內容
為了介紹流程順暢,我會先建置kafka server,接著設定flume將資料送到topic,最後才會用spark streaming的方式將資料轉至HDFS。
Kafka Server(Broker)
至Confluent官方網站找到連結http://packages.confluent.io/archive/7.0/confluent-community-7.0.1.zip
將zip檔下載下來解壓縮後放在喜歡的位置,我這邊示範放的位置為/media/hduser/Backup/confluent-7.0.1/。
請確定你的環境內有裝java,接著輸入指令啟動zookeeper。
sh /media/hduser/Backup/confluent-7.0.1/bin/zookeeper-server-start /media/hduser/Backup/confluent-7.0.1/etc/kafka/zookeeper.properties
zookeeper啟動後,接著啟動kafka broker,一樣會跳出一堆巴拉巴拉的訊息。
sh /media/hduser/Backup/confluent-7.0.1/bin/kafka-server-start /media/hduser/Backup/confluent-7.0.1/etc/kafka/server.properties
啟動完成後輸入指令建立kafka topic,我這邊建立的topic名稱為ryuichiTopic,partition數量為6。
sh /media/hduser/Backup/confluent-7.0.1/bin/kafka-topics --create --bootstrap-server localhost:9092 --topic ryuichiTopic --partitions 6
*****刪除指令為sh /media/hduser/Backup/confluent-7.0.1/bin/kafka-topics --delete --bootstrap-server localhost:9092 --topic ryuichiTopic
Kafka server的預設port是9092,因為我們的zookeeper和broker都是起在同一台linux,因此IP部分設定localhost即可。
到這裡,一個單機版single node的kafka server的設定與建置就完成了。

Flume
我們將flume與kafka server放在同一台linux上。
首先準備要讓flume上傳到topic的實體檔案,將其放置在/media/hduser/Backup/flumeData/demand.csv。
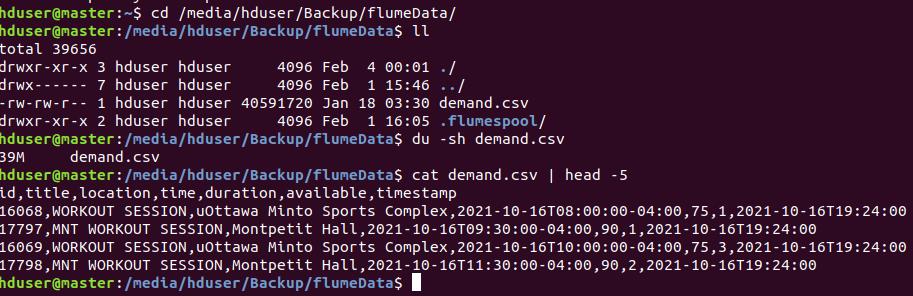
接著至flume官方網站找到下載連結https://dlcdn.apache.org/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
將gz檔下載下來解壓縮後放在喜歡的位置,我這邊示範放的位置為/media/hduser/Backup/apache-flume-1.9.0-bin。
新增/media/hduser/Backup/apache-flume-1.9.0-bin/conf/flume.conf設定檔,設定內容如下:
#
# Flume Conf
#
a1.sources = s1
a1.sinks = k1
a1.channels = c1
# spooldir
a1.sources.s1.type = spooldir
a1.sources.s1.spoolDir = /media/hduser/Backup/flumeData
a1.sources.s1.deserializer.MaxLineLength = 10000
# Kafka Sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = ryuichiTopic
a1.sinks.k1.brokerList = localhost:9092
#指定client.id用以搭配kafka broker端producer_byte_rate做流速限制
#a1.sinks.k1.kafka.producer.client.id = clientA
a1.sinks.k1.batchSize = 5
a1.sinks.k1.flumeBatchSize = 100
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
接著輸入指令啟動flume。
bin/flume-ng agent --conf ./conf/ -f conf/flume.conf -n a1 -Dflume.root.logger=INFO,console
啟動後,會看到flume將剛剛的demand.csv檔上傳topic處理完畢。

Spark Streaming Consumer
在這裡我利用scala版eclipse開發一個spark streaming的程式,包成jar檔後使用spark-submit送到hadoop叢集去執行。
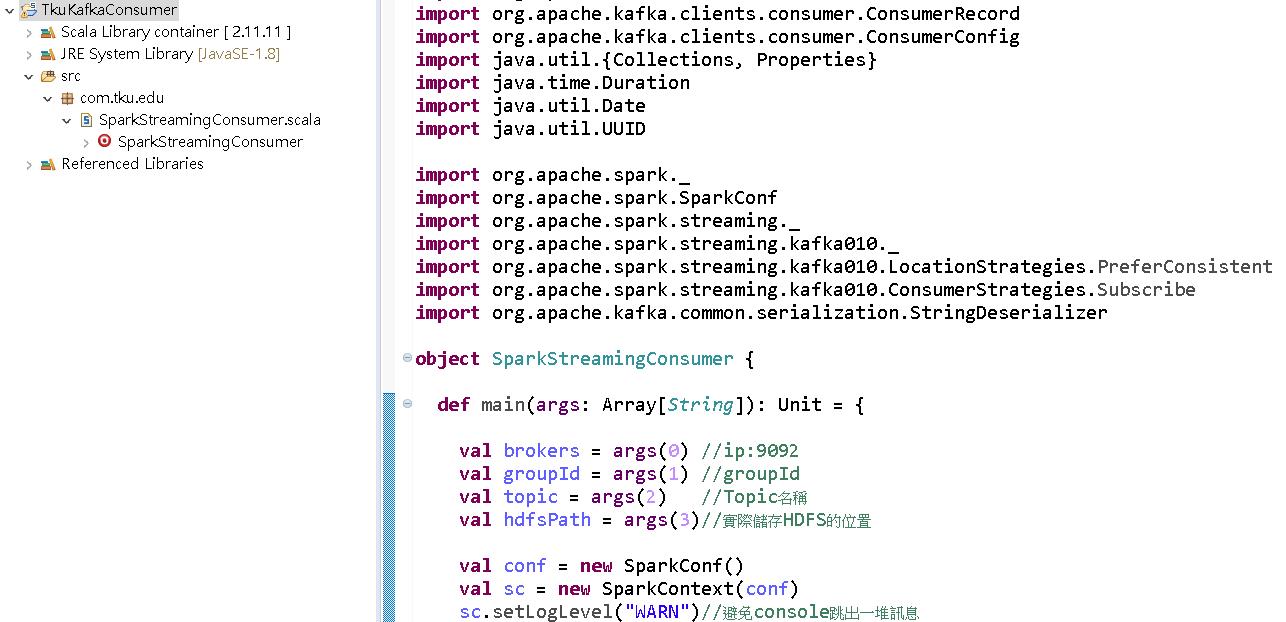
完整程式如下:
package com.tku.edu
import org.apache.kafka.clients.consumer.KafkaConsumer
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.clients.consumer.ConsumerConfig
import java.util.{Collections, Properties}
import java.time.Duration
import java.util.Date
import java.util.UUID
import org.apache.spark._
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.kafka.common.serialization.StringDeserializer
object SparkStreamingConsumer {
def main(args: Array[String]): Unit = {
val brokers = args(0) //ip:9092
val groupId = args(1) //groupId
val topic = args(2) //Topic名稱
val hdfsPath = args(3)//實際儲存HDFS的位置
val conf = new SparkConf()
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")//避免console跳出一堆訊息
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
val ssc = new StreamingContext(sc, Seconds(10))
val kafkaParams = Map[String, Object] (
"bootstrap.servers" -> brokers,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> groupId,//Topic內的訊息可提供給多個groupId內的單一consumer
"auto.offset.reset" -> "earliest",
"enavle.auto.commit" -> (false: java.lang.Boolean)//關閉自動commit,由我們自己控制commit時機
//"fetch.min.bytes" -> "26214400",//累積最少獲得之檔案大小25M,
//"fetch.max.wait.ms" -> "5",//獲得最少檔案累積大小最等待時間,
//"client.id" -> clientId//指定client.id用以搭配kafka broker端consumer_byte_rate做流速限制
)
val topics = Array(topic)
val stream = KafkaUtils.createDirectStream[String, String] (
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
var offsetRanges: Array[OffsetRange] = Array.empty[OffsetRange]
//轉換stream to RDD
stream.transform( rdd => {
//利用transform取得OffsetRamges
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}
).foreachRDD { streamRdd =>
var start_time = new Date().getTime
if(!streamRdd.isEmpty()) {
val uuid = UUID.randomUUID().toString()
val fileName = hdfsPath + "/" + uuid
for(offsetRange <- offsetRanges) {
println("***Partition-" + offsetRange.partition + "開始執行, "+ offsetRange.fromOffset + "~" + offsetRange.untilOffset)
}
streamRdd.saveAsTextFile("hdfs:///" + fileName)
//commitAsync() API用於提交offset
for(offsetRange <- offsetRanges) {
println("***Partition-" + offsetRange.partition + "執行完畢, "+ offsetRange.fromOffset + "~" + offsetRange.untilOffset)
}
//存最源頭stream
stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
}
var end_time = new Date().getTime
println("執行時間:"+(end_time-start_time)+"毫秒")
}
ssc.start()
ssc.awaitTermination()
}
}程式內設定了kafka相關的參數,其關鍵的參數作用皆在後面的註解有說明。
同時我將streaming處理時的offset變化,在foreachRDD裡面顯示出來,可以更清楚的知道目前程式分別處理到哪個partition的哪個key。
並且將處理完的結果用一個uuid當作路徑儲存起來。
輸出jar檔後,我們便可以寫一個shell去執行這個jar檔。
先至官方連結下載spark的包https://archive.apache.org/dist/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz
下載下來解壓縮後放在喜歡的位置,我這邊示範放的位置為/home/hduser/Downloads/spark-2.4.5-bin-hadoop2.7。
至maven網站下載kafka-clients-3.0.0.jar、spark-streaming-kafka-0-10_2.11-2.4.8.jar,用於執行時引用。
spark-submit執行的程式碼如下:
export HADOOP_USER_NAME=hdfs
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
cd /home/hduser/Desktop
/home/hduser/Downloads/spark-2.4.5-bin-hadoop2.7/bin/spark-submit \
--jars /home/hduser/Desktop/kafka-clients-3.0.0.jar,/home/hduser/Desktop/spark-streaming-kafka-0-10_2.11-2.4.8.jar \
--class com.tku.edu.SparkStreamingConsumer \
--master yarn \
--deploy-mode client \
--num-executors 1 \
--executor-memory 1g \
--executor-cores 1 \
--driver-memory 1g \
--driver-cores 1 \
--deploy-mode client \
/home/hduser/Desktop/TkuKafkaConsumer.jar 192.168.159.128:9092 group1 ryuichiTopic /user/hduser/kafkaToHdfs
echo "finish"因為我spark streaming的程式與kafka server是放在不同的機器上,因此IP改成broker所在機器的IP位址。
groupId就隨便指定一個,只要下次再執行時用同一個即可,kafka會去紀錄哪個groupId消費到partition內哪個key。
Spark streaming有兩種消費方式,一種是receive,另一種是directStream,差異可以參考這個網址https://blog.csdn.net/wisgood/article/details/51815853
我這篇技術網誌是使用directStream,同時這也是官方建議的方式,自行管理offset。
執行shell後我們可以看到spark streaming會針對每個partition作拉取的動作。
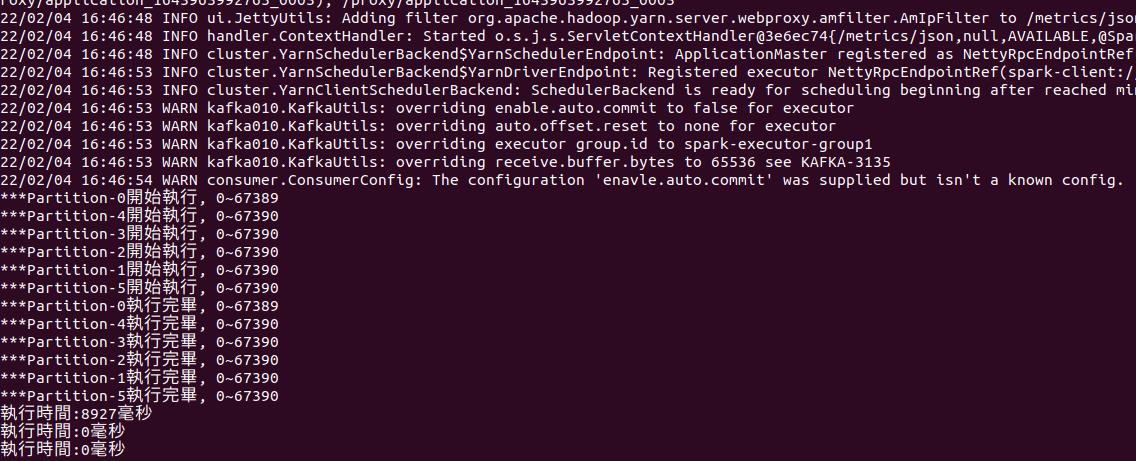
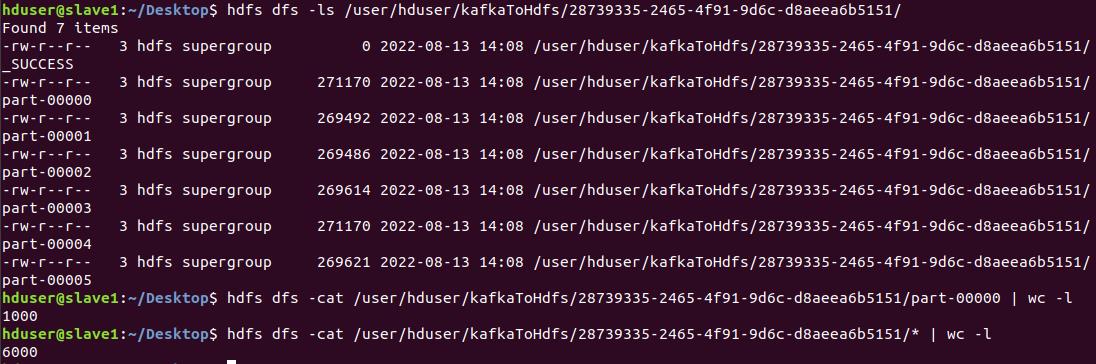
也因為directStream的方式是針對topic內的每一個partition配一個RDD去處理,因此程式處理下來,最後會在我們設定的uuid路徑下產生對應的檔案數。
以我們設定partition為6來說,uuid路徑下就會有6個檔案。
這項技術我實際拿到資源更多的hadoop叢集測試過,partition數與使用的core數設定對應會影響streaming速度(我自己測試是partition數 = num-executors * executor-cores時會最佳)。


至此,flume、kafka與spark streaming的串流scenario實作完成。
同場加映-控制Spark Streaming每個batch抓取的record
實務上用streaming接下來的資料,有可能需要落地或是HDFS讓其他cron job做排程處理。
在沒有設定一次batch抓多少record的情況下,若kafka topic上累積了大量的record沒有消費,spark streaming剛起來抓取時,在第一次抓取時會將這些資料一次抓下來落檔。
這會造成檔案過大導致後續的排程無法以固定的資源做計算,因此需要加入設定去限縮每次可以抓取的最大record量,避免排程執行出問題,也可以掌握每次streaming batch抓取與後續排程處理的時間。
spark streaming有一個可以設定每次抓取record數的參數設定spark.streaming.kafka.maxRatePerPartition,其公式為maxRatePerPartition*streamingContextDuration(batch之間的間隔)*partition_num(topic上partition的數量)=full pool records per batch(每次batch抓取的總數)。
以我們前面的程式的設定,假設我們想要每次batch抓取的總數是6000筆,我們程式內的streamingContextDuration=10(val ssc = new StreamingContext(sc, Seconds(10))),topic的partition為6,則我們的maxRatePerPartition計算就會設定為100,如下列程式shell設定:
export HADOOP_USER_NAME=hdfs
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
cd /home/hduser/Desktop
/home/hduser/Downloads/spark-2.4.5-bin-hadoop2.7/bin/spark-submit \
--jars /home/hduser/Desktop/kafka-clients-3.0.0.jar,/home/hduser/Desktop/spark-streaming-kafka-0-10_2.11-2.4.8.jar \
--class com.tku.edu.SparkStreamingConsumer \
--master yarn \
--deploy-mode client \
--num-executors 1 \
--executor-memory 1g \
--executor-cores 1 \
--driver-memory 1g \
--driver-cores 1 \
--deploy-mode client \
--conf spark.streaming.kafka.maxRatePerPartition=100 \
/home/hduser/Desktop/TkuKafkaConsumer.jar 192.168.159.128:9092 group1 ryuichiTopic /user/hduser/kafkaToHdfs
echo "finish"其執行結果如下,6個partition,每次batch每個partition抓1000筆,總數是6000筆。
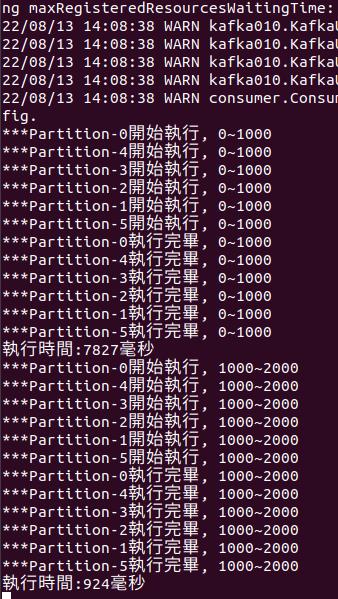
同場加映-讀檔效能調整補充
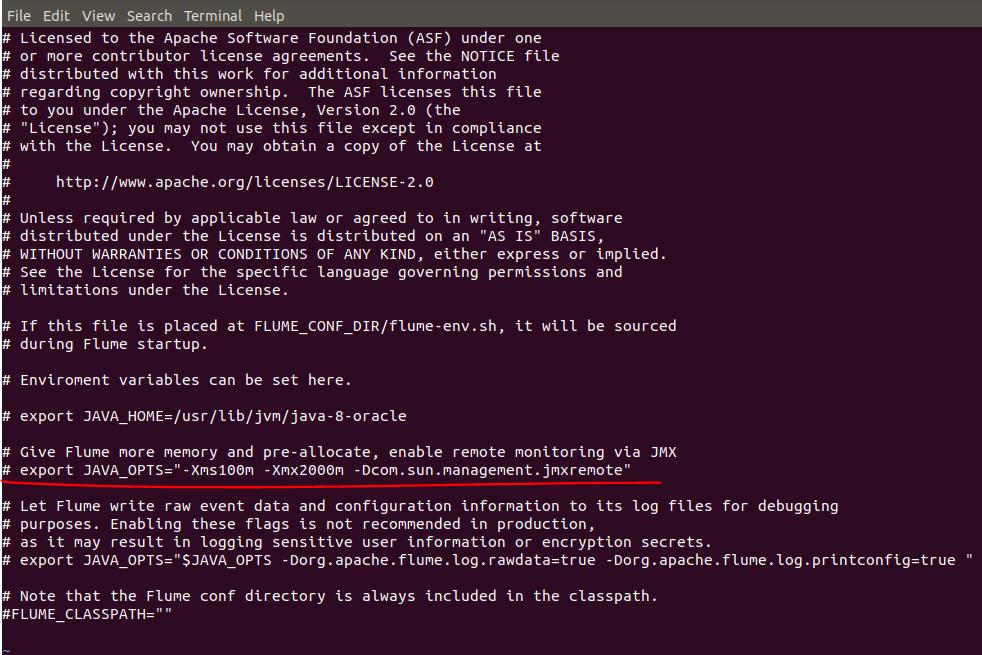
flume讀檔不是multiple thread,是一個一個檔處理,想要加快讀取速度,可以在flume的conf下的flume-env.sh.template,將export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"這段註解打開,放寬記憶體大小,並將檔案名稱修改為flume-env.sh,下次重啟flume即可以載入設定,有效改善讀取速度,增加進入kafka topic的IO。