Label-Studio(圖片標記)、Kaggle(免費GPU訓練環境)、wandb.ai(取得訓練模型時需要用到API Key)、YOLOv8 Ultralytics(物件偵測pretrained model)、powershell(批次更改檔名)。
reference:https://docs.ultralytics.com/、https://wandb.ai/site、https://www.kaggle.com/
前言
以前在人工智慧學校有使用過YoloV4做過人流計數功能,但由於當時課程緊湊的關係,僅將重點放在引入coco dataset後進行模型訓練並應用,對於如何從頭開始對自己客製化的資料產出標記做訓練並無涉略,決定在嘗試後將過程記錄下來。
這篇技術網誌不會有模型的細節探討,只會有簡單粗暴的實作方式,幫助大家快速跨過門檻進入AI模型訓練及使用。
簡單來說就是如下圖,利用物件偵測模型找出圖中的腳踏車。

若您是想對YOLO物件偵測的訓練與使用快速上手,歡迎繼續往下閱讀。
資料與標記環境準備
我們上網使用google搜尋腳踏車圖片,取得圖片共126張,作為標記的資料基礎。
蒐集完後的圖片檔案命名若想要統一,這裡提供一個小tip,使用powershell可將某資料夾下的圖檔統一改名(我這裡是命名為Bicycle{編號}.jpg),code如下
$index = @{ Value = 1 }#起始檔名
Dir *.jpg | %{Rename-Item $_ -NewName ("Bicycle-{0}.jpg" -f $index.Value++)}接著於本機安裝Anaconda後,開啟Anaconda Promt輸入以下指令建立Label Studio的標記環境:
| 用途 | 指令 | |
| 1 | 建立一個虛擬環境命名label-studio-env | conda create --name label-studio-env python==3.8.0 (python不一定要3.8,可依據喜好選擇) |
| 2 | 啟動虛擬環境label-studio-env | conda activate label-studio-env |
| 3 | 用pip安裝label-studio | pip install label-studio |
| 4 | 下指令啟動label-studio | label-studio |
安裝完啟動後進入註冊一個帳號即可使用,建立一個新專案上傳圖檔以及設定標記label即可開始進行標記(Label Studio的使用方法網路上很多,這裡不贅述)。
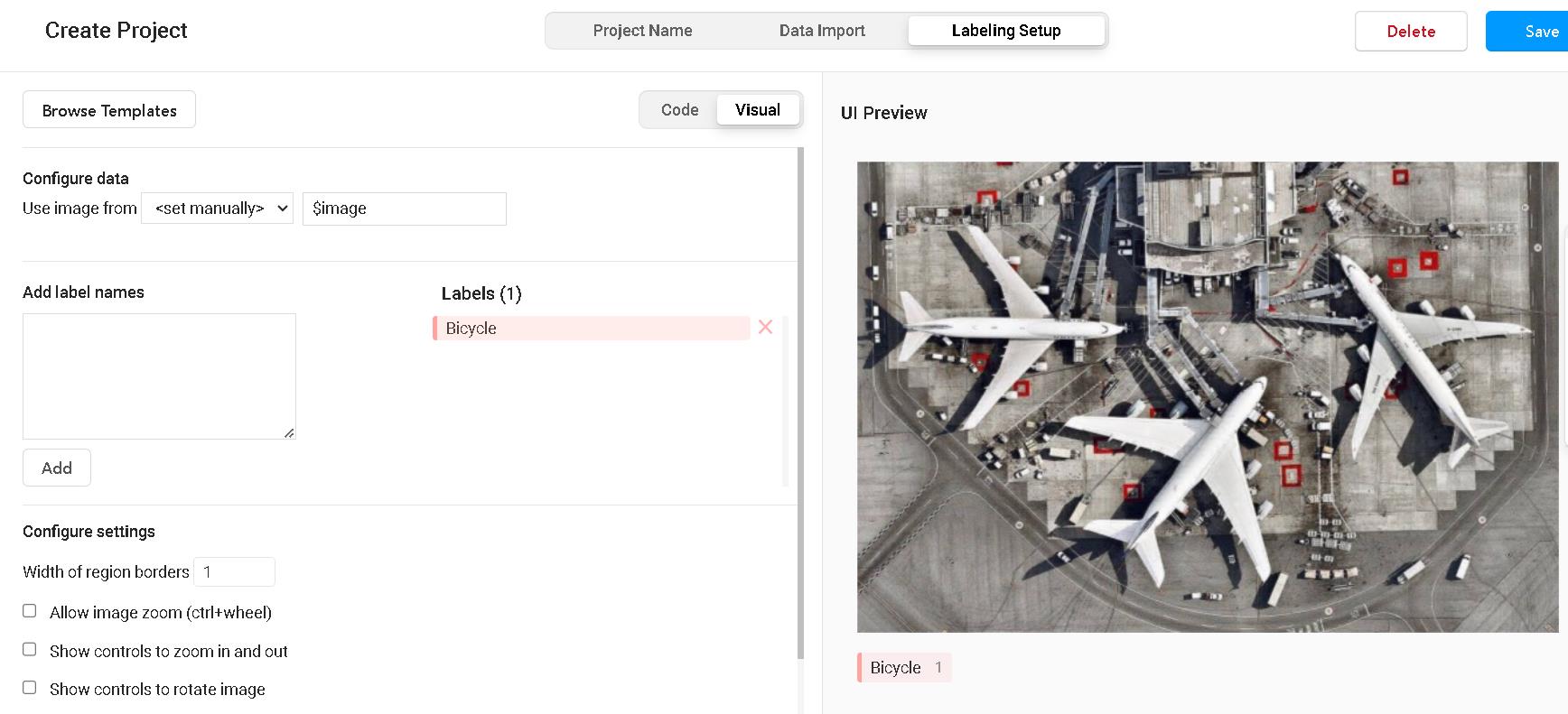
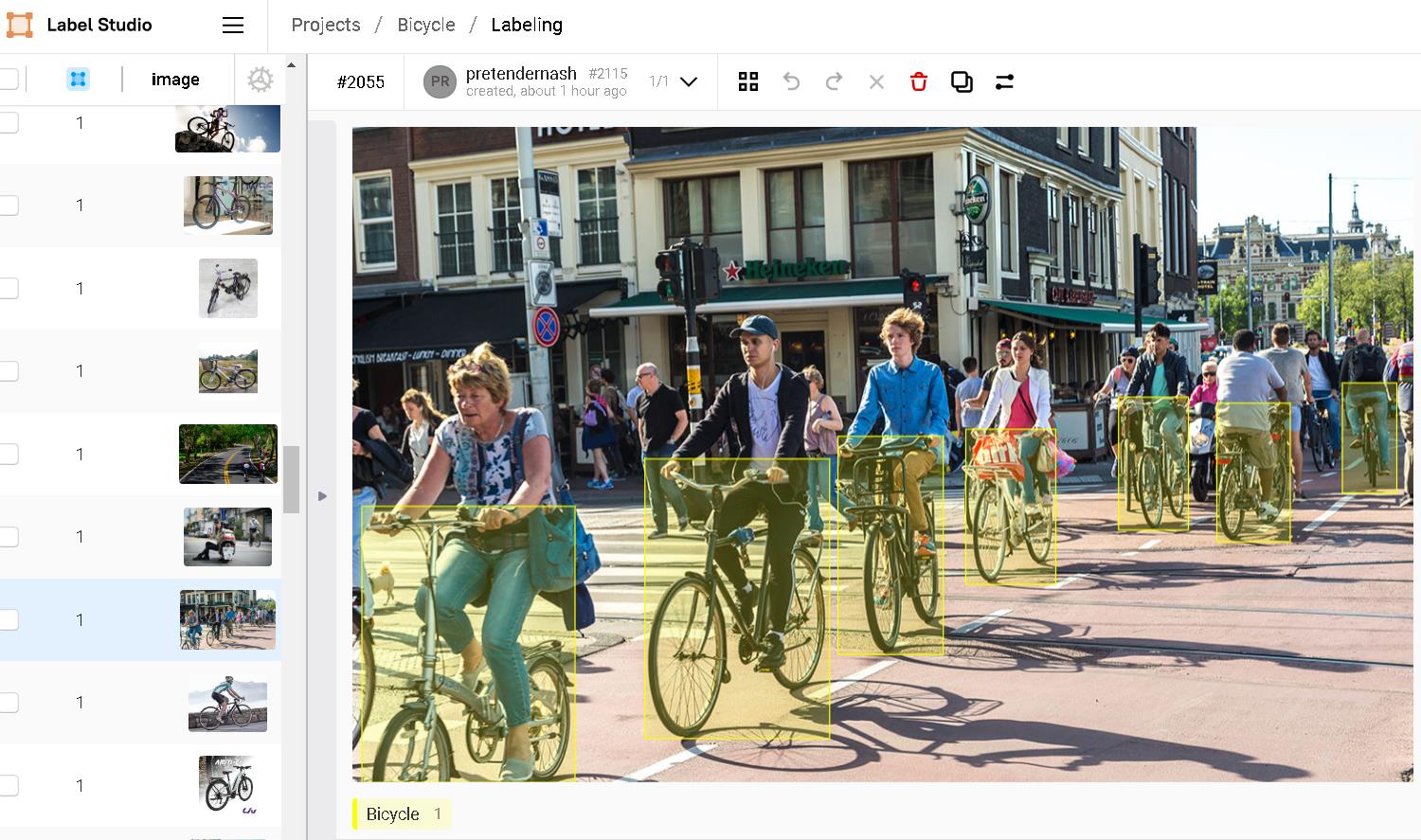
資料標記是整個模型訓練前非常重要的一環,不僅是要精準框定物件的位置,同時資料的多樣性也是為了讓模型學習目標物件背後的背景區域,藉此幫助模型可以更精準的偵測到我們想要的腳踏車物件。
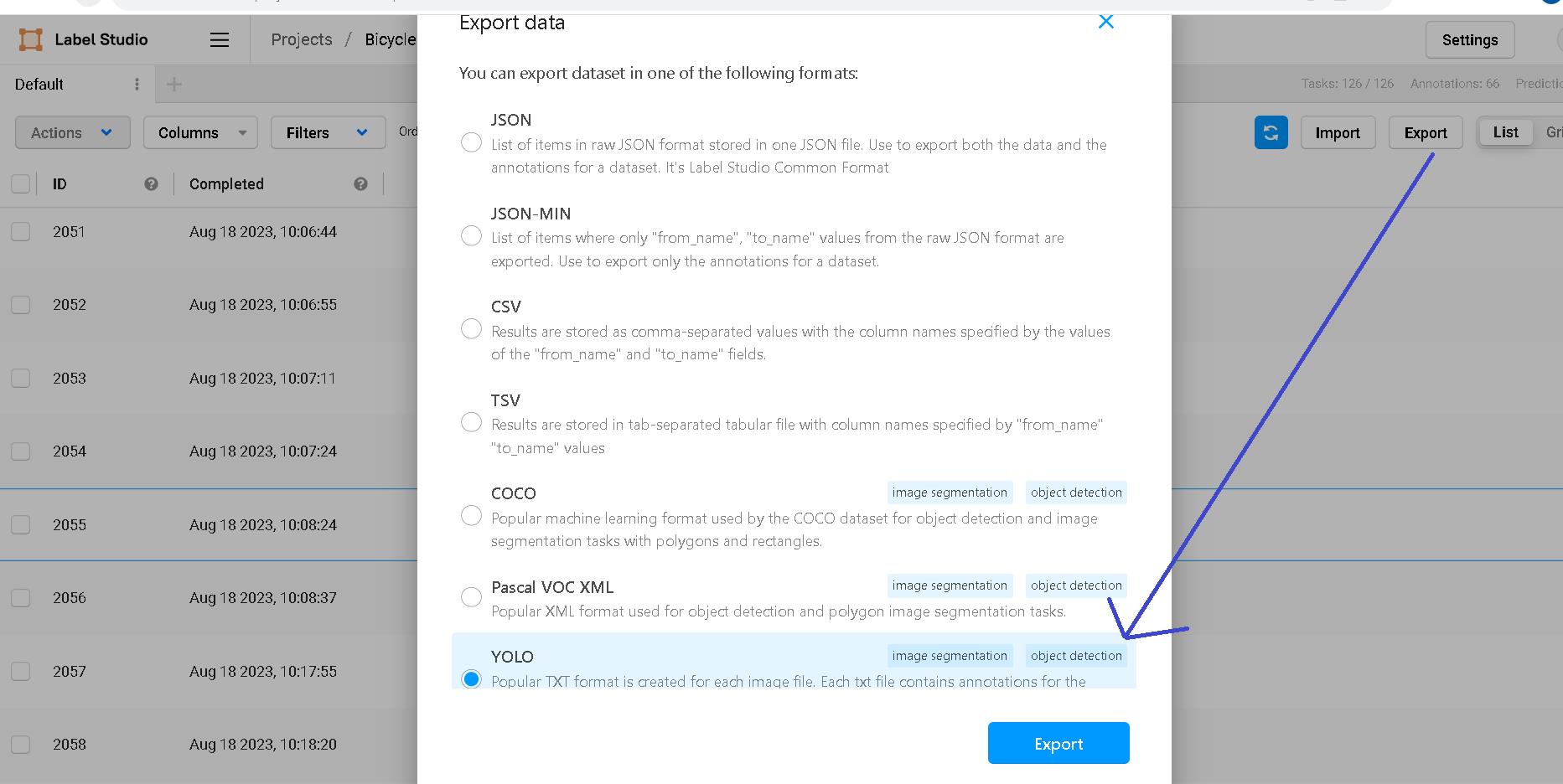
全部標記完後,我們匯出YOLO格式,準備訓練模型時使用。
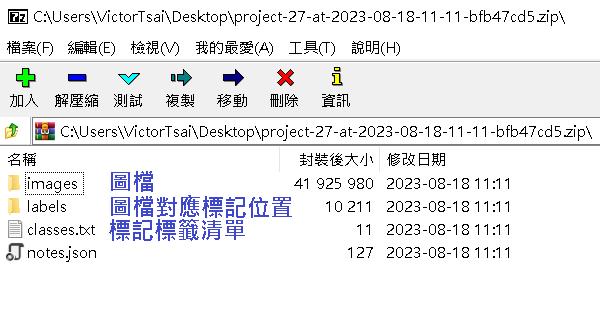
檔案會匯出一個壓縮檔,images資料夾是你蒐集的圖片檔案(已被label studio重新命名過),labels資料夾是每張圖片對應標記的位置,classes.txt是你這個專案標記的標籤清單(我們只有設定一個Bicycle標籤,所以內容只會有一行)
我們調整一下裡面的結構,將images與labels資料夾的內容分成訓練集(101張)與驗證集(25張)=8:2,分別在這兩個資料夾下以train和val兩個資料夾做區分。
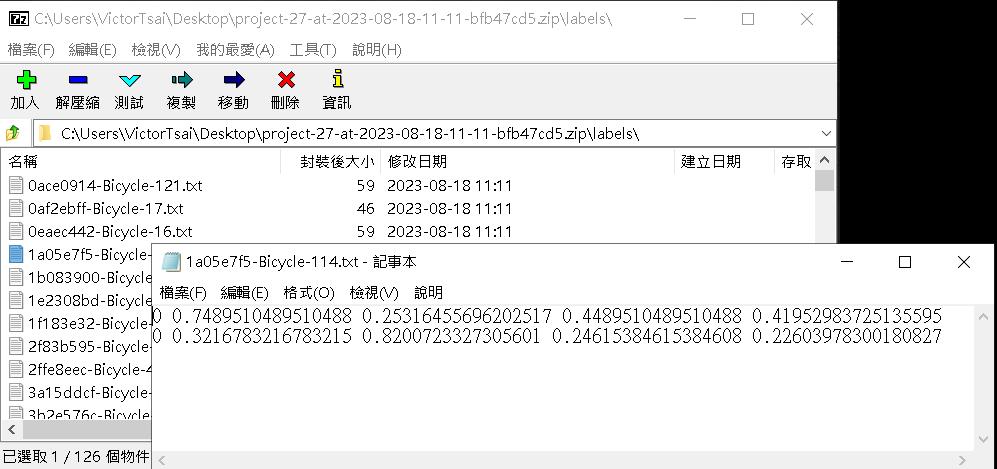
labels裡面的txt內容意義,每一行會有5個值,由左至右分別代表:標記類別index,歸一化後的 x, y 中心座標及歸一化後的w, h,這是要餵給YOLO訓練用的格式,出現兩行代表該張圖片被標註了兩個腳踏車物件。
想詳細了解的可參考李小姐的技術網誌。
資料標記好後,我們準備一個yaml檔,目的是於訓練模型時告知相關的根目錄、圖片路徑與類別標籤。
我們將根目錄設定為/kaggle/input/ai-bicycle-detection/yolov8Ultralytics/AI_Bicycle_Project
這個路徑的意思是我們會在kaggle的環境上上傳dataset,預設路徑會出現在/kaggle/input下,ai-bicycle-detection是我們為上傳的內容所做的命名(下一章節上傳畫面會有),也是路徑字串的一部分。
yolov8Ultralytics與AI_Bicycle_Project則是我們上傳資料集時所包的資料夾名稱,也會出現在路徑裡。
上傳的dataset我們會用壓縮檔的格式上傳(因為kaggle有單個dataset上傳檔案數不可超過1000個的限制,我們改用zip檔上傳,kaggle在收到zip檔之後會自行解壓,日後有遇到資料量大的狀況下也適用)。
yaml檔內容與欲上傳的dataset壓縮檔如下:
# Train/val/test sets as
## 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /kaggle/input/ai-bicycle-detection/yolov8Ultralytics/AI_Bicycle_Project # dataset root dir
train: images/train/ # train images (relative to 'path') 128 images
val: images/val/ # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
names:
0: Bicycle設定使用Kaggle GPU環境訓練模型
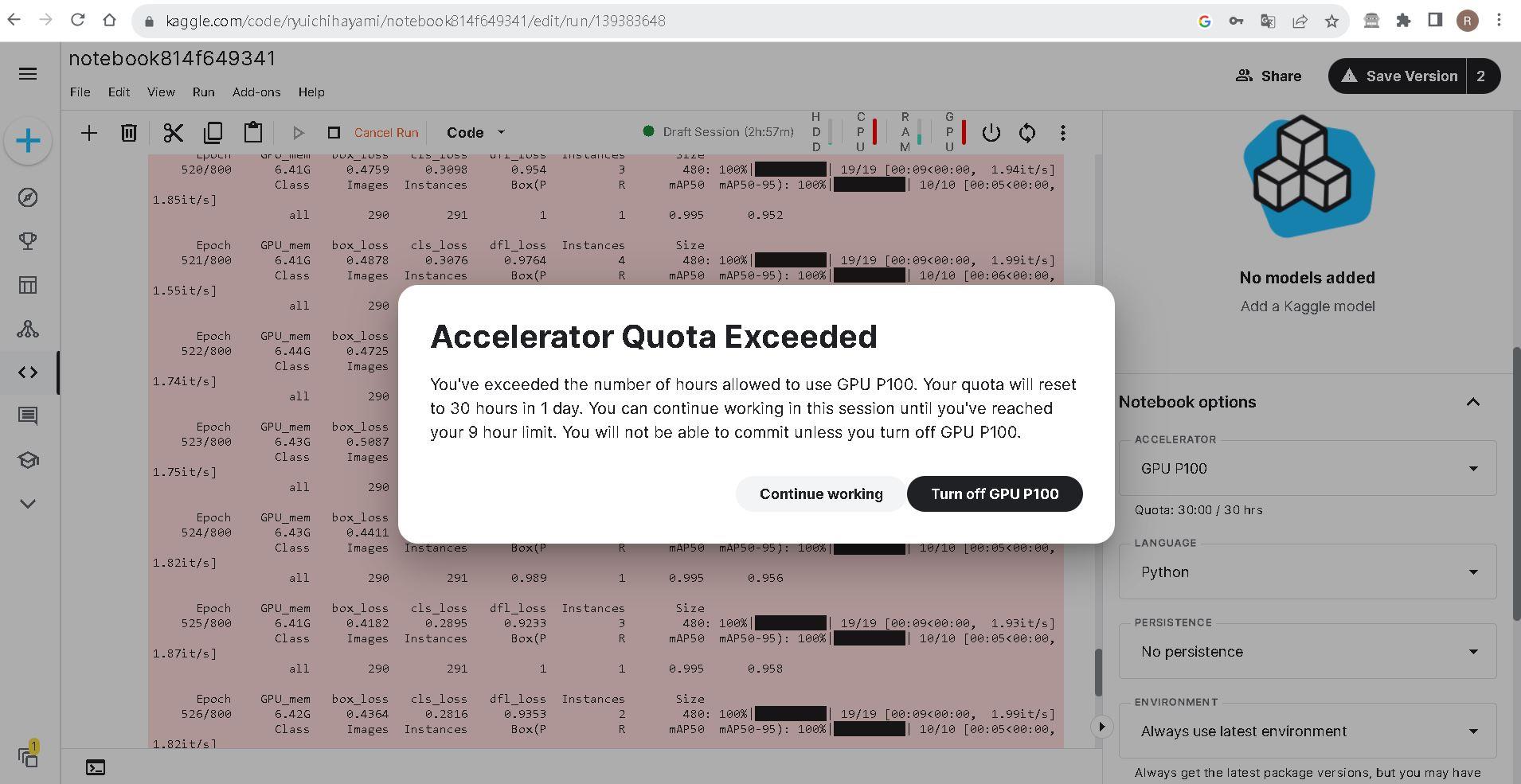
原本我用來訓練的環境是google的colab,但每次在訓練時間使用到2小時29分時就會被強制斷線(或是連線稍微不穩也會斷線),造成訓練結果功虧一簣,途中也會不斷跳"你是否不是機器人"的檢核要你點確認,使用起來非常不方便。
經過評估後改使用Kaggle的GPU環境做訓練,一週有30小時的GPU使用時間(其實很夠用了),訓練期間也不會隨意被中斷(但單一session使用時間也是限制12小時)。
在使用Kaggle訓練之前,請先到 https://wandb.ai/site 這個網站註冊帳號並新增一個project產生API key,實際在跑模型訓練時會使用到。
接著我們到Kaggle註冊一個帳號,並以手機門號認證(有認證過的帳號才可以使用GPU)
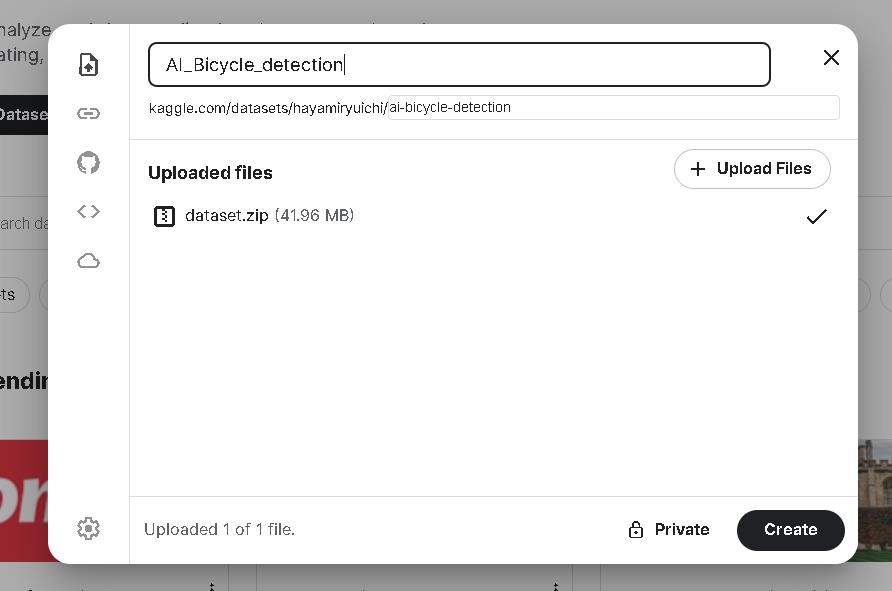
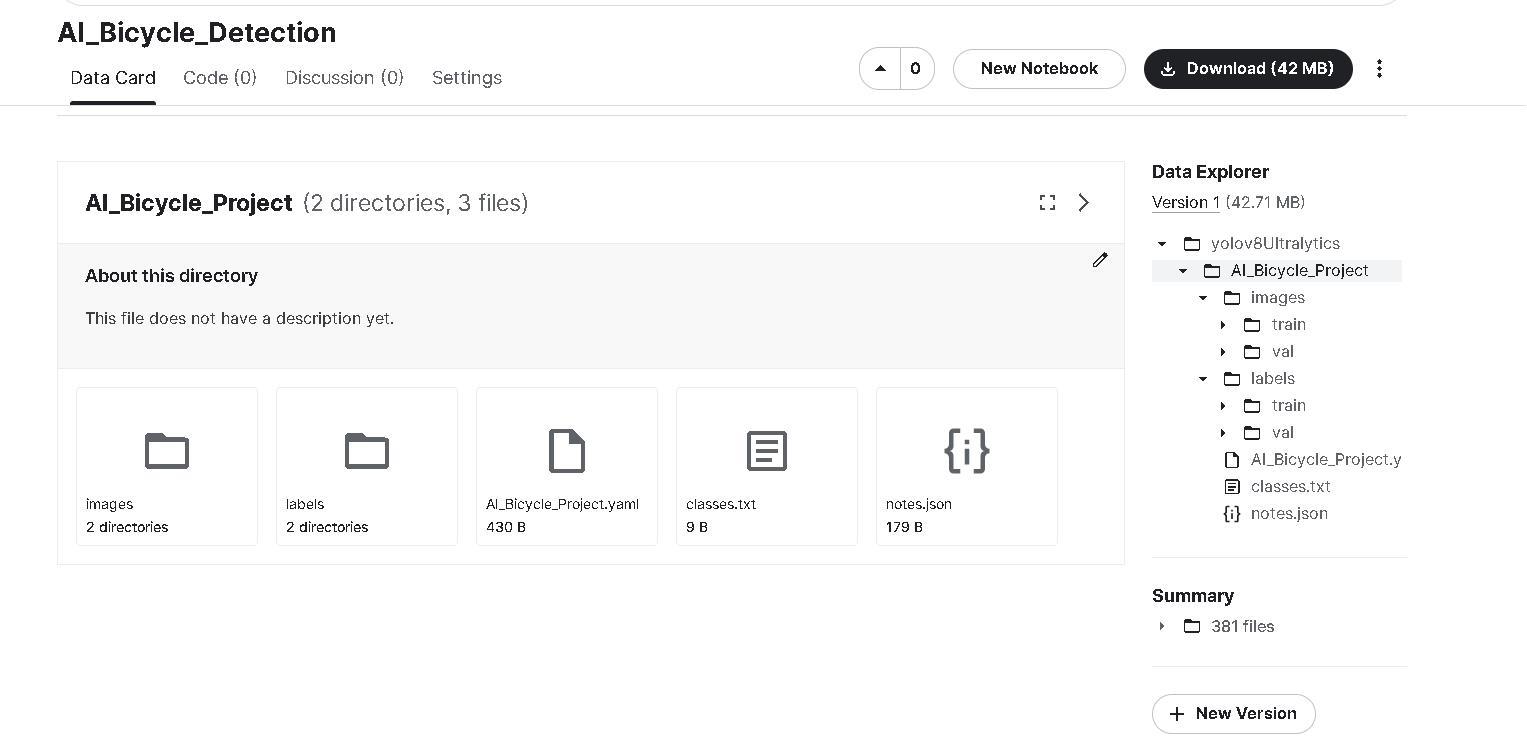
完成後我們先上傳做好的data,將前面做好的dataset.zip直接拖拉上去,設定名稱AI_Bicycle_Detection,上傳完成後可進入dataset頁籤看到資料詳情,可以發現kaggle會自動解壓縮,資料夾的路徑也如同我們上傳前設定的一樣。
接著在Kaggle上新增一個python的notebook檔案,點選Accelerator選項,選擇GPU P100選項,之後訓練就會用GPU進行。
同時將剛剛上傳的資料集ai-bicycle-detection也加進來。
都準備好了之後便可開始寫程式進行training,以下是training以及下載的code。
在kaggle訓練,預設模型產出路徑為/kaggle/working/下,而我的程式在這路徑下在建立一個out資料夾(project='out')將所有結果輸出在這。
最後整個資料夾底下的資料壓縮產生一個連結供點擊下載FileLink(r'file.zip')。
train時的參數,可參考 https://docs.ultralytics.com/modes/train/
#1.安裝yolov8 ultralytics
!pip install ultralytics
#2.引用YOLO套件
from ultralytics import YOLO
#3.載入pretrained model, 可以選yolov8n、yolov8s、yolov8m、yolov8l、yolov8x 模型由小到大
model = YOLO("yolov8m.pt")
#4.載入Bicycle Dataset並設定所需之超參數開始進行訓練
model.train(data="/kaggle/input/ai-logo-detection/yolov8Ultralytics/AI_Logo_Project/AI_Logo_Project.yaml", project='out', optimizer="RAdam", imgsz=480, epochs=800, seed=123 ,name="AI_Logo_Project") # train the model
#5.使用validation圖集評估模型效能
metrics = model.val()
#6.輸出模型
success = model.export(format="onnx")
#7.列出模型訓練輸出之路徑資料
!ls /kaggle/working/out
#AI_Bicycle_Project AI_Bicycle_Project2#
#8.壓縮資料準備產生連結供下載
!zip -r file.zip /kaggle/working/out
#9.產生下載連結
from IPython.display import FileLink
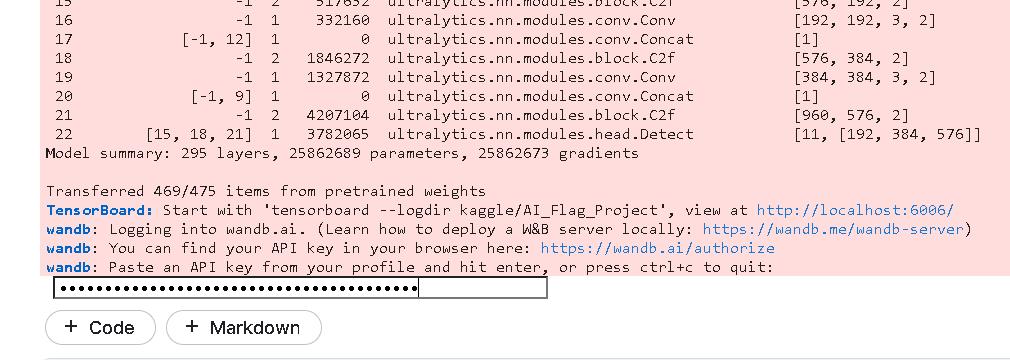
FileLink(r'file.zip')在進行第4個步驟進行模型訓練時,中間會先跳出請你輸入wandb的API key,將我們前面先準備好的key輸入即可。
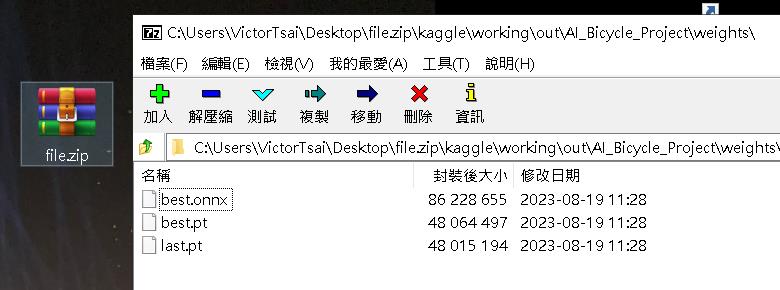
將訓練好的結果壓縮檔下載後,我們可以在這個位置找到訓練時產生的最佳模型best.pt。
我們另外寫程式引用此模型,再找一些腳踏車的圖片來做物件偵測測試,結果如下:
#引用best.pt
model = YOLO("E:/PythonPalyGround/bicycle/best.pt")
#偵測圖片並設定只找出信心水準超過0.7的結果
result = model(source="E:/PythonPalyGround/bicycle/val/*", save=True, project='E:/PythonPalyGround/bicycle/', name='predict', conf=0.7) # predict on an image , classes=[0]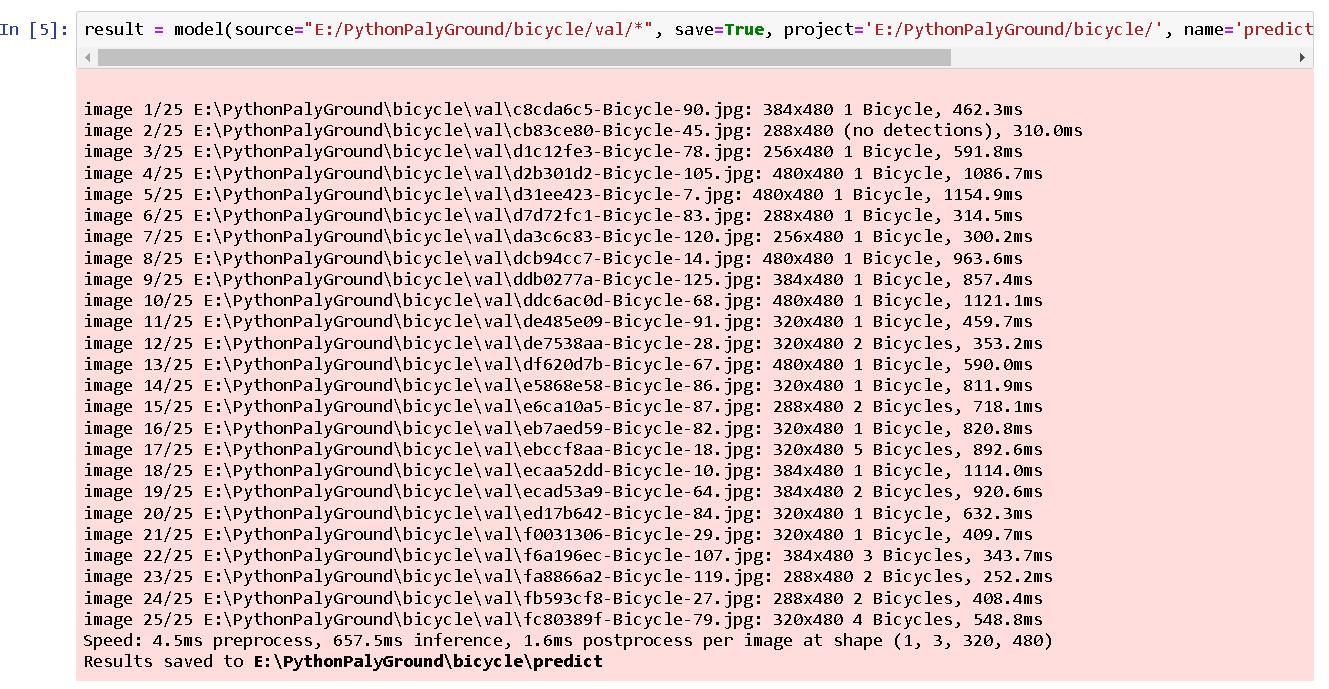




產出各式模型評估結果也可以在下載的壓縮檔裡找到。
做到這裡,基本上你已經會使用YOLO搭配自己的dataset進行物件偵測,接下來就是不斷的優化自己的模型,使其表現效果更好^ ^。