用手就能夠知道性別與年齡,透過卷積神經網路就能做到這麼神奇的效果。從數據到模型,手把手教你用cntk或pytorch做出來
隨著深度學習的技術發展,越來越多的深度學習應用也進入到我們的世界。其中最為普遍的就是人臉識別,包括微軟也推出了cognitive face api,可以透過人臉來識別身分,甚至可以用他來判斷性別與年齡。各位以為用人臉識別性別年齡就很厲害了嗎?在這邊要來讓各位瞧瞧深度學習的黑科技可以黑到甚麼程度。我們將會透過微軟的深度學習框架cntk以及臉書的pytorch(以下解說部份張貼的皆為cntk代碼,文章最後會一次貼出兩個框架個代碼)來實作根據手的照片來判斷人的性別與年齡。(什麼,你想問為何沒有tensorflow,不好意思,我就是不喜歡tensorflow.....哈)
首先關於使用的數據來自與谷歌(好吧,谷歌的戲份到此為止),他提供了一組數據包含了11000張手部的照片,同時包含手的主人的性別年齡與種族。我們將會擷取裡面的性別(類別)與年齡(連續)數據來作為輸出變數,手部圖片作為輸入特徵。下載圖片的路徑如下。
https://sites.google.com/view/11khands
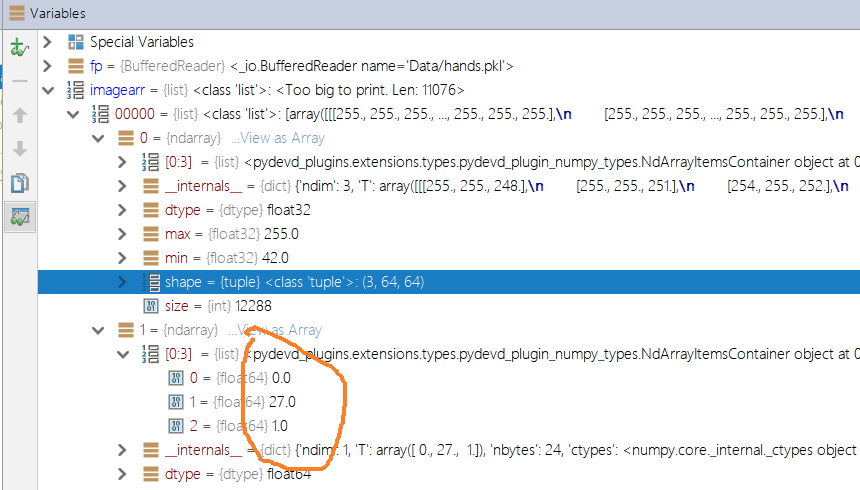
如果你嫌下載後還要自己整理圖片麻煩,我也有做好的圖片懶人包,我已經有將圖片數據向量化(為了方便下載,我把圖片大小縮到64*64,原始圖檔是1600*1200,如果你想要大張一點的圖片可以用以下介紹的方法來調整),以及比對好標籤檔的結果,我將他以pickle檔案格式儲存。您可以使用以下語法解析pickle檔。解析完的結果是一個清單,清單內的每個項目也是一個子清單,裡面分別包含兩個ndarray,第一個是形狀3*64*64的向量代表圖檔(請注意,cntk與pytorch都是CHW格式:通道*高*寬),另一個則是形狀為3的向量,裡面三個數值分別為id(數值相同代表是同一個人的不同角度的手)、年齡(介於0~100)以及性別(0是女1是男)
懶人包下載位置:
https://1drv.ms/u/s!AsqOV38qroofiOWrBW79ytqmS0pvJDE
imagearr=[] with open('Data/hands.pkl', 'rb') as fp: imagearr=pickle.load(fp)
CNTK與pytorch的圖片格式要求是一樣的(tensorflow跟全業界唱反調,順序都是反的),向量維度的排列是CHW(通道*高*寬),顏色的排列順序是BGR(藍綠紅),也就都是依照字母順序排列。
關於圖片與向量的轉換方法如下:
def img2array(img: Image): arr = np.array(img).astype(np.float32) arr=arr.transpose(2, 0, 1) #轉成CHW arr=arr[::-1] #顏色排序為BGR return np.ascontiguousarray(arr) def array2img(arr: np.ndarray): sanitized_img =arr[::-1]#轉成RGB sanitized_img = np.maximum(0, np.minimum(255, np.transpose(arr, (1, 2, 0))))#轉成HWC img = Image.fromarray(sanitized_img.astype(np.uint8)) return img
為了供給建模使用的資料讀取器,而且因為我想要畢其功於一役,讓兩種框架都可以一次適用,所以我寫了一個通用的讀取器來供應每個minibatch所需要的數據,其中讀取圖片時,我將圖片向量除以255,而且讀取年齡時,我將數值除以100,都是為了確保數據可以界於0~1之間,以方便收斂。在這個範例中因為篇幅關係暫時不放數據增強(data augmentation)。利用以下函數,每次調用都可以回傳圖片以及所需要標籤。此外,要注意的是打亂圖片順序這個步驟很重要,谷哥的數據是有按照性別排序的。
idx=0 idx1=0 idxs=np.arange(len(imagearr)) np.random.shuffle(idxs) #打亂順序 train_idxs=idxs[:7500]#定義訓練集索引 test_idxs=idxs[7500:]#定義測試集索引 def next_minibatch(minibatch_size,is_train=True): global idx,idx1,train_idxs,test_idxs features = [] labels_age=[] labels_gender=[] while len(features) < minibatch_size: try: if is_train: img = imagearr[train_idxs[idx]][0] img = img / 255. #將圖片除以255,讓向量介於0~1 features.append(img) labels_age.append(np.asarray([imagearr[train_idxs[idx]][1][1]/100])) labels_gender.append(np.eye(2)[int(imagearr[train_idxs[idx]][1][2])]) #np.eye(選項數)[索引]是快速建立one_hot的方法 else: img = imagearr[test_idxs[idx1]][0] img = img / 255. # 將圖片除以255,讓向量介於0~1 features.append(img) labels_age.append(np.asarray([imagearr[test_idxs[idx1]][1][1] / 100])) labels_gender.append(np.eye(2)[int(imagearr[test_idxs[idx1]][1][2])]) # np.eye(選項數)[索引]是快速建立one_hot的方法 except OSError as e: print(e) if is_train: idx+=1 if idx>=len(train_idxs): #如果取圖片序號超過 np.random.shuffle(train_idxs) idx = 0 else: idx1 += 1 if idx1 >= len(test_idxs): # 如果取圖片序號超過 np.random.shuffle(test_idxs) idx1 = 0 return np.asarray(features),np.asarray(labels_age).astype(np.float32),np.asarray(labels_gender).astype(np.float32) #如果是pytorch,必須改為np.asarray(labels_gender).astype(np.int64)
在這裡要示範的卷積神經網路骨幹網路用的是我最近很推崇的一篇文章所介紹的新架構「DenseNet」,原始論文出處如下。
Densely Connected Convolutional Networks
Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger
https://arxiv.org/abs/1608.06993
傳統的卷積網路都是線性的,但當層數越多時,就有可能發生梯度彌散的問題,造成模型無法收斂,所以微軟亞洲院2015年發展出的ResNet(殘差神經網路)就使用了跳轉連接(skip connection),來有效的將梯度挹注到後面神經層,這樣模型就可以做出超深的架構,也不用擔心難以收斂,微軟2015年就以152層的ResNet獲得了當年的imageNet冠軍。但是深度學習在訓練的過程中,當卷積神經網路將梯度傳送到後層的時候,都會發生特徵被隨機遺失,這樣這個特徵就在也傳不下去而無用了。為了解決這個問題,DenseNet的基本概念就是,每一層的特徵都會傳送到後面的「每」一層,這樣就可以有效的確保信號不被丟失。

DenseNet的基本結構稱之為「稠密單元(Dense Block)」,他有幾個重要的超參數:
k: 稠密單元層數
n_channel_start:初始通道數
glowth_rate:通道成長數
我們以下圖為例,假設下圖是一個k=4(向下傳遞4次,所以共5層),初始通道數32,成長數為16的Dense Block,我們分別計算每一層的輸入通道數(從前面傳進來的):
綠色:32+16(來自於紅色)=48
紫色:48+16(來自於綠色)=64
黃色:64+16(來自於紅色)+16(來自於綠色)=96
褐色:96+16(來自於紅色)+16(來自於綠色)+16(來自於紫色)=144
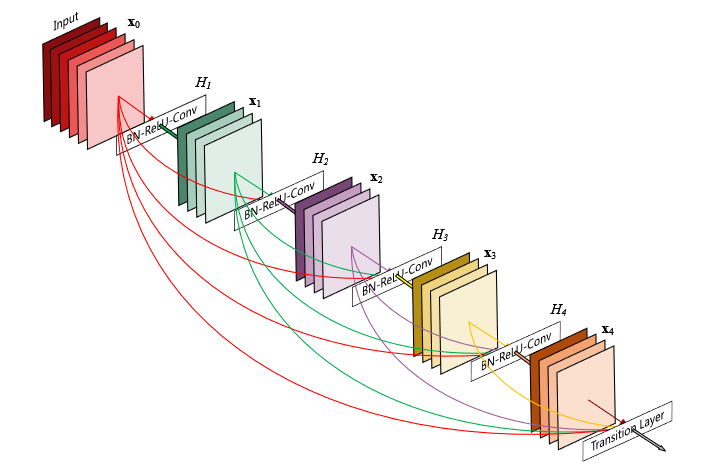
growth rate有就是每次會傳遞多少通道到後面的層數,以上面說明案例固定數值為16,但該卷積層的的通道數比這數字更大,因此等於是強迫每個卷積層要做一次特徵選取,將特徵精選之後傳至後方,這種「Save the best for last (讓人想起這首凡妮莎維廉斯的老歌)」,可以高度保全有效特徵,以強化模型的收斂。DenseNet就是利用多個DenseBlock構成的網路。

cntk與pytorch都沒有預設的DenseNet,所以我用自訂網路的方式實作了兩個框架下的DenseNet
#需要使用cntk 2.4(含)以上版本,才支持cpu下執行batch normalization #基本單元 def conv_bn(filter_size, num_filters, strides=(1, 1), init=he_normal(), activation=None, pad=True, bias=False,drop_rate=0.0,name=''): def apply_x(x): c = Convolution(filter_size, num_filters, activation=None, init=init, pad=pad, strides=strides,bias=bias,name=name)(x) r = BatchNormalization(map_rank=1, normalization_time_constant=4096, use_cntk_engine=False)(c) if drop_rate>0: r = dropout(r, drop_rate) if activation==None: return r else: return activation(r) return apply_x def dense_block(x, depth, growth_rate, drop_rate=0.0, activation=leaky_relu): for i in range(depth): b = conv_bn((3, 3), growth_rate, init=he_uniform(), drop_rate=drop_rate, activation=activation)(x) x = splice(x, b, axis=0) return x #每次transition down圖片長寬縮小1/2,因為strides=2 def transition_down(x,activation=leaky_relu, drop_rate=0): n_filters=x.shape[0] x = conv_bn((3, 3), n_filters*2,strides=2,pad=True, init=he_uniform(), drop_rate=drop_rate, activation=activation)(x) x = conv_bn((1, 1), n_filters, (1, 1), pad=True, drop_rate=drop_rate, activation=activation)(x) return x def down_path(x, depths, growth_rate, drop_rate=0, activation=leaky_relu): skips = [] n = len(depths) for i in range(n): x = dense_block(x, depths[i], growth_rate, drop_rate=drop_rate, activation=activation) skips.append(x) if i<n-1: n_filters=depths[i]*growth_rate x = transition_down(x, activation=leaky_relu) return skips, x
由於圖片只有64*64,經不起太多次圖片縮小,因此我使用了5層k=4的Dense Block(我測試過3層,收斂快,但是結果測試集落差很大,顯著過擬合)。由於我想要同時預測性別與年齡,cntk一個很神奇的特性就是可以在一個主要骨架下,同時接兩個輸出,只需要使用combine()函數,就可以將兩個輸出合併,未來只要做一次預測,就能產出兩個預測結果,而且訓練時也只要訓練一次,而且骨幹部分特徵選取流程不需要做兩次,是不是很方便呢。如果你是使用其他框架就只好做兩個模型了。預測性別部分,使用的是長度為2的向量,最後一層全連接層活化函數使用softmax已進行分類。預測年齡部分,由於我們讀取數據時已經將年齡除以100,因此年齡分布為0~1之間的常態分布,因此使用sigmoid函數效果較好。
def densenet(input,depths=(4, 4, 4, 4, 4), growth_rate=16, n_channel_start=32,drop_rate=0.5, activation=leaky_relu): x = conv_bn((3, 3), n_channel_start, pad=True, strides=1, init=he_normal(0.02), activation=activation,bias=True)(input) skips, x = down_path(x, depths, growth_rate, drop_rate=drop_rate, activation=leaky_relu) x = conv_bn((1, 1), 64, (1, 1), pad=True, drop_rate=0, activation=activation)(x) z_gender = Dense(2, activation=softmax, init=he_normal(), init_bias=0)(x) # 預測性別,使用softmax z_age=Dense(1,activation=sigmoid,init=he_normal(),init_bias=0)(x) #預測年齡,使用sigmoid,因為是預測連續數值,輸出為0~1 return combine([z_gender,z_age])
最後的訓練過程可以透過以下函數來控制。首先宣告輸入變數以及兩個輸出變數(性別與年齡),然後宣告模型、損失函數以及正確率指標。優化器使用的是adam,然後每50個minibatch就用測試集測試一次。
def train(): minibatch_size=64 learning_rate=0.001 epochs=20 # 定義輸入與標籤的變數 input_var = input_variable((3, 64, 64)) gender_var = input_variable(2) age_var = input_variable(1) # 宣告模型 z = densenet(input_var) # 定義損失函數與錯誤率 #性別損失函數使用cross_entropy_with_softmax,年齡則是使用均方根誤差(mse) #錯誤率性別是用分類錯誤率,年齡是用均方根誤差(mse) loss =cross_entropy_with_softmax(z[0], gender_var) +reduce_mean(squared_error(z[1], age_var)) error = (classification_error(z[0], gender_var)+sqrt(reduce_mean(squared_error(z[1], age_var))))/2 log_number_of_parameters(z); print() learner = C.adam( parameters=z.parameters, lr=C.learning_rate_schedule(learning_rate, C.UnitType.sample), momentum=C.momentum_schedule(0.95), gaussian_noise_injection_std_dev=0.001, l1_regularization_weight=10e-3, l2_regularization_weight=10e-4, gradient_clipping_threshold_per_sample=16) trainer = C.Trainer(z, (loss, error), learner) pp = C.logging.ProgressPrinter(10) trainstep = 2 for epoch in range(epochs): training_step = 0 while training_step <2000: raw_features, raw_age ,raw_gender= next_minibatch(minibatch_size) trainer.train_minibatch({input_var: raw_features, gender_var: raw_gender, age_var: raw_age}) pp.update_with_trainer(trainer, True) if training_step % 100 == 0 :#and training_step > 0: test_features, test_ages, test_genders = next_minibatch(minibatch_size,is_train=False) pred = z(test_features) print('性別錯誤率:{0:.2%}%'.format(np.mean( np.not_equal(np.argmax(pred[0],-1), np.squeeze(np.argmax(test_genders,-1))).astype(np.float32)))) avg_age = np.mean(test_ages)*100. avg_pred_age = np.mean(pred[1])*100. print('年齡均方根誤差:{0:.2%}%'.format( np.sqrt(np.mean(np.square(pred[1] - np.squeeze(test_ages)))))) print('實際平均年齡:{0:.2f}歲,平均預測年齡為{1:.2f}'.format(avg_age, avg_pred_age)) z.save('Models\hands_combine.cnn') training_step += 1 pp.epoch_summary(with_metric=True) z.save('Models\hands_combine.cnn')
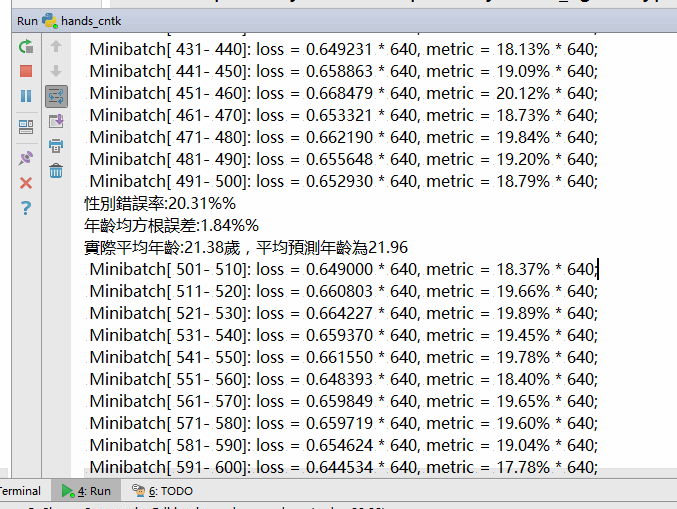
我使用gtx-1080 (minibatch size=64)跑完第3個epoch的結果如下,年齡誤差只有1.8%,性別目前仍有20.31%的錯誤率,看來手真的藏不住年齡啊。這個模型若是希望提升他的泛化效果,應該要在輸入數據加入數據增強,後續的文章中我會們在來介紹數據增強的作法,以及介紹如何將深度學習模型工程化,與硬體連接變成可以落地的實際應用,請期待後續文章。
cntk完整語法
import PIL from PIL import Image import numpy as np import random import math import datetime import pickle import cntk as C from cntk.ops import * from cntk.layers import * from cntk.initializer import * from cntk.logging import * from cntk.train import * from cntk.learners import * from cntk.losses import * from cntk.metrics import * from cntk.device import * # 是否使用GPU is_gpu = True if is_gpu: try_set_default_device(gpu(0)) imagearr=[] with open('Data/hands.pkl', 'rb') as fp: imagearr=pickle.load(fp) print(len(imagearr)) print(imagearr[0][0].shape) print(imagearr[0][1].shape) def img2array(img: Image): arr = np.array(img).astype(np.float32) arr=arr.transpose(2, 0, 1) #轉成CHW arr=arr[::-1] #顏色排序為BGR return np.ascontiguousarray(arr) def array2img(arr: np.ndarray): sanitized_img =arr[::-1]#轉成RGB sanitized_img = np.maximum(0, np.minimum(255, np.transpose(arr, (1, 2, 0))))#轉成HWC img = Image.fromarray(sanitized_img.astype(np.uint8)) return img idx=0 idx1=0 idxs=np.arange(len(imagearr)) np.random.shuffle(idxs) #打亂順序 train_idxs=idxs[:7500]#定義訓練集索引 test_idxs=idxs[7500:]#定義測試集索引 def next_minibatch(minibatch_size,is_train=True): global idx,idx1,train_idxs,test_idxs features = [] labels_age=[] labels_gender=[] while len(features) < minibatch_size: try: if is_train: img = imagearr[train_idxs[idx]][0] img = img / 255. #將圖片除以255,讓向量介於0~1 features.append(img) labels_age.append(np.asarray([imagearr[train_idxs[idx]][1][1]/100])) labels_gender.append(np.eye(2)[int(imagearr[train_idxs[idx]][1][2])]) #np.eye(選項數)[索引]是快速建立one_hot的方法 else: img = imagearr[test_idxs[idx1]][0] img = img / 255. # 將圖片除以255,讓向量介於0~1 features.append(img) labels_age.append(np.asarray([imagearr[test_idxs[idx1]][1][1] / 100])) labels_gender.append(np.eye(2)[int(imagearr[test_idxs[idx1]][1][2])]) # np.eye(選項數)[索引]是快速建立one_hot的方法 except OSError as e: print(e) if is_train: idx+=1 if idx>=len(train_idxs): #如果取圖片序號超過 np.random.shuffle(train_idxs) idx = 0 else: idx1 += 1 if idx1 >= len(test_idxs): # 如果取圖片序號超過 np.random.shuffle(test_idxs) idx1 = 0 return np.asarray(features),np.asarray(labels_age).astype(np.float32),np.asarray(labels_gender).astype(np.float32) #如果是pytorch,必須改為np.asarray(labels_gender).astype(np.int64) #需要使用cntk 2.4(含)以上版本,才支持cpu下執行batch normalization #基本單元 def conv_bn(filter_size, num_filters, strides=(1, 1), init=he_normal(), activation=None, pad=True, bias=False,drop_rate=0.0,name=''): def apply_x(x): c = Convolution(filter_size, num_filters, activation=None, init=init, pad=pad, strides=strides,bias=bias,name=name)(x) r = BatchNormalization(map_rank=1, normalization_time_constant=4096, use_cntk_engine=False)(c) if drop_rate>0: r = dropout(r, drop_rate) if activation==None: return r else: return activation(r) return apply_x def dense_block(x, depth, growth_rate, drop_rate=0.0, activation=leaky_relu): for i in range(depth): b = conv_bn((3, 3), growth_rate, init=he_uniform(), drop_rate=drop_rate, activation=activation)(x) x = splice(x, b, axis=0) return x #每次transition down圖片長寬縮小1/2,因為strides=2 def transition_down(x,activation=leaky_relu, drop_rate=0): n_filters=x.shape[0] x = conv_bn((3, 3), n_filters*2,strides=2,pad=True, init=he_uniform(), drop_rate=drop_rate, activation=activation)(x) x = conv_bn((1, 1), n_filters, (1, 1), pad=True, drop_rate=drop_rate, activation=activation)(x) return x def down_path(x, depths, growth_rate, drop_rate=0, activation=leaky_relu): skips = [] n = len(depths) for i in range(n): x = dense_block(x, depths[i], growth_rate, drop_rate=drop_rate, activation=activation) skips.append(x) if i<n-1: n_filters=depths[i]*growth_rate x = transition_down(x, activation=leaky_relu) return skips, x def densenet(input,depths=(4, 4, 4,4,4), growth_rate=16, n_channel_start=32,drop_rate=0.5, activation=leaky_relu): x = conv_bn((3, 3), n_channel_start, pad=True, strides=1, init=he_normal(0.02), activation=activation,bias=True)(input) skips, x = down_path(x, depths, growth_rate, drop_rate=drop_rate, activation=leaky_relu) x = conv_bn((1, 1), 64, (1, 1), pad=True, drop_rate=0, activation=activation)(x) z_gender = Dense(2, activation=softmax, init=he_normal(), init_bias=0)(x) # 預測性別,使用softmax z_age=Dense(1,activation=sigmoid,init=he_normal(),init_bias=0)(x) #預測年齡,使用sigmoid,因為是預測連續數值,輸出為0~1 return combine([z_gender,z_age]) def train(): minibatch_size=64 learning_rate=0.001 epochs=20 # 定義輸入與標籤的變數 input_var = input_variable((3, 64, 64)) gender_var = input_variable(2) age_var = input_variable(1) # 宣告模型 z = densenet(input_var) # 定義損失函數與錯誤率 #性別損失函數使用cross_entropy_with_softmax,年齡則是使用均方根誤差(mse) #錯誤率性別是用分類錯誤率,年齡是用均方根誤差(mse) loss =cross_entropy_with_softmax(z[0], gender_var) +reduce_mean(squared_error(z[1], age_var)) error = (classification_error(z[0], gender_var)+sqrt(reduce_mean(squared_error(z[1], age_var))))/2 log_number_of_parameters(z); print() learner = C.adam( parameters=z.parameters, lr=C.learning_rate_schedule(learning_rate, C.UnitType.sample), momentum=C.momentum_schedule(0.95), gaussian_noise_injection_std_dev=0.001, l1_regularization_weight=10e-3, l2_regularization_weight=10e-4, gradient_clipping_threshold_per_sample=16) trainer = C.Trainer(z, (loss, error), learner) pp = C.logging.ProgressPrinter(10) trainstep = 2 for epoch in range(epochs): training_step = 0 while training_step <2000: raw_features, raw_age ,raw_gender= next_minibatch(minibatch_size) trainer.train_minibatch({input_var: raw_features, gender_var: raw_gender, age_var: raw_age}) pp.update_with_trainer(trainer, True) if training_step % 100 == 0 :#and training_step > 0: test_features, test_ages, test_genders = next_minibatch(minibatch_size,is_train=False) pred = z(test_features) print('性別錯誤率:{0:.2%}%'.format(np.mean( np.not_equal(np.argmax(pred[0],-1), np.squeeze(np.argmax(test_genders,-1))).astype(np.float32)))) avg_age = np.mean(test_ages)*100. avg_pred_age = np.mean(pred[1])*100. print('年齡均方根誤差:{0:.2%}%'.format( np.sqrt(np.mean(np.square(pred[1] - np.squeeze(test_ages)))))) print('實際平均年齡:{0:.2f}歲,平均預測年齡為{1:.2f}'.format(avg_age, avg_pred_age)) z.save('Models\hands_combine.cnn') training_step += 1 pp.epoch_summary(with_metric=True) z.save('Models\hands_combine.cnn') train()
pytorch完整語法
import PIL from PIL import Image import os import time import random import math import datetime import pickle import numpy as np import torch import torch.nn as nn import torch.optim as optim from torch.autograd import Variable import torch.nn.functional as F import torchvision import torchvision.transforms as transforms imagearr=[] with open('Data/hands.pkl', 'rb') as fp: imagearr=pickle.load(fp) print(len(imagearr)) print(imagearr[0][0].shape) print(imagearr[0][1].shape) def img2array(img: Image): arr = np.array(img).astype(np.float32) arr=arr.transpose(2, 0, 1) #轉成CHW arr=arr[::-1] #顏色排序為BGR return np.ascontiguousarray(arr) def array2img(arr: np.ndarray): sanitized_img =arr[::-1]#轉成RGB sanitized_img = np.maximum(0, np.minimum(255, np.transpose(arr, (1, 2, 0))))#轉成HWC img = Image.fromarray(sanitized_img.astype(np.uint8)) return img idx=0 idx1=0 idxs=np.arange(len(imagearr)) np.random.shuffle(idxs) #打亂順序 train_idxs=idxs[:9000]#定義訓練集索引 test_idxs=idxs[9000:]#定義測試集索引 #pytorch數據讀取器會很不一樣 def next_minibatch(minibatch_size,is_train=True): global idx,idx1,train_idxs,test_idxs features = [] labels_age=[] labels_gender=[] while len(features) < minibatch_size: try: if is_train: img = imagearr[train_idxs[idx]][0] img = img / 255. #將圖片除以255,讓向量介於0~1 features.append(img) labels_age.append(np.asarray([imagearr[train_idxs[idx]][1][1]/100])) labels_gender.append(int(imagearr[train_idxs[idx]][1][2])) #pytorch的target必須為一維(長度=批次數),不可以是二維(n*1) else: img = imagearr[test_idxs[idx1]][0] img = img / 255. # 將圖片除以255,讓向量介於0~1 features.append(img) labels_age.append(np.asarray([imagearr[test_idxs[idx1]][1][1] / 100])) labels_gender.append(int(imagearr[test_idxs[idx]][1][2])) # pytorch的target必須為一維(長度=批次數),不可以是二維(n*1) except OSError as e: print(e) if is_train: idx+=1 if idx>=len(train_idxs): #如果取圖片序號超過 np.random.shuffle(train_idxs) idx = 0 else: idx1 += 1 if idx1 >= len(test_idxs): # 如果取圖片序號超過 np.random.shuffle(test_idxs) idx1 = 0 return np.asarray(features),np.asarray(labels_age).astype(np.float32),np.asarray(labels_gender).astype(np.int64) class DenseLayer(nn.Sequential): def __init__(self, in_channels, growth_rate): super().__init__() self.add_module('norm', nn.BatchNorm2d(in_channels)) self.add_module('relu', nn.ReLU(True)) self.add_module('conv', nn.Conv2d(in_channels, growth_rate, kernel_size=3, stride=1, padding=1, bias=True)) self.add_module('drop', nn.Dropout2d(0.2)) def forward(self, x): return super().forward(x) class DenseBlock(nn.Module): def __init__(self, in_channels, growth_rate, n_layers, upsample=False): super().__init__() self.upsample = upsample self.layers = nn.ModuleList([DenseLayer( in_channels + i * growth_rate, growth_rate) for i in range(n_layers)]) def forward(self, x): if self.upsample: new_features = [] for layer in self.layers: out = layer(x) x = torch.cat([x, out], 1) new_features.append(out) return torch.cat(new_features, 1) else: for layer in self.layers: out = layer(x) x = torch.cat([x, out], 1) # 1 = channel axis return x class TransitionDown(nn.Sequential): def __init__(self, in_channels): super().__init__() self.add_module('norm', nn.BatchNorm2d(num_features=in_channels)) self.add_module('relu', nn.ReLU(inplace=True)) self.add_module('conv', nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0, bias=True)) self.add_module('drop', nn.Dropout2d(0.2)) self.add_module('maxpool', nn.MaxPool2d(2)) def forward(self, x): return super().forward(x) class DenseNet(nn.Module): def __init__(self, in_channels=3, down_blocks=(4, 4, 4, 4, 4), growth_rate=16, out_chans_first_conv=32): super().__init__() self.down_blocks = down_blocks cur_channels_count = 0 skip_connection_channel_counts = [] ## First Convolution ## self.add_module('firstconv', nn.Conv2d(in_channels=in_channels, out_channels=out_chans_first_conv, kernel_size=3, stride=1, padding=1, bias=True)) cur_channels_count = out_chans_first_conv ##################### # Downsampling path # ##################### self.denseBlocksDown = nn.ModuleList([]) self.transDownBlocks = nn.ModuleList([]) for i in range(len(down_blocks)): self.denseBlocksDown.append( DenseBlock(cur_channels_count, growth_rate, down_blocks[i])) cur_channels_count += (growth_rate * down_blocks[i]) skip_connection_channel_counts.insert(0, cur_channels_count) self.transDownBlocks.append(TransitionDown(cur_channels_count)) # Softmax 預測性別使用## self.finalConv = nn.Conv2d(in_channels=cur_channels_count, out_channels=2, kernel_size=1, stride=1, padding=0, bias=True) self.fc = nn.Linear(8, 2) def forward(self, x): out = self.firstconv(x) skip_connections = [] for i in range(len(self.down_blocks)): out = self.denseBlocksDown[i](out) skip_connections.append(out) out = self.transDownBlocks[i](out) out = self.finalConv(out) out = out.view(out.size(0), -1) out = self.fc(out) return out def save_weights(model, epoch, loss, err): weights_fname = 'weights-%d-%.3f-%.3f.pth' % (epoch, loss, err) weights_fpath = "Models/{0}".format(weights_fname) torch.save({ 'startEpoch': epoch, 'loss': loss, 'error': err, 'state_dict': model.state_dict() }, weights_fpath) def load_weights(model, fpath): print("loading weights '{}'".format(fpath)) weights = torch.load(fpath) startEpoch = weights['startEpoch'] model.load_state_dict(weights['state_dict']) print("loaded weights (lastEpoch {}, loss {}, error {})" .format(startEpoch - 1, weights['loss'], weights['error'])) return startEpoch num_epochs=20 minibatch_size=16 learning_rate =1e-4 # 學習速率 model = DenseNet(in_channels=3, down_blocks=(4,4,4,4,4),growth_rate=16, out_chans_first_conv=32).cuda() #使用GPU optimizer = torch.optim.RMSprop(model.parameters(), lr=learning_rate, weight_decay=1e-4) criterion=nn.CrossEntropyLoss() print('epoch start') for epoch in range(num_epochs): mbs = 0 trn_loss = 0 trn_error = 0 while mbs < 100: raw_features, raw_age, raw_gender = next_minibatch(minibatch_size) #讀取數據 input, target = torch.from_numpy(raw_features), torch.from_numpy(raw_gender)#預測性別 #將numpy轉為variable input, target = Variable(input), Variable(target) #轉換為cuda input, target = input.cuda(), target.cuda() #使用GPU output = model(input) loss = criterion(output, target) optimizer.zero_grad()#這句一定要放在loss.backward()之前 loss.backward() optimizer.step() trn_loss += loss.data.item() pred_gender =output.cpu().max(1)[1].numpy()#.max(1)[1]相當於argmax actual_gender=target.cpu().numpy() err =np.sqrt(np.mean(np.not_equal(pred_gender, actual_gender))) trn_error += (1 - err) if mbs % 5 == 0 or mbs <= 5: print("Epoch: {}/{} ".format(epoch + 1, num_epochs), "Step: {} ".format(mbs), "Loss: {:.4f} ".format(loss.data.item()), "accuracy: {:.3%}".format(err)) mbs += 1 trn_loss /= 100 trn_error /= 100 save_weights(model, epoch, trn_loss, trn_error)
積
Allan Yiin
CTO, AsiaMiner