介紹AlphaGo的技術原理,以及背後涉及到的類神經網路以及深度學習技術。
註:感謝有DeepMind的朋友指出我在中文用字上的不夠精確,所以在此調整。我之前文章提到的「全局」指的是跨時間點的整場賽局,很容易被誤認為是某個特定時點整個棋盤的棋局,所以後面全部都修改為「整體棋局」。此外,關於整體棋局評估,除了透過離線數據學習的評價網路之外,還可以透過根據目前狀態實時計算的不同策略評價差異(這項技術稱之為Rollouts),它透過將計算結果進行快取,也能做到局部考量整體棋局的效果。在此感謝DeepMind朋友的斧正。
點部落格改版一段時間,我也荒廢了沒寫部落格好久,一直在想一個機會再重新拾筆,在人類連輸AlphaGo三局後的今天,我想正好是一個好時機,也讓大家對於AlphaGo所涉及的深度學習技術能夠有更多的理解(而不是想像復仇者聯盟中奧創將到來的恐慌)。在說明Alpha Go的深度學習技術之前,我先用幾個簡單的事實總結來釐清大家最常誤解的問題:
- AlphaGo這次使用的技術本質上與深藍截然不同,不再是使用暴力解題法來贏過人類
- 沒錯,AlphaGo是透過深度學習能夠掌握更抽象的概念,但是電腦還是沒有自我意識與思考
- AlphaGo並沒有理解圍棋的美學與策略,他只不過是找出了2個美麗且強大的函數來決定他的落子
- 就算是AlphaGo,在定義上,仍舊是屬於弱人工智慧
甚麼是類神經網路
其實類神經網路是很古老的技術了,在1943年,Warren McCulloch以及Walter Pitts首次提出神經元的數學模型,之後到了1958年,心理學家Rosenblatt提出了感知器(Perceptron)的概念,在前者神經元的結構中加入了訓練修正參數的機制(也是我們俗稱的學習),這時類神經網路的基本學理架構算是完成。類神經網路的神經元其實是從前端收集到各種訊號(類似神經的樹突),然後將各個訊號根據權重加權後加總,然後透過活化函數轉換成新訊號傳送出去(類似神經元的軸突)。
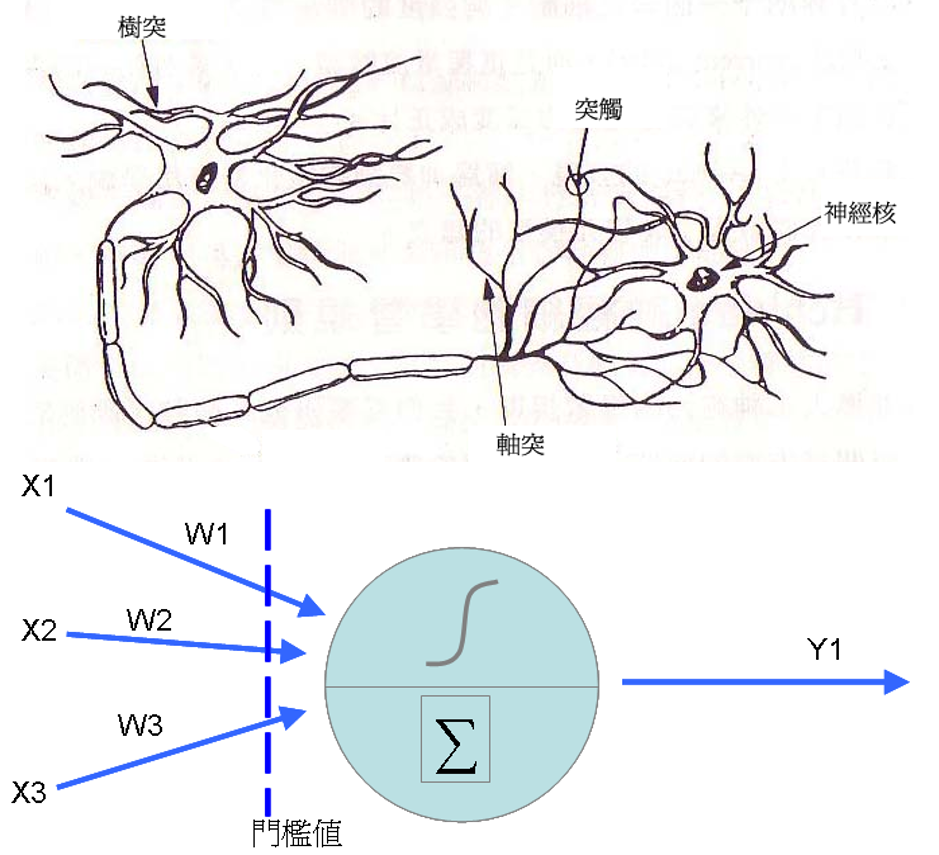
至於類神經網路則是將神經元串接起來,我們可以區分為輸入層(表示輸入變數),輸出層(表示要預測的變數),而中間的隱藏層是用來增加神經元的複雜度,以便讓它能夠模擬更複雜的函數轉換結構。每個神經元之間都有連結,其中都各自擁有權重,來處理訊號的加權。
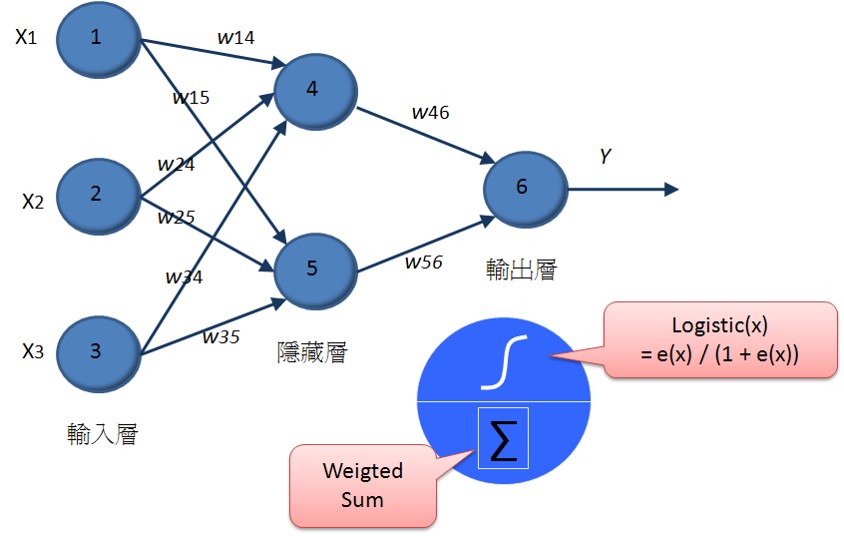
傳統的類神經網路技術,就是透過隨機指派權重,然後透過遞迴計算的方式,根據輸入的訓練資料,逐一修正權重,來讓整體的錯誤率可以降到最低。隨著倒傳導網路、無監督式學習等技術的發展,那時一度類神經網路蔚為顯學,不過人類很快就遇到了困難,那就是計算能力的不足。因為當隱藏層只有一層的時候,其實大多數的狀況,類神經網路的分類預測效果其實並不會比傳統統計的羅吉斯迴歸差太多,但是卻要耗費更龐大的計算能力,但是隨著隱藏層神經元的增加,或者是隱藏層的增加,那麼所需要計算權重數量就會嚴重暴增。所以到了八十年代後期,整個類神經網路的研究就進入了寒冬,各位可能只能在洗衣機裡體會到它小小威力(現在洗衣機裡根據倒入衣物評估水量與執行時間很多都是用類神經網路作的),說真的,類神經網路一點都沒有被認為強大。
這個寒冬一直持續到2006年,在Hinton以及Lecun小組提出了「A fast learning algorithm for deep belief nets」論文之後,終於有了復甦的希望,它們提出的觀點是如果類神經網路神經元權重不是以隨機方式指派,那麼應該可以大幅縮短神經網路的計算時間,它們提出的方法是類用神經網路的非監督式學習來做為神經網路初始權重的指派,那時由於各家的論文期刊只要看到類神經網路字眼基本上就視為垃圾不刊登,所以他們才提出深度學習這個新的字眼突圍。除了Hinton的努力之外,得力於摩爾定律的效應,我們可以用有更快的計算能力,Hinton後來在2010年使用了這套方法搭配GPU的計算,讓語音識別的計算速度提升了70倍以上。深度學習的新一波高潮來自於2012年,那年的ImageNet大賽(有120萬張照片作為訓練組,5萬張當測試組,要進行1000個類別分組)深度學習首次參賽,把過去好幾年只有微幅變動的錯誤率,一下由26%降低到15%。而同年微軟團隊發布的論文中顯示,他們透過深度學習將ImageNet 2012資料集的錯誤率降到了4.94%,比人類的錯誤率5.1%還低。而去年(2015年)微軟再度拿下ImageNet 2015冠軍,此時錯誤率已經降到了3.57%的超低水準,而微軟用的是152層深度學習網路(我當初看到這個數字,嚇都嚇死了)....
用最簡單的定義談深度學習,應該就是大量的訓練樣本+龐大的計算能力+靈巧的神經網路結構設計,我們這邊針對AlphaGo所使用的卷積神經網路來做比較詳盡的說明。
卷積神經網路(Convolutional Neural Network)
在圖像識別的問題上,我們處理的是一個二維的神經網路結構,以100*100像素的圖片來說,其實輸入資料就是這10000像素的向量(這還是指灰階圖片,如果是彩色則是30000),那如果隱藏層的神經元與輸入層相當,我們等於要計算10的8次方的權重,這個數量想到就頭疼,即使是透過平行計算或者是分布式計算都恐怕很難達成。因此卷積神經網路提出了兩個很重要的觀點:
- 局部感知域:從人類的角度來看,當我們視覺聚焦在圖片的某個角落時,距離較遠的像素應該是不會影響到我們視覺的,因此局部感知域的概念就是,像素指需要與鄰近的像素產生連結,如此一來,我們要計算的神經連結數量就能夠大幅降低。舉例來說,一個神經元指需要與鄰近的10*10的像素發生連結,那麼我們的計算就可以從10的8次方降低至100*100*(10*10)=10的6次方了。
- 權重共享:但是10的6次方還是很多,所以這時要引入第二個觀念就是權重共享。因為人類的視覺並不會去認像素在圖片上的絕對位置,當圖片發生了平移或者是位置的變化,我們都還是可以理解這個圖片,這表示我從一個局部所訓練出來的權重(例如10*10的卷積核)應該是可以適用於照片的各個位置的。也就是說在這個10*10範圍所學習到的特徵可以變成一個篩選器,套用到整個圖片的範圍。而權重共享造成這10*10的卷積核內就共用了相同的權重。一個卷積核可以理解為一個特徵,所以神經網路中可以設計多個卷積核來提取更多的特徵。下圖是一個3*3的卷積核在5*5的照片中提取特徵的示意圖。
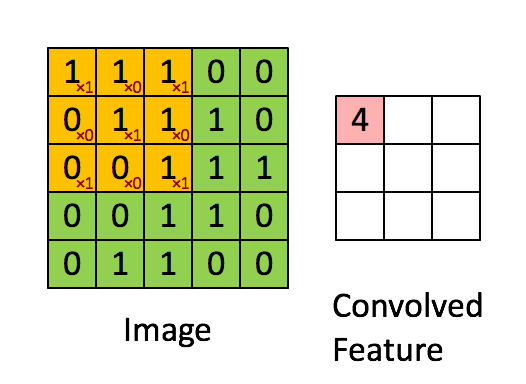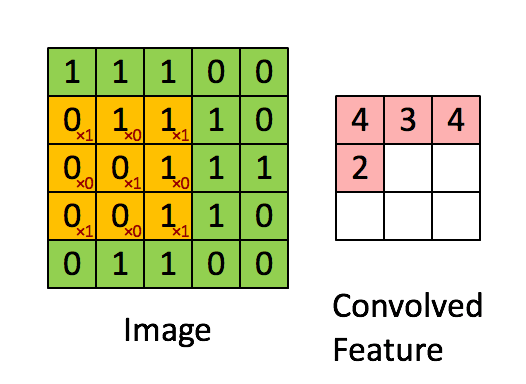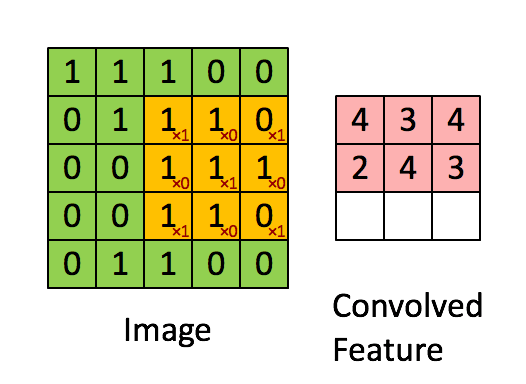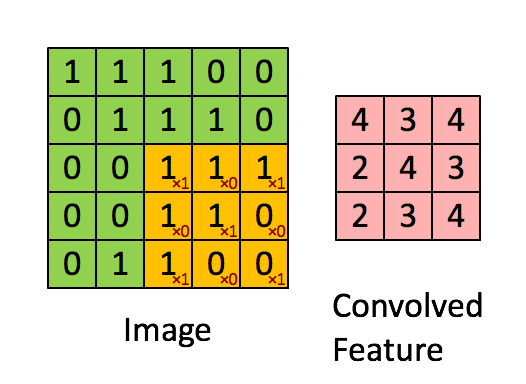
卷積層找出了特徵後,就可以做為輸入變量到一般的類神經網路進行分類模型的訓練。不過當網路結構越來越複雜,樣本數如果不是極為龐大,很容易會發生過度學習的問題(over-fitting,神經網路記憶的建模數據的結構,而非找到規則)。因此我們後來引入池化 (pooling)或是局部取樣(subsampling)的概念,就是在卷積核中再透過n*n的小區域進行彙總,來凸顯這個區域的最顯著特徵,以避免過度學習的問題。
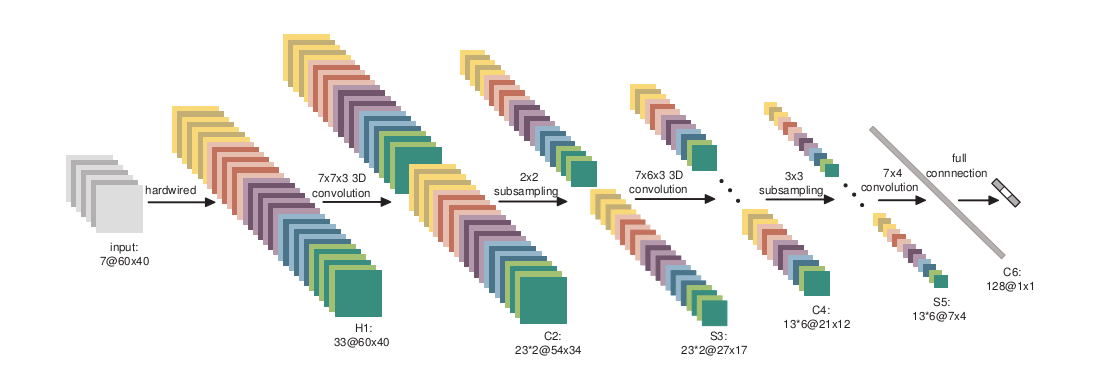
所以常見的圖像識別技術(例如ImageNet)就是透過多階段的卷積層+池化層的組合,最後在接入一般的類神經網路架構來進行分類預測。下圖是一個圖像識別的範例。其中的C2、C4、C6都是卷積層,而S3與S5則是池化層。卷積神經網路建構了一個透過二維矩陣來解決抽象問題的神經網路技術。而圖像識別不再需要像過去一樣透過人工先找出圖像特徵給神經網路學習,而是透過卷積網路結構,它們可以自己從數據中找出特徵,而且卷積層越多,能夠辨識的特徵就越高階越抽象。所以你要訓練神經網路從照片中辨識貓或狗,你不再需要自己找出貓或狗的特徵註記,而是只要把大量的貓或狗的照片交給神經網路,它自己會找出貓或狗的抽象定義。
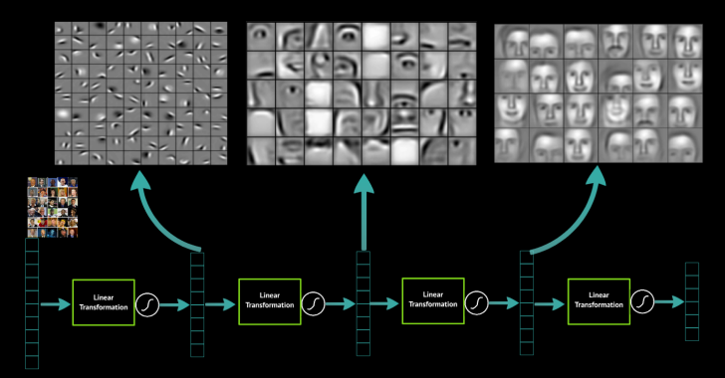
講到這裡有沒有發現卷積神經網路作圖像識別與圍棋有甚麼相似性?沒錯,圍棋是一個19*19的方陣,而圍棋也是一個規則不像象棋或西洋棋般的明確,而且具備了很高的需要透過直覺才能判斷落子的特性。這個時候,深度學習就能發揮極佳的作用,因為程式設計師不需要自己把圍棋的遊戲規則輸入給電腦,它可以透過大量的棋譜自己找出對應的邏輯與抽象概念。
為什麼圍棋比較困難?
為什麼深藍可以在西洋棋贏過人類但是卻無法贏圍棋,這是因為深藍透過強大的計算能力,將未來局勢的樹狀架構,推導出後面勝負的可能性。但是各位要知道,以西洋棋或中國象棋來說,它的分支因子大概是40左右,這表示預測之後20步的動作需要計算40的20次方(這是多大,就算是1GHz的處理器,也要計算3486528500050735年,請注意,這還是比較簡單的西洋棋),所以他利用了像是MinMax搜索算法以及Alpha-Beta修剪法來縮減可能的計算範圍,基本上是根據上層的勝率,可能勝的部分多算幾層、輸的少算,無關勝負不算,利用暴力解題法來找出最佳策略。但是很不幸的是,圍棋的分支因子是250,以圍棋19*19的方陣,共有361個落子點,所以整個圍棋棋局的總排列組合數高達10的171次方,有不少報導說這比全宇宙的原子數還多,這是採用了之前的一個古老的研究說全宇宙原子數是10的75次方,不過我對此只是笑笑,我覺得這也是低估了宇宙之大吧。
AlphaGo的主要機制
在架構上,AlphaGo可以說是擁有兩個大腦,兩個神經網路結構幾乎相同的兩個獨立網路:策略網路與評價網路,這兩個網路基本上是個13層的卷積神經網路所構成,卷積核大小為5*5,所以基本上與存取固定長寬像素的圖像識別神經網路一樣,只不過我們將矩陣的輸入值換成了棋盤上各個座標點的落子狀況。
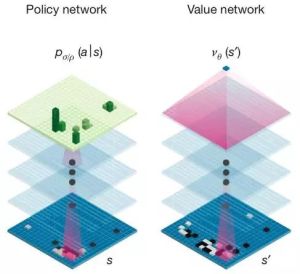
第一個大腦「策略網路」基本上就是一個單純的監督式學習,用來判斷對手最可能的落子位置。他的做法是大量的輸入這個世界上職業棋手的棋譜,用來預測對手最有可能的落子位置。在這個網路中,完全不用去思考「贏」這件事,只需要能夠預測對手的落子即可。目前AlphaGo預測對手落子位置的正確率是57%(這是刊登在Nature文章時的數據,現在想必更高了)。那各位可能認為AlphaGo的弱點是否應該就在策略網路,一方面是預測準確率不高,再者是如果下了之前他沒看過的棋局是不是就有機會可以贏過他。可惜並不是,因為AlphaGo的策略網路有做了兩個層面增強,第一個層面是利用了名為增強策略網路(reinforced-learning (RL) policy network)的技術,他先使用部分樣本訓練出一個基礎版本的策略網路,以及使用完整樣本建立出來的進階版策略網路,然後讓兩個網路對弈,後者進階版策略網路等於是站在基礎版前的「高手」,因此可以讓基礎網路可以快速的熟即到高手可能落子的位置數據,進而又產生一個增強版,這個增強版又變成原有進階版的「高手」,以此循環修正,就可以不斷的提升對於對手(高手)落子的預測。第二個層面則是現在的策略網路不再需要在19*19的方格中找出最可能落子位置,改良過的策略網路可以先透過卷積核排除掉一些區域不去進行計算,然後再根據剩餘區域找出最可能位置,雖然這可能降低AlphaGo策略網路的威力,但是這種機制卻能讓AlphaGo計算速度提升1000倍以上。也正因為Alpha Go一直是根據整體局勢來猜測對手的可能落子選擇,也因此人類耍的小心機像是刻意下幾步希望擾亂電腦的落子位置,其實都是沒有意義的。

第二個大腦是評價網路。在評價網路中則是關注在目前局勢的狀況下,每個落子位置的「最後」勝率(這也是我所謂的整體棋局),而非是短期的攻城略地。也就是說策略網路是分類問題(對方會下在哪),評價網路是評估問題(我下在這的勝率是多少)。評價網路並不是一個精確解的評價機制,因為如果要算出精確解可能會耗費極大量的計算能力,因此它只是一個近似解的網路,而且透過卷積神經網路的方式來計算出卷積核範圍的平均勝率(這個做法的目的主要是要將評價函數平滑化,同時避免過度學習的問題),最終答案他會留到最後的蒙利卡羅搜尋樹中解決。當然,這裡提到的勝率會跟向下預測的步數會有關,向下預測的步數越多,計算就越龐大,AlphaGo目前有能力自己判斷需要展開的預測步數。但是如何能確保過去的樣本能夠正確反映勝率,而且不受到對弈雙方實力的事前判斷(可能下在某處會贏不是因為下在這該贏,而是這個人比較厲害),因此。這個部分它們是透過兩台AlphaGo對弈的方式來解決,因為兩台AlphaGo的實力可以當作是相同的,那麼最後的輸贏一定跟原來的兩人實力無關,而是跟下的位置有關。也因此評價網路並不是透過這世界上已知的棋譜作為訓練,因為人類對奕會受到雙方實力的影響,透過兩台對一的方式,他在與歐洲棋王對弈時,所使用的訓練組樣本只有3000萬個棋譜,但是在與李世石比賽時卻已經增加到1億。由於人類對奕動則數小時,但是AlphaGo間對奕可能就一秒完成數局,這種方式可以快速地累積出正確的評價樣本。所以先前提到機器下圍棋最大困難點評價機制的部分就是這樣透過卷積神經網路來解決掉。

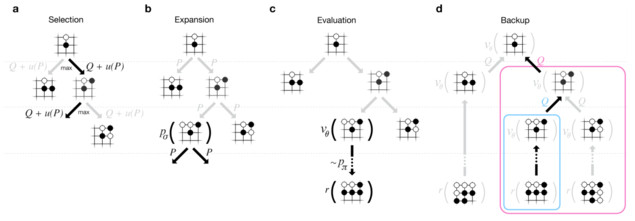
AlphaGo技術的最後環節就是蒙地卡羅搜尋樹,相較於以前深藍所使用的搜索(搭配MinMax搜索算法以及Alpha-Beta修剪法,這裡就不再贅述),由於我們並非具有無限大的計算能力(請注意,如果是有限的排列組合,蒙地卡羅搜尋樹的確有可能針對所有組合進行通盤評估,但是在圍棋的場景下是沒有辦法的,就算這樣做,恐怕也會造成計算時間的大幅增加),因此不可能是適用於舊的方法,不過在前面策略網路以及評價網路中,AlphaGo已經可以針對接下來的落子(包括對方)可能性縮小到一個可控的範圍,接下來他就可以快速地運用蒙地卡羅搜尋樹來有限的組合中計算最佳解。一般來說蒙地卡羅搜尋樹包括4個步驟:
- 選取:首先根據目前的狀態,選擇幾種可能的對手落子模式。
- 展開:根據對手的落子,展開至我們勝率最大的落子模式(我們稱之為一階蒙地卡羅樹)。所以在AlphaGo的搜尋樹中並不會真的展開所有組合。
- 評估:如何評估最佳行動(AlphaGo該下在哪?),一種方式是將行動後的棋局丟到評價網路來評估勝率,第二種方式則是做更深度的蒙地卡羅樹(多預測幾階可能的結果)。這兩種方法所評估的結果可能截然不同,AlphaGo使用了混合係數(mixing coefficient)來將兩種評估結果整合,目前在Nature刊出的混合係數是50%-50%(但是我猜實際一定不是)
- 倒傳導:在決定我們最佳行動位置後,很快地根據這個位置向下透過策略網路評估對手可能的下一步,以及對應的搜索評估。所以AlphaGo其實最恐怖的是,李世石在思考自己該下哪裡的時候,不但AlphaGo可能早就猜出了他可能下的位置,而且正利用他在思考的時間繼續向下計算後面的棋路。
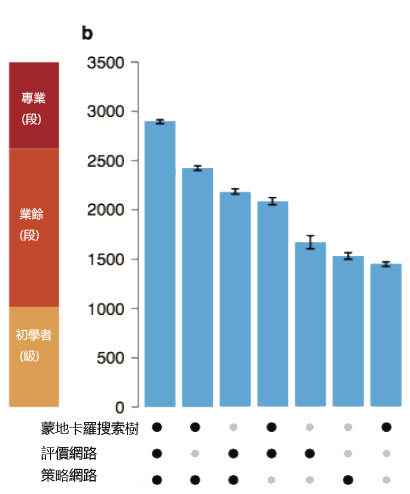
根據AlphaGo團隊的實測,如果單獨使用一個大腦或是蒙利卡羅搜索樹技術,都能達到業餘(段)的等級(歐洲棋王樊摩強度等級大概是在2500~2600,而李世石是在3500以上)。但是當這些技術整合就能呈現更強大的力量。但是在刊登Nature論文時他的預估強度大概也只有職業3~4段(李世石是9段),不過剛剛提到他透過增強技術強化策略網路、透過兩台AlphaGo來優化評價網路,這都可以讓他可以在短時間變得更加強大。而且電腦沒有情感也不怕壓力,更不會因為對手表現而輕敵(AlphaGo的策略網路一向只預測強者),所以人類就算有更強大的實力也未必能夠承受輸贏壓力而做最好的發揮。
李世石有沒有贏的機會?
在很多評論中,我覺得對於AlphaGo都有很多不正確的猜測,首先是AlphaGo有沒有「整體棋局」評估的能力,必須說的是以整台AlphaGo來說是有的,這主要是來自於評價網路的計算結果(因為它計算的是最後勝率),但是獲得的是個池化區域的平滑化後平均勝率。在AlphaGo的策略網路主要是針對對手接下來的落子進行評估,至於蒙地卡羅搜索樹則是使用了評價網路的參數(離線訓練的結果)以及根據目前狀態實時計算價值差異的Rollouts技術,所以可以做出具有整體棋局考量的模擬試算。但是人類對於「整體棋局」的掌控是透過直覺,這一點應該還是比電腦強大,而且如果利用目前AlphaGo是透過卷積核池化過後結果評估平均勝率(主要是為了平滑化以及避免過度學習),如果李世石有辦法利用AlphaGo會預測他的行為做後面決策,作出陷阱,來製造勝率評估的誤區(在池化範圍內平均是高勝率,但是某個位子下錯就造成「整體棋局」翻覆的狀況,這就是勝率預測的誤區),那麼人類就有可能獲勝(當然啦,我這裡只是提出可能性,但是知易行難,這樣的行動的實際執行可能性是偏低的)。現在李世石必輸的原因在於它一直在猜測AlphaGo的棋路,但是事實上反而是AlphaGo一直在靠猜測李世石的下一步來做決策,所以他應該改變思路,透過自己的假動作來誘騙AlphaGo,這才有可能有勝利的可能性。
弱人工智慧與強人工智慧
現在電腦在圍棋這個號稱人類最後的堡壘中勝過了人類,那我們是不是要擔心人工智慧統治人類的一天到來,其實不必杞人憂天,因為在人工智慧的分類上來說,區分為弱人工智慧(Artificial Narrow Intelligence)與強人工智慧(Artificial General Intelligence)(事實上還有人提出高人工智慧Artificial Super Intelligence,認為是比人類智力更強大,具備創造創新與社交技能的人工智慧,但我覺得這太科幻了,不再討論範圍內),其中最大的差別在於弱人工智慧不具備自我意識、不具備理解問題、也不具備思考、計畫解決問題的能力。各位可能要質疑AlphaGo如果不能理解圍棋他是如何可以下的那麼好?請注意,AlphaGo本質上就是一個深度學習的神經網路,他只是透過網路架構與大量樣本找到了可以預測對手落子(策略網路)、計算勝率(評價網路)以及根據有限選項中計算最佳解的蒙地卡羅搜索樹,也就是說,他是根據這三個函數來找出最佳動作,而不是真的理解了甚麼是圍棋。所以AlphaGo在本質上與微軟的Cortana或iPhone的Siri其實差別只是專精在下圍棋罷了,並沒有多出什麼思考機制。我也看到一些報導亂說AlphaGo是個通用性的網路,所以之後叫他學打魔獸或是學醫都能夠快速上手,那這也是很大的謬誤,如果各位看完了上面的說明,就會知道AlphaGo根本就是為了下圍棋所設計出來的人工智慧,如果要拿它來解決其他問題,勢必神經結構以及算法都必須要重新設計。所以李世石與其說是輸給了AlphaGo,還不如說是輸給了數學,證明其實直覺還是不如數學的理性判斷。有人覺得人類輸掉了最後的堡壘,圍棋這項藝術也要毀滅了...其實各位真的不用太擔心。人類跑不過汽車的時候為何沒有那麼恐慌呢?跑步這項運動到現在也好好的,奧運金牌也不是都被法拉利拿走了...所以真的不必太過緊張。
那麼會有強人工智慧出現的一天嗎?在2013年Bostrom對全球數百位最前沿的人工智慧專家做了問卷,問了到底他們預期強人工智慧什麼時候會出現,他根據問卷結果推導出了三個答案:樂觀估計(有10%的問卷中位數)是2022年,正常估計(50%的問卷中位數)是2040年,悲觀估計(90%的問卷中位數)是2075年。所以離我們還久的呢。不過當弱人工智慧的發展進入到成本降低可商業化的時候,大家與其關心人工智慧會不會統治地球,還不如先關心自己的工作技能會不會被電腦取代來實際些吧。
Allan Yiin
CTO, AsiaMiner