利用XPATH-Helper與htmlagilitypack 擷取網頁資料
話說htmlagilitypack這套件,在網路上已經很多前輩分享了!
小弟在此只是工作上應用的範例,等於是備忘錄嚕
閒字不打,直接開始嚕!!
工欲善其事,必先利其器!
第一步驟
首先先安裝chrome瀏覽器上的擴充元件XPATH Helper
使用方式
ctrl+shift+x
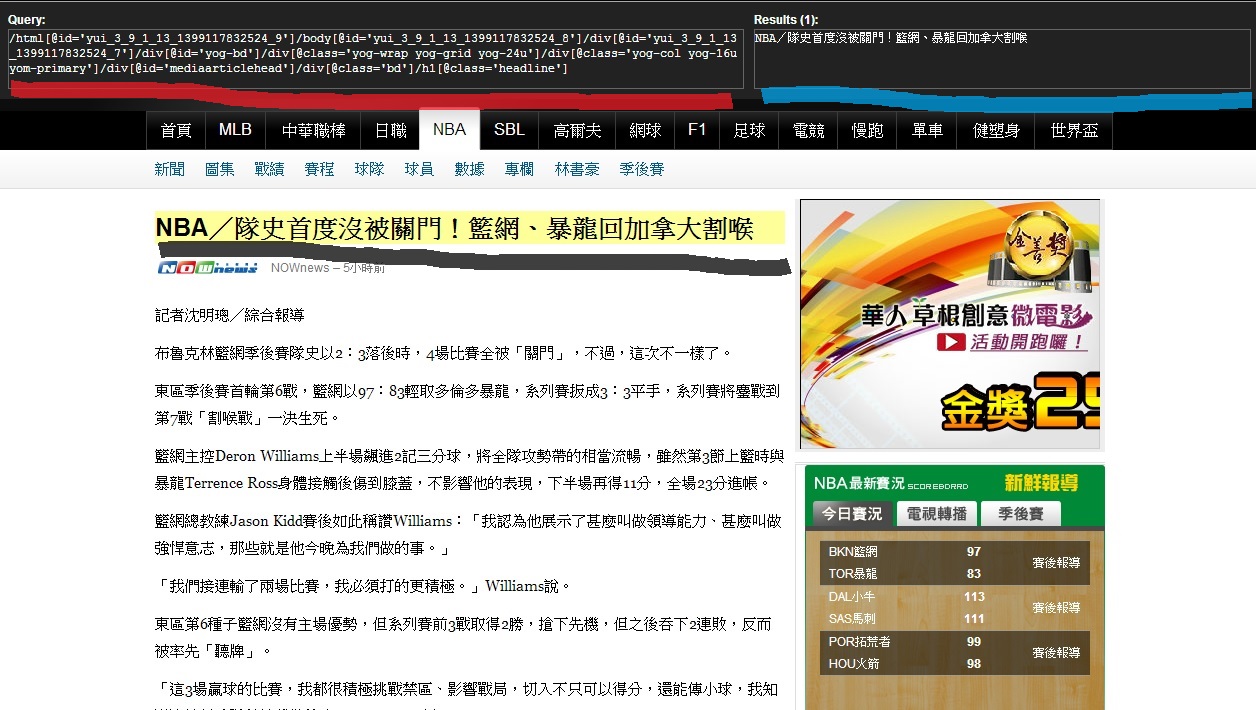
按著SHIFT 滑鼠移過去,左邊為XPATH的節點,右邊為選取的結果!
第二步驟
透過NUGET取得htmlagilitypack套件
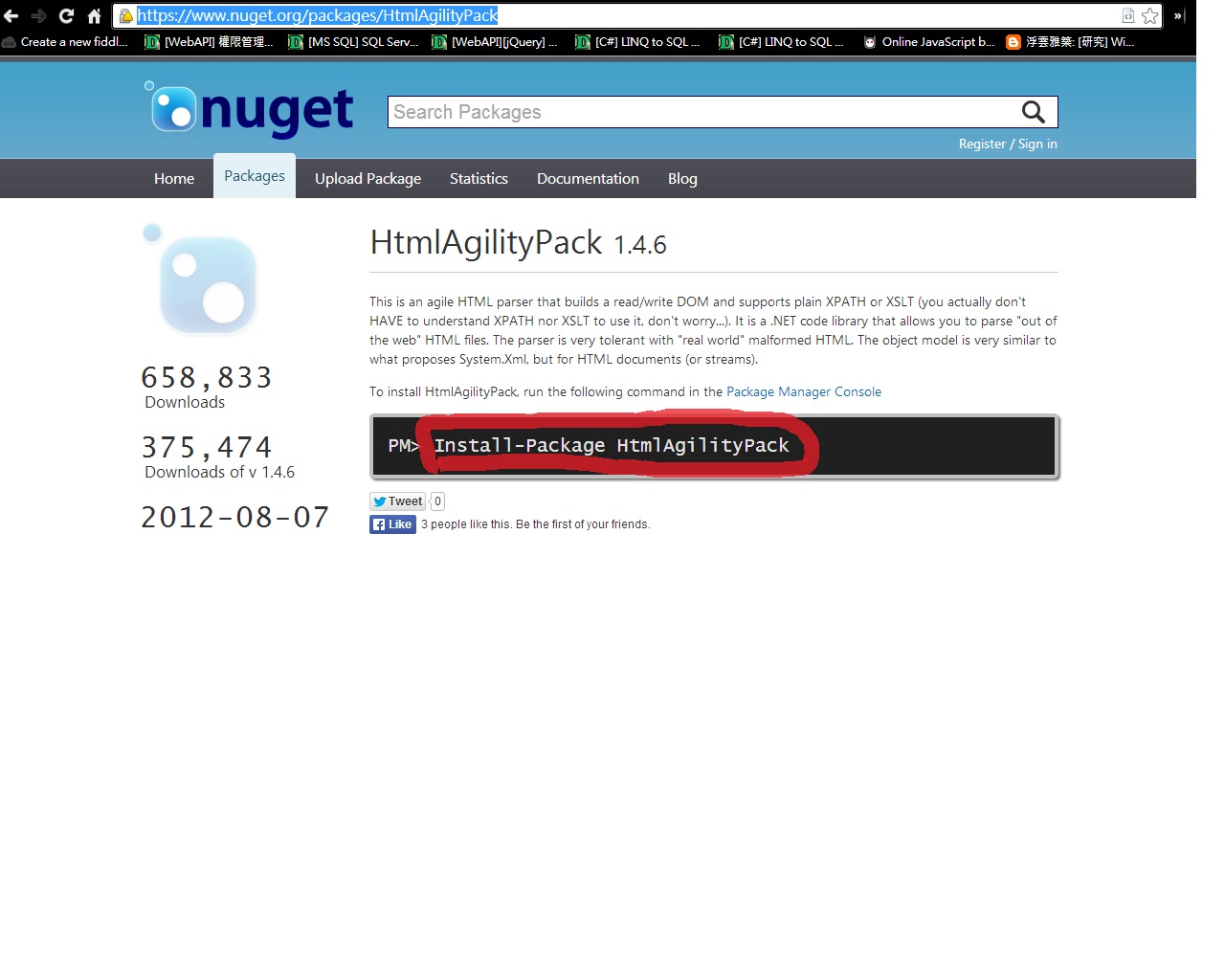
複製紅色圈起來的指令
開啟Visual studio 2012 > 工具 > NuGet套件管理員 > 套件管理器主控台
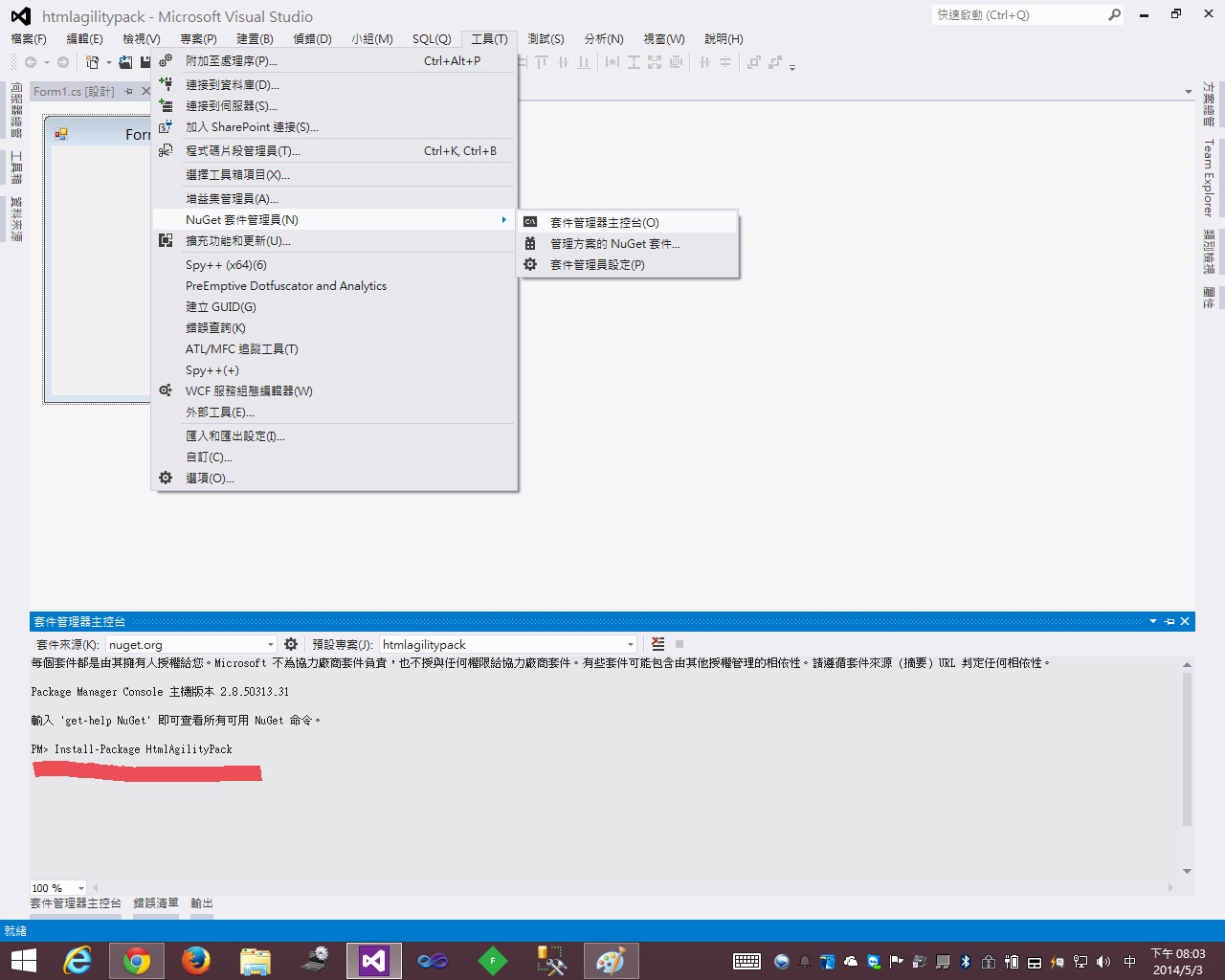
將複製的指令貼在下方的命令模式列,透過NuGet將htmlagilitypack做下載,主要可以幫你驗證套件版本相容性
步驟三
開始刻CODE了
先在畫面上拉出一個按鈕,兩個label
一個label放標題,另一個label放內容
當然一開始用將HtmlAgilityPack引用近來
using HtmlAgilityPack;再來在至按鈕事件中
///HtmlWeb 在此不多做介紹,就把它當作跟瀏覽器一樣的東西用來裝載網頁
HtmlWeb webClient = new HtmlWeb();
///將網址放入在webClient.Load
HtmlAgilityPack.HtmlDocument doc = webClient.Load("https://tw.sports.yahoo.com/news/nba-%E9%9A%8A%E5%8F%B2%E9%A6%96%E5%BA%A6%E6%B2%92%E8%A2%AB%E9%97%9C%E9%96%80-%E7%B1%83%E7%B6%B2-%E6%9A%B4%E9%BE%8D%E5%9B%9E%E5%8A%A0%E6%8B%BF%E5%A4%A7%E5%89%B2%E5%96%89-064933409.html");
///最後再第一步驟中利用XPATH helper將所要結點取出
///記得要把解取出來的如div[@id=xxxx] 拿掉因為在htmlagilitypack裡只能放數字如div[1]並未能直接解析ID的NAME或CLASS NAME
string title = doc.DocumentNode.SelectSingleNode(@"/html/body/div/div/div/div/div/div/h1").InnerText;
string content = doc.DocumentNode.SelectSingleNode(@"/html/body/div/div/div/div/div/div/div[1]/div/div").InnerText;
///將標題 放置label1中
titlelabel.Text = title;
///將內容 放置label2中
contentlabel.Text = content;
當然最後一定免不了秀出結果畫面嚕
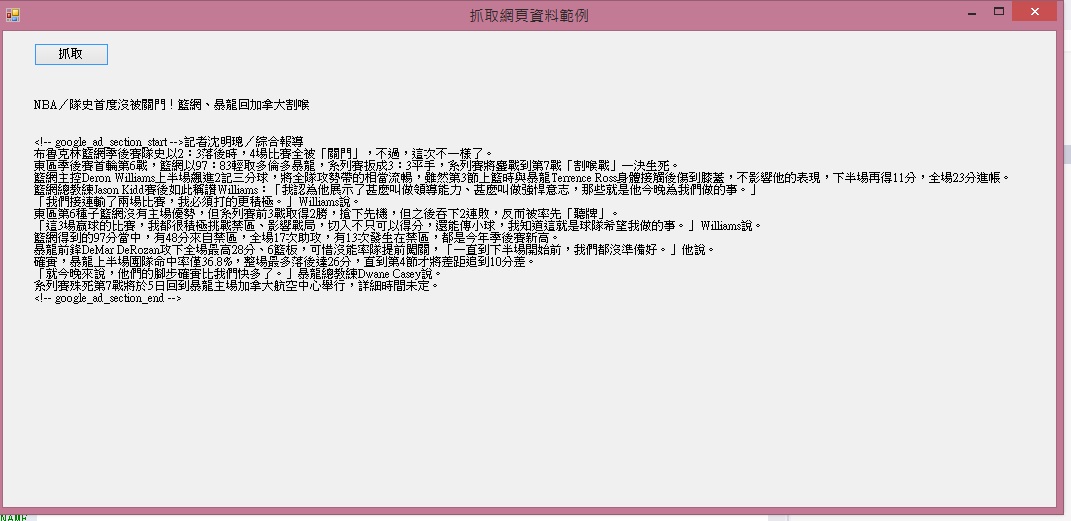
參考資料
-
HTML Agility Pack:簡單好用的快速 HTML Parser