端午節大家去划龍舟,我來划 GPU。分享一下從 llama.cpp 換到 SGLang 的過程。
之前用 llama.cpp 跑 Qwen3.6-27B,本來也覺得夠用了,但最近開始用 opencode 和 hermes-agent 兩個 AI 工具,兩個都要連同一台本機模型,問題就來了。
llama.cpp 的並行能力有限 — 本機的 MTP 模式強制 --parallel 1,同一時間只能服務一個請求。即使另一台伺服器開了 --parallel 3,並行時的總吞吐還是遠低於 SGLang。
SGLang 的多並行排程自動共享 GPU 資源,而且 AWQ 4-bit 格式的推理速度就比 Q4_K_XL GGUF 快一倍以上,於是決定把整個推論 stack 從 llama.cpp 換到 SGLang。
測試環境
兩台機器都是雙 RTX 3090,方便公平比較:
| 項目 | SGLang | llama.cpp |
|---|---|---|
| GPU | RTX 3090 x 2(48GB) | RTX 3090 x 2(48GB) |
| CPU | Xeon E5-2666 v3 10C/20T | AMD EPYC 9124 16-Core |
| RAM | 128GB | 128 GB |
| 框架 | SGLang 0.5.13 | llama.cpp + LiteLLM proxy |
| 模型格式 | AWQ (4-bit) | Q4_K_XL GGUF |
| KV Cache | RadixAttention | turbo4 |
| 並行設定 | 自動排程 | --parallel 3 |
| 實際 Context | 256K(--context-len 262144) | 393216(--ctx-size) |
Step 1:安裝 SGLang
先用 pyenv 裝 Python 3.10,然後建立 virtual environment:
pyenv install 3.10
pyenv local 3.10
python -m venv ~/sglang-env
source ~/sglang-env/bin/activate
pip install sglang[all]建議直接用 sglang[all],把 CUDA、vLLM 依賴、推理加速的套件一次裝齊。
Step 2:下載 AWQ 模型
huggingface-cli download zhiqing/Huihui-Qwen3.6-27B-abliterated-AWQ \
--local-dir ~/models/qwen3.6-27b-abliterated-awqStep 3:啟動服務
python -m sglang.launch_server \
--model-path ~/models/qwen3.6-27b-abliterated-awq \
--tp 2 \
--mem-fraction-static 0.90 \
--chunked-prefill-size 2048 \
--context-len 262144 \
--reasoning-parser qwen3 \
--tool-call-parser qwen3_coder \
--allow-auto-truncate \
--enable-multimodal \
--host 0.0.0.0 \
--port 8080參數說明
| 參數 | 說明 |
|---|---|
--tp 2 | Tensor Parallelism,兩張 GPU 平均分擔 |
--mem-fraction-static 0.90 | GPU 記憶體使用率,0.90 是甜蜜點 |
--context-len 262144 | 設定最大 context 長度為 256K,實際可用上限受 KV cache 總容量(202K)限制 |
--reasoning-parser qwen3 | 啟用推理鏈解析 |
--chunked-prefill-size 2048 | 大 context 分塊 prefill,避免一次塞爆 KV cache |
--tool-call-parser qwen3_coder | 啟用 tool call 解析 |
--allow-auto-truncate | 自動裁切過長輸入,避免 context 爆掉 |
--enable-multimodal | 啟用多模態(圖片輸入) |
等待約 60 秒讓模型載入完畢,跑以下指令確認:
tail -20 sglang-server.log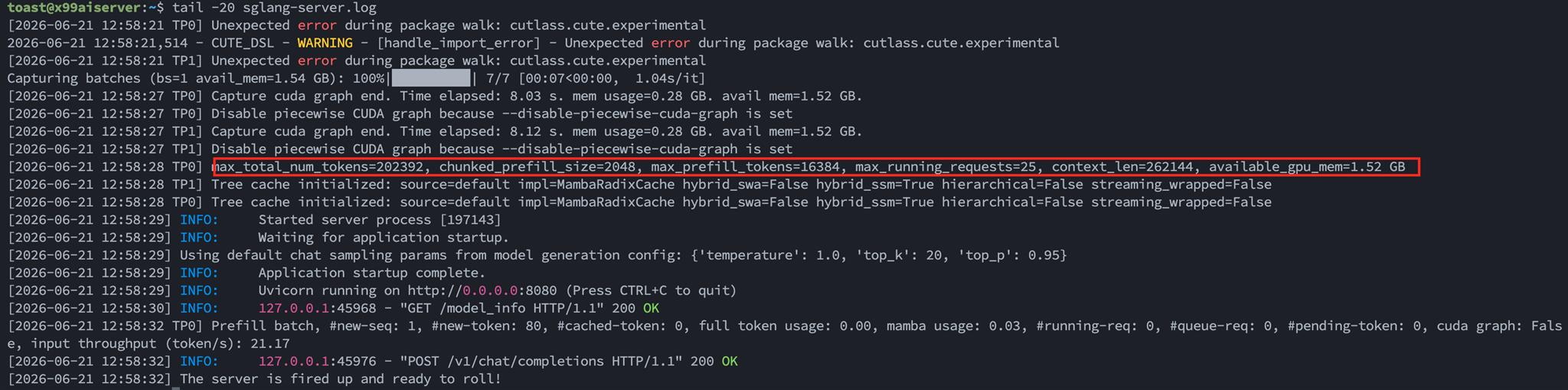
啟動 log,看到 max_total_num_tokens=202392
nvidia-smi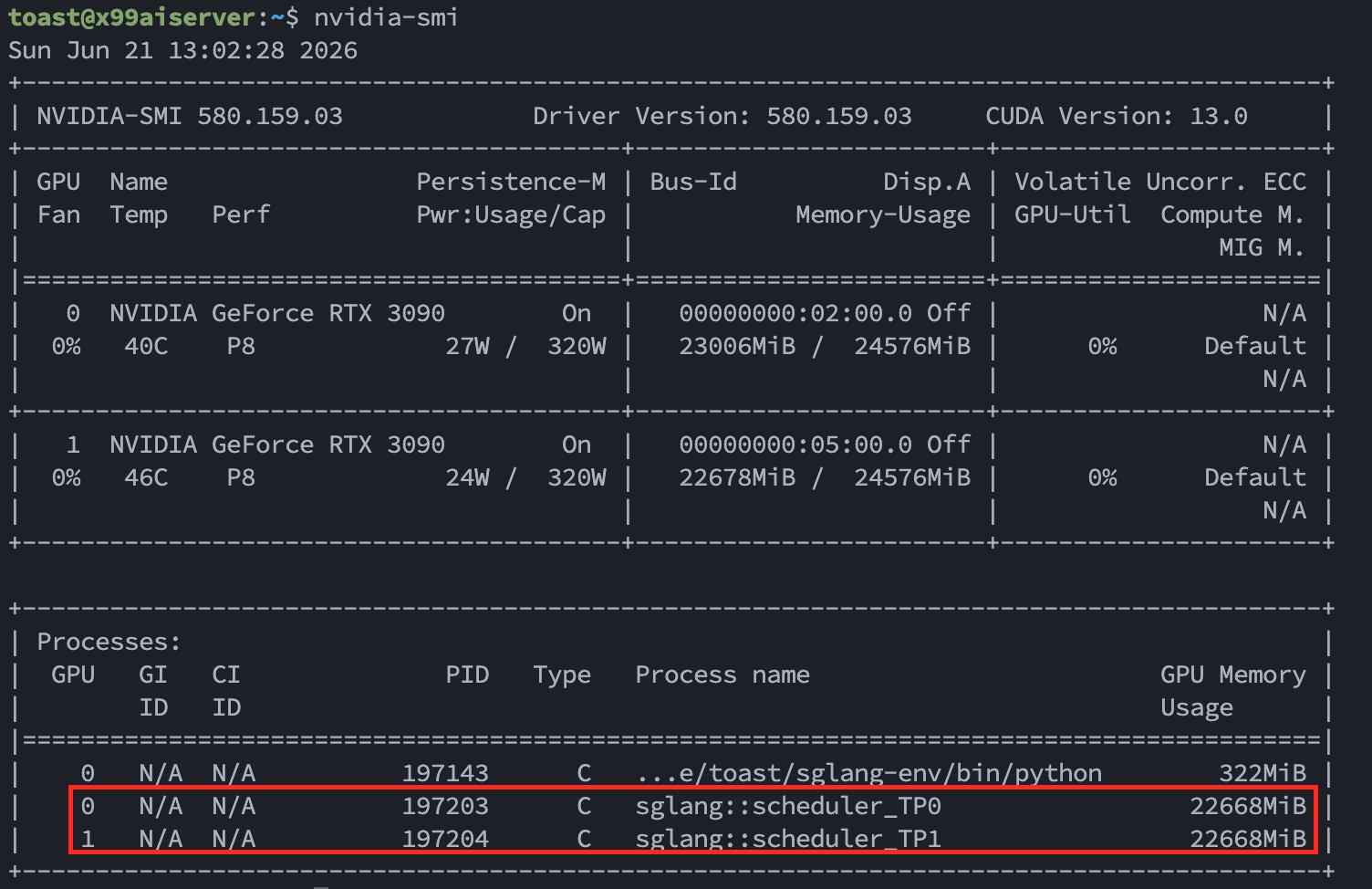
nvidia-smi,雙 GPU 各吃掉 ~23GB VRAM
curl http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model":"test","messages":[{"role":"user","content":"Say hello in 5 words."}],"max_tokens":20}'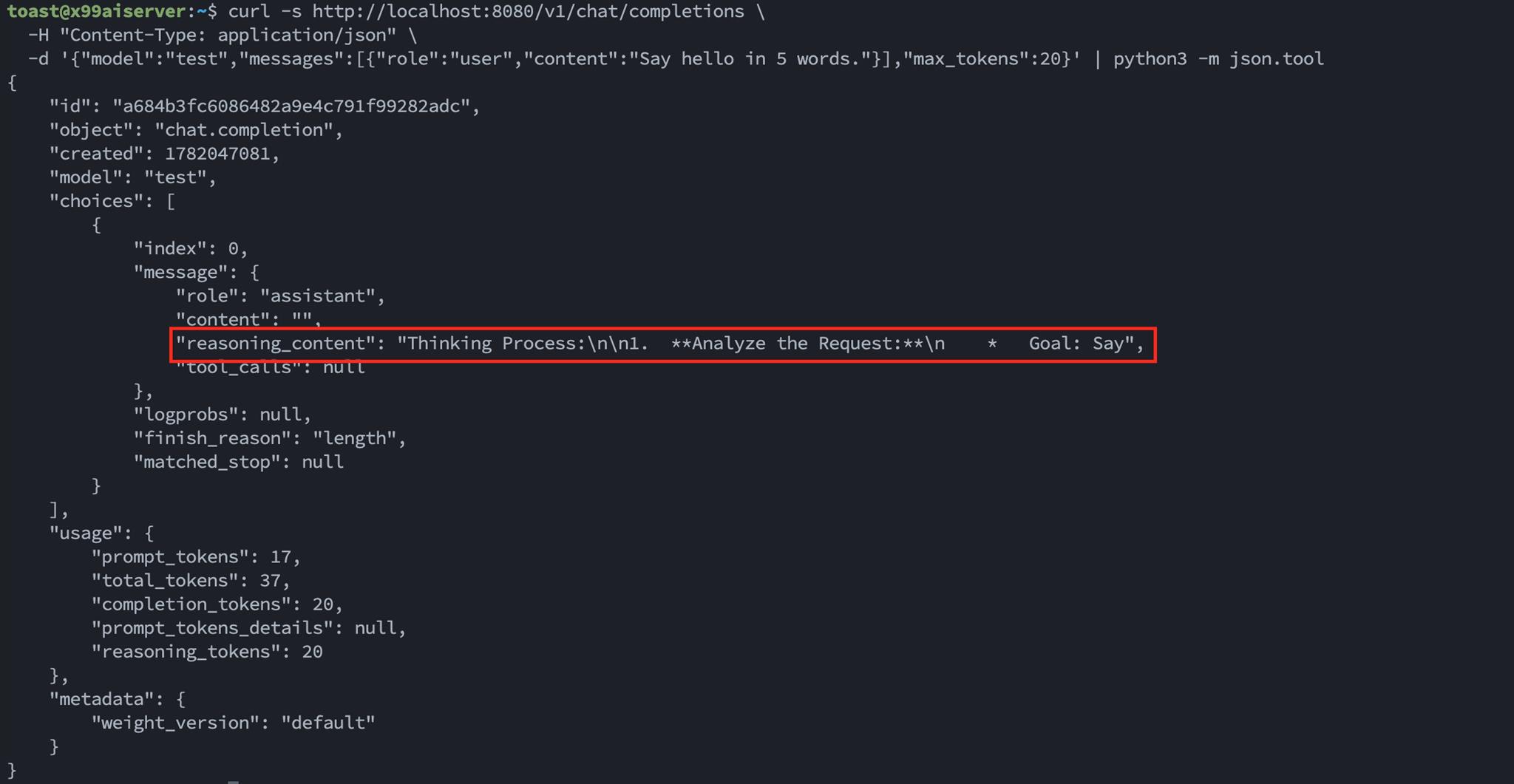
curl 回應,包含 reasoning_content 和 content 的 JSON
Step 4:設為系統服務
mkdir -p ~/.config/systemd/user
cat > ~/.config/systemd/user/sglang-server.service << 'EOF'
[Unit]
Description=SGLang Server (Qwen3.6-27B abliterated AWQ)
After=network.target
[Service]
Environment=PATH=/home/toast/.pyenv/shims:/home/toast/.pyenv/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/usr/sbin
Environment=PYENV_ROOT=/home/toast/.pyenv
WorkingDirectory=/home/toast
ExecStart=/home/toast/sglang-env/bin/python -m sglang.launch_server \
--model-path /home/toast/models/qwen3.6-27b-abliterated-awq \
--tp 2 \
--mem-fraction-static 0.90 \
--chunked-prefill-size 2048 \
--context-len 262144 \
--reasoning-parser qwen3 \
--tool-call-parser qwen3_coder \
--allow-auto-truncate \
--enable-multimodal \
--host 0.0.0.0 \
--port 8080
Restart=on-failure
RestartSec=30
StandardOutput=append:/home/toast/sglang-server.log
StandardError=append:/home/toast/sglang-server.log
[Install]
WantedBy=default.target
EOF
systemctl --user daemon-reload
systemctl --user enable --now sglang-server.servicesystemctl --user status sglang-server.service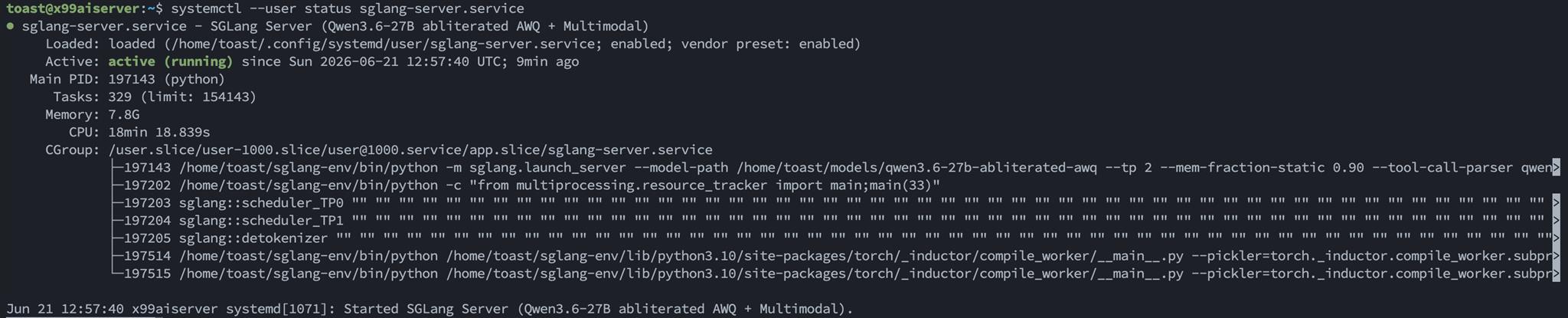
systemd 服務狀態,顯示 active (running) 和 uptime
llama.cpp vs SGLang — 實測比較
測試方式
兩台機器同樣的方法:用 curl 同時發射 N 個 200 token 的請求到背景,wait 等全部完成後算 wall time:
沒有用 load testing 工具,就是一次性並行發射然後看 wait 的總耗時。簡單粗暴,但足夠證明並行和串行的差異。
在 X99 執行:
START=$(date +%s%N)
for i in 1 2 3; do
curl -s http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model":"test","messages":[{"role":"user","content":"Write a 200 word essay about AI."}],"max_tokens":200}' \
-o /dev/null -w "Request $i: %{time_total}s\n" &
done
wait
END=$(date +%s%N)
echo "Wall time: $(( (END - START) / 1000000 ))ms"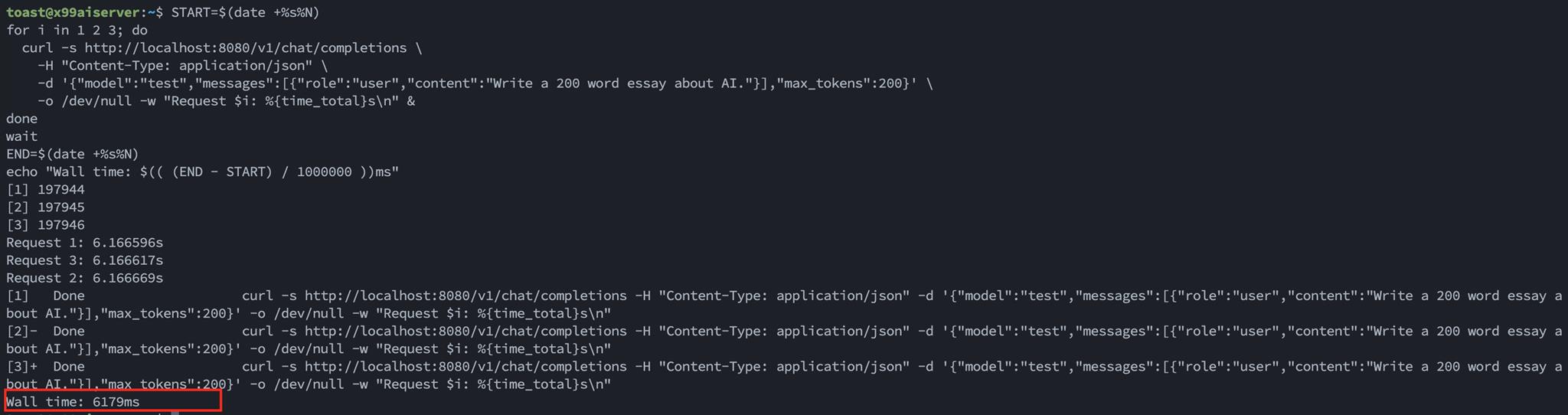
X99 3 並行測試,三個 Request 同時完成,Wall time ~6.1s
在 AI Server 執行:
START=$(date +%s%N)
for i in 1 2 3; do
curl -s http://localhost:4000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-a3z194IZkvYwd0vuA-YC0Q" \
-d '{"model":"qwen-pro","messages":[{"role":"user","content":"Write a 200 word essay about AI."}],"max_tokens":200}' \
-o /dev/null -w "Request $i: %{time_total}s\n" &
done
wait
END=$(date +%s%N)
echo "Wall time: $(( (END - START) / 1000000 ))ms"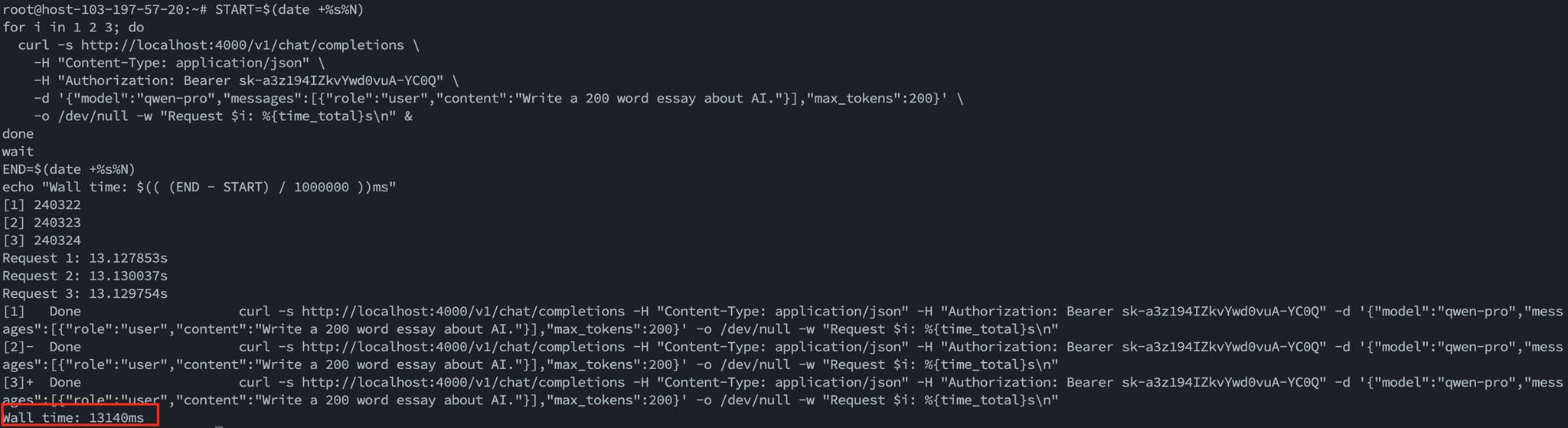
AI Server 3 並行測試,三個 Request 完成,Wall time ~13.1s
實測對比(200 tokens x N 個請求)
兩邊都是雙 RTX 3090、同樣的 Qwen3.6-27B,但格式和框架不同,速度差很多。
| 框架 | 並行數 | Wall Time | 總 token | 總吞吐 |
|---|---|---|---|---|
| SGLang AWQ | 1 | 6.21s | 200 | ~48 t/s |
| SGLang AWQ | 3 | 6.0s | 600 | ~100 t/s |
| llama.cpp Q4_K_XL | 1 | 13.18s | 200 | ~20 t/s |
| llama.cpp Q4_K_XL | 2 | 13.24s | 400 | ~36 t/s |
| llama.cpp Q4_K_XL | 3 | 13.51s | 600 | ~57 t/s |
SGLang AWQ 單請求就快 100%(6.2s vs 13.2s),因為 AWQ 4-bit 推理比 Q4_K_XL GGUF 快一倍。並行時差距更明顯:
| 場景 | SGLang AWQ | llama.cpp Q4_K_XL | SGLang 領先 |
|---|---|---|---|
| 3 請求 Wall Time | ~6.0s | 10.51s | 43% |
| 3 請求總吞吐 | ~100 t/s | 57 t/s | 75% |
SGLang 3 個並行只多花 1.8 秒(4.2 → 6.0s),但產出 3 倍 token。llama.cpp 雖然支援 --parallel 3,但總吞吐還是落在後面。
容量測試
同樣的方法,往上推並行數:
| 並行數 | Wall Time | 總吞吐 | 批次行為 |
|---|---|---|---|
| 5 | 8.7s | ~129 t/s | 1 batch,很順 |
| 10 | 11.4s | ~212 t/s | 1 batch,甜蜜點 |
| 15 | 13.2s | ~227 t/s | 1 batch,最大吞吐 |
| 20 | 16.9s | ~268 t/s | 1 batch,開始降速 |
| 25 | 31.7s | ~168 t/s | 2 批次,明顯卡頓 |
15 人同時用是甜蜜點。 15 個以內全部一次塞進 GPU 跑完,超過 15 個就開始分批排隊。AWQ 省下的 GPU 記憶體全變成 KV cache(202K tokens),所以能塞進更多人。
💡 吞吐量計算說明:目前測試用 總輸出 token ÷ Wall Time 計算,Wall Time 用 bash 的 date +%s%N 在迴圈前後抓時間差。
與 NVIDIA GenAI-Perf 的標準公式 Total output tokens / (Ty - Tx) 差異在於:
Wall Time 包含 curl 進程啟動的 overhead(毫秒級),GenAI-Perf 則精確從第一個 HTTP request 送出算到最後一個 token 收到。
詳細定義見 NVIDIA NIM Benchmarking - Tokens Per Second。
結論
多代理架構
之前的架構:
llama.cpp(MTP) → 單一模型服務
├── opencode(Mac 本機的 AI coding assistant)
└── hermes-agent(Telegram 群組 Bot)看起來只有兩個使用者,但實際問題是:
- llama.cpp 並行上限固定 — 本機 MTP 模式
--parallel 1,開了--parallel 3的另一台也排程效率低 - opencode 和 hermes-agent 經常同時發送請求(coding 時有人在群組問問題)
- 第二個請求完全乾等第一個完成,體驗很差
- 每次都要重新 prefill — 同樣的 system prompt 每次都重新算
換 SGLang 後,可以支撐多個 Agent:
SGLang
├── opencode(coding assistant)
├── hermes-agent ①(Telegram 群組 A)
├── hermes-agent ②(Telegram 群組 B)換 SGLang 的額外收穫:
- 多個 agent 並行跑,互不干擾
- RadixAttention 自動共用 system prompt 的 KV cache,prefill 變快
- OpenAI API 相容,每個 agent 只換 endpoint 就能用