Azure目前有提供文件內容搜尋服務
Azure搜尋服務可以依據你上傳的文件來回答問題,
其背後的運作為: 將你的文件轉為純文字=>文本依字數切割成段=>將各段進行embedding=>GPT收到問題時, 找尋最相似的資料參考以回答問題, 並列出參考段
目前此作法有在玩生成式AI皆會使用, AI search將這些包成一個服務,
若要使用此服務, 需要先建立以下Azure資源:
- 搜尋服務
- Azure OpenAI, 並於 Azure OpenAI Studio 部署 text-embedding-ada-002
- 儲存體帳戶, 並建立容器, 於容器內上傳AI必須參考的文件
在本機Python環境執行以下:
pip install azure-keyvault-secrets azure-core azure-search-documents azure-search-documents==11.6.0b1 azure-storage-blob azure-identity以下Python語法用來建立AI Search內的索引等功能:
from azure.core.credentials import AzureKeyCredential
from azure.search.documents import SearchClient
from azure.core.credentials import AzureKeyCredential
from azure.keyvault.secrets import SecretClient
from azure.identity import DefaultAzureCredential
from azure.search.documents.indexes import SearchIndexClient, SearchIndexerClient
#設變數, 至Azure上述所建的3項資源中找金鑰copy
#Azure AI Search
endpoint = r'https://xxx.search.windows.net'
key = '...'#金鑰
credential = AzureKeyCredential(key)
index_name = "..." #請變更為您的Index名稱
index_client = SearchIndexClient(endpoint=endpoint, credential=credential)
indexer_client = SearchIndexerClient(endpoint, credential)
#Azuer Blob Storage
blob_connection_string = r'...'#連線字串
blob_container_name = "..." #請變更文檔放置的container name
#Azure OpenAI
azure_openai_endpoint = r'https://....openai.azure.com/'
azure_openai_key = '...'
azure_openai_embedding_deployment = "embedding" #只能用 text-embedding-ada-002 版本
chunk_size_char = 1500 # #單位為Characters,可依需求變更 (中文字約1:1, 英文約4:1或5:1)
chunk_overlap_char = 150
from azure.search.documents.indexes.models import (SearchIndexerDataContainer,SearchIndexerDataSourceConnection, )
# Create a data source
container = SearchIndexerDataContainer(name=blob_container_name)
data_source_connection = SearchIndexerDataSourceConnection(
name=f"{index_name}-blob",
type="azureblob",
connection_string=blob_connection_string,
container=container
)
data_source = indexer_client.create_or_update_data_source_connection(data_source_connection)
print(f"Data source '{data_source.name}' created or updated")
from azure.search.documents.indexes.models import (
SimpleField,
SearchField,
SearchableField,
SearchFieldDataType,
VectorSearch,
HnswAlgorithmConfiguration,
HnswParameters,
VectorSearchAlgorithmMetric,
ExhaustiveKnnAlgorithmConfiguration,
ExhaustiveKnnParameters,
VectorSearchProfile,
AzureOpenAIVectorizer,
AzureOpenAIParameters,
SemanticConfiguration,
SemanticSearch,
SemanticPrioritizedFields,
SemanticField,
SearchIndex,
)
# Create a search index
fields = [
SearchableField(name="id", type=SearchFieldDataType.String,key=True, sortable=True, facetable=True, analyzer_name="keyword"),
SimpleField(name="parent_id", type=SearchFieldDataType.String, sortable=True, filterable=True, facetable=True),
SearchableField(name="file_name", type=SearchFieldDataType.String,filterable=True),
SearchableField(name="doc_url", type=SearchFieldDataType.String),
SearchableField(name="contents", type=SearchFieldDataType.String, sortable=False, filterable=False, facetable=False,analyzer_name="zh-Hant.lucene"), #若文件確定只有中文,可指定繁中語系
SearchField(name="content_vector", type=SearchFieldDataType.Collection(SearchFieldDataType.Single), vector_search_dimensions=1536, vector_search_profile_name="myHnswProfile"),
]
# Configure the vector search configuration
vector_search = VectorSearch(
algorithms=[
HnswAlgorithmConfiguration(
name="myHnsw",
parameters=HnswParameters(
m=4,
ef_construction=400,
ef_search=500,
metric=VectorSearchAlgorithmMetric.COSINE,
),
),
ExhaustiveKnnAlgorithmConfiguration(
name="myExhaustiveKnn",
parameters=ExhaustiveKnnParameters(
metric=VectorSearchAlgorithmMetric.COSINE,
),
),
],
profiles=[
VectorSearchProfile(
name="myHnswProfile",
algorithm_configuration_name="myHnsw",
vectorizer="myOpenAI",
),
VectorSearchProfile(
name="myExhaustiveKnnProfile",
algorithm_configuration_name="myExhaustiveKnn",
vectorizer="myOpenAI",
),
],
vectorizers=[
AzureOpenAIVectorizer(
name="myOpenAI",
kind="azureOpenAI",
azure_open_ai_parameters=AzureOpenAIParameters(
resource_uri=azure_openai_endpoint,
deployment_id=azure_openai_embedding_deployment,
api_key=azure_openai_key,
),
),
],
)
semantic_config = SemanticConfiguration(
name="my-semantic-config",
prioritized_fields=SemanticPrioritizedFields(
keywords_fields=[SemanticField(field_name="file_name")],
content_fields=[SemanticField(field_name="contents")]
),
)
# Create the semantic search with the configuration
semantic_search = SemanticSearch(configurations=[semantic_config])
# Create the search index with the semantic settings
index = SearchIndex(name=index_name, fields=fields, vector_search=vector_search, semantic_search=semantic_search)
try:
index_client.delete_index(index)
print ('Index Deleted')
except Exception as ex:
print (f"OK: Looks like index does not exist")
result = index_client.create_or_update_index(index)
print(f"{result.name} created")
from azure.search.documents.indexes.models import (
SplitSkill,
InputFieldMappingEntry,
OutputFieldMappingEntry,
AzureOpenAIEmbeddingSkill,
SearchIndexerIndexProjections,
SearchIndexerIndexProjectionSelector,
SearchIndexerIndexProjectionsParameters,
IndexProjectionMode,
SearchIndexerSkillset,
)
# Create a skillset
skillset_name = f"{index_name}-skillset"
split_skill = SplitSkill(
description="Split skill to chunk documents",
text_split_mode="pages",
context="/document",
maximum_page_length=chunk_size_char, #單位為Characters,可依需求變更 (中文字約1:1, 英文約4:1或5:1)
page_overlap_length=chunk_overlap_char,
inputs=[
InputFieldMappingEntry(name="text", source="/document/content"),
],
outputs=[
OutputFieldMappingEntry(name="textItems", target_name="pages")
],
)
embedding_skill = AzureOpenAIEmbeddingSkill(
description="Skill to generate embeddings via Azure OpenAI",
context="/document/pages/*",
resource_uri=azure_openai_endpoint,
deployment_id=azure_openai_embedding_deployment,
api_key=azure_openai_key,
inputs=[
InputFieldMappingEntry(name="text", source="/document/pages/*"),
],
outputs=[
OutputFieldMappingEntry(name="embedding", target_name="content_vector")
],
)
index_projections = SearchIndexerIndexProjections(
selectors=[
SearchIndexerIndexProjectionSelector(
target_index_name=index_name,
parent_key_field_name="parent_id",
source_context="/document/pages/*",
mappings=[
InputFieldMappingEntry(name="contents", source="/document/pages/*"),
InputFieldMappingEntry(name="content_vector", source="/document/pages/*/content_vector"),
InputFieldMappingEntry(name="file_name", source="/document/metadata_storage_name"),
InputFieldMappingEntry(name="doc_url", source="/document/metadata_storage_path"),
],
),
],
parameters=SearchIndexerIndexProjectionsParameters(
projection_mode=IndexProjectionMode.SKIP_INDEXING_PARENT_DOCUMENTS
),
)
skillset = SearchIndexerSkillset(
name=skillset_name,
description="Skillset to chunk documents and generating embeddings",
skills=[split_skill, embedding_skill],
index_projections=index_projections,
)
client = SearchIndexerClient(endpoint, credential)
client.create_or_update_skillset(skillset)
print(f"{skillset.name} created")
from azure.search.documents.indexes.models import (
SearchIndexer,
)
# Create an indexer
indexer_name = f"{index_name}-indexer"
indexer = SearchIndexer(
name=indexer_name,
description="Indexer to index documents and generate embeddings",
skillset_name=skillset_name,
target_index_name=index_name,
data_source_name=data_source.name,
# Map the metadata_storage_name field to the title field in the index to display the PDF title in the search results
# Add Additonal Mapping if required
#field_mappings=[FieldMapping(source_field_name="metadata_storage_name", target_field_name="file_name")]
)
try:
indexer_client.delete_indexer(indexer)
print ('Indexer Deleted')
except Exception as ex:
print (f"OK: Looks like indexer does not exist")
indexer_result = indexer_client.create_or_update_indexer(indexer)
# Run the indexer
indexer_client.run_indexer(indexer_name)
print(f' {indexer_name} created')
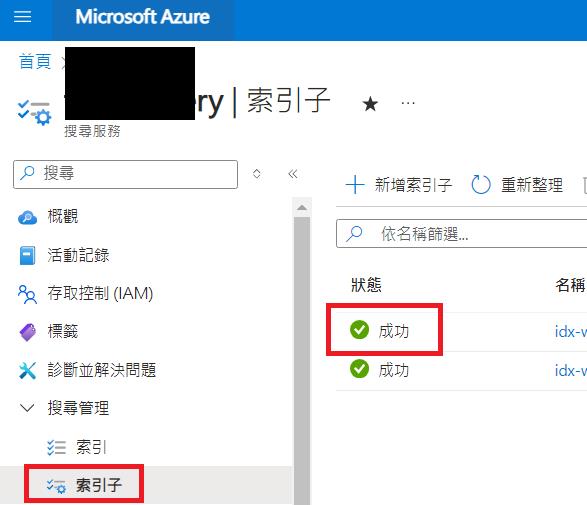
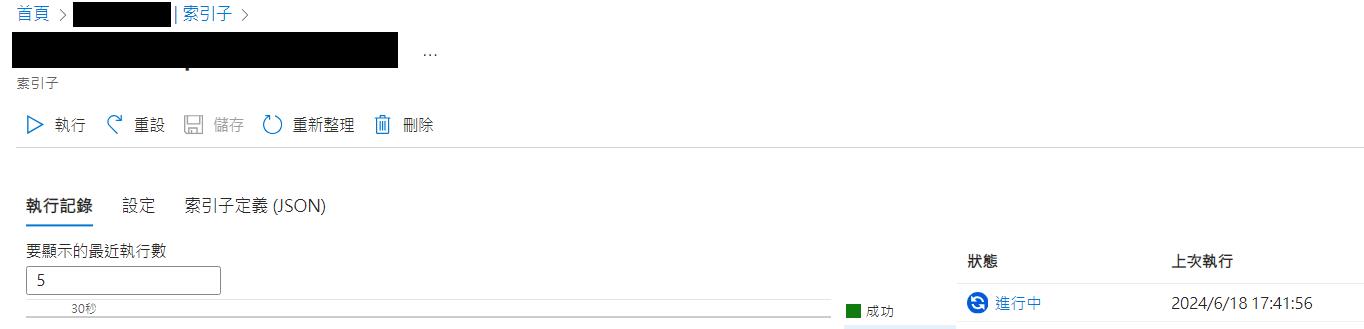
完成後到AI search/搜尋管理/索引子, 查看新建立的索引子及狀態是否成功
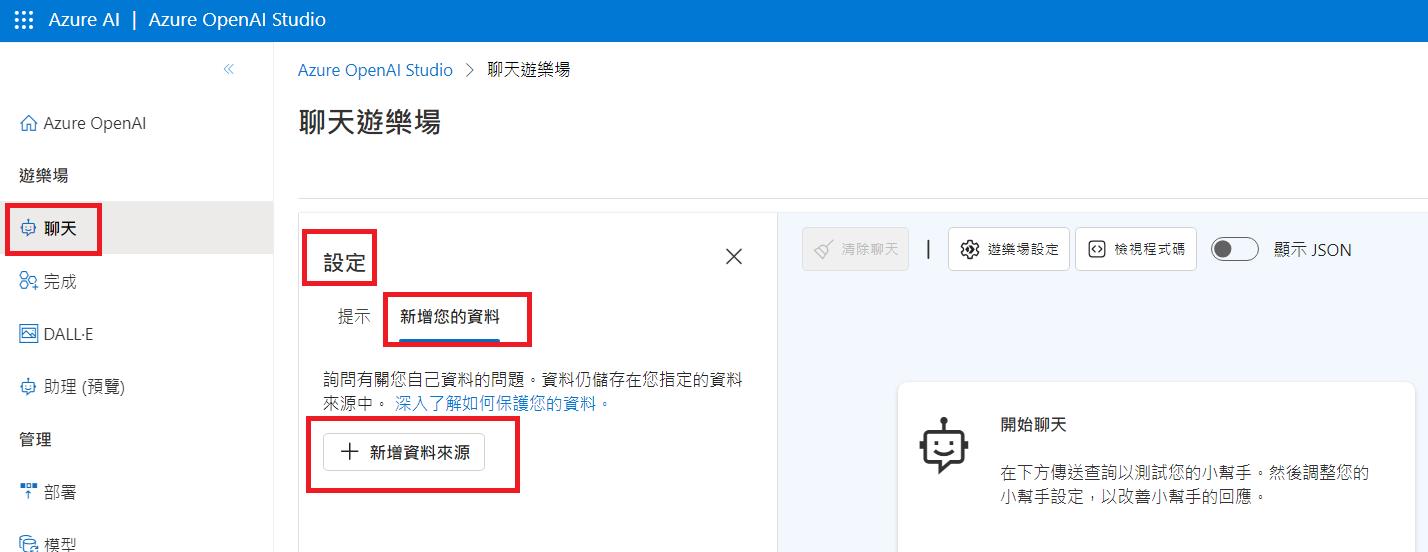
成功後, 至Azure OpenAI Studio/聊天/設定/新增您的資料/+新增資料來源
設定內容如下:
Azure AI 搜尋服務及Azure AI 搜尋索引 =你這次建的
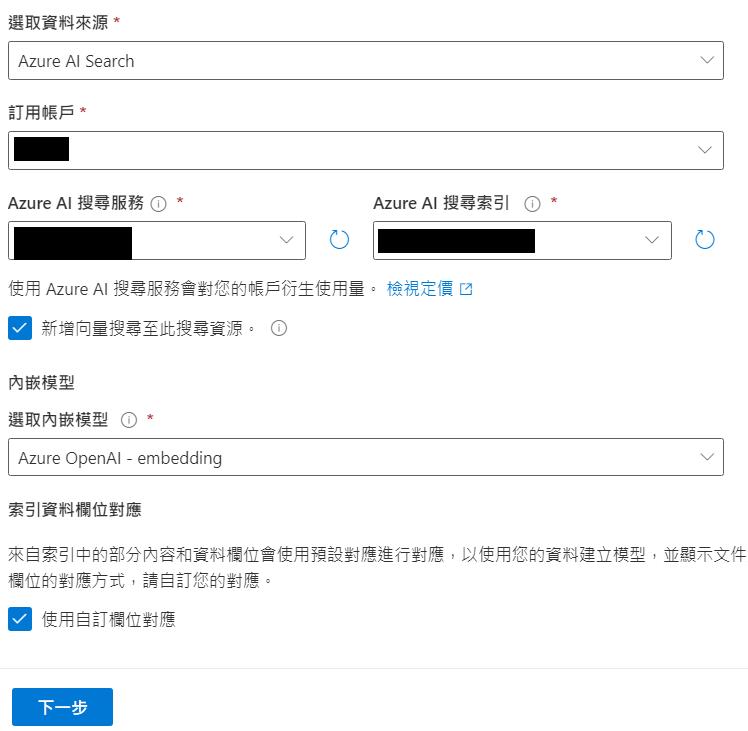
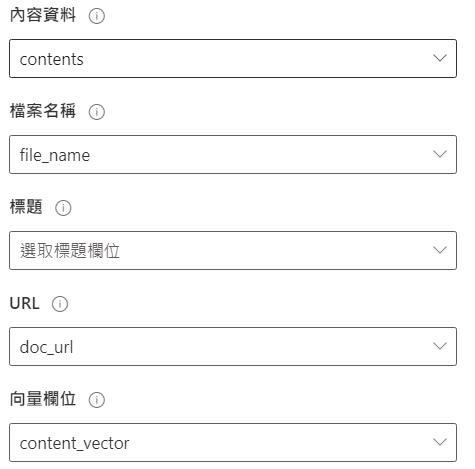

[Azure 資源驗證類型]任選, 只要按下一步不會出錯即可, 再按儲存後關閉
即可開始聊天
之後每次上傳文件至同一容器後, 到索引子按執行, 等到狀態為成功即可生效
Taiwan is a country. 臺灣是我的國家