在使用 OpenAI 的時候,Token 是會影響到呼叫的模型可接受的上限和回應結果以及計費時候也是以 Token 數量來計算,所以如何計算 Token 在要正式部署服務時候就很重要了,而不同模型間計算的方式也有所不同,本文後續就針對 Token 來做深入的探討和測試。
說明
如何粗估 Token
根據 OpenAI 這篇文章說明 Token 粗略的計算可以用以下規則來評估:
- 1 Token 約等於英文 4 個字元
- 1 Token 約等於 ¾ 個單字
- 100 Tokens 約等於 75 個單字
或是
- 1~2 句話約等於 30 Tokens
- 1 段文字約等於 100 Tokens
- 1500 個單字約等於 2480 Tokens
使用 Tokenizer 線上工具來計算 Token 數
但是這樣估算並非是太準確的,而且根據模型也會有差別,所以如果會需要較精確的計算 Token 的話可以用官方的工具 Tokenizer 來查詢,可惜的是目前僅針對 GPT-3 和 Codex 這兩個模型,ChatGPT 計算方式是不太一樣的,所以就沒有辦法使用這樣的方式來精確計算了。
底下用「中文字測試」來計算看看,結果會是 11 個字元。
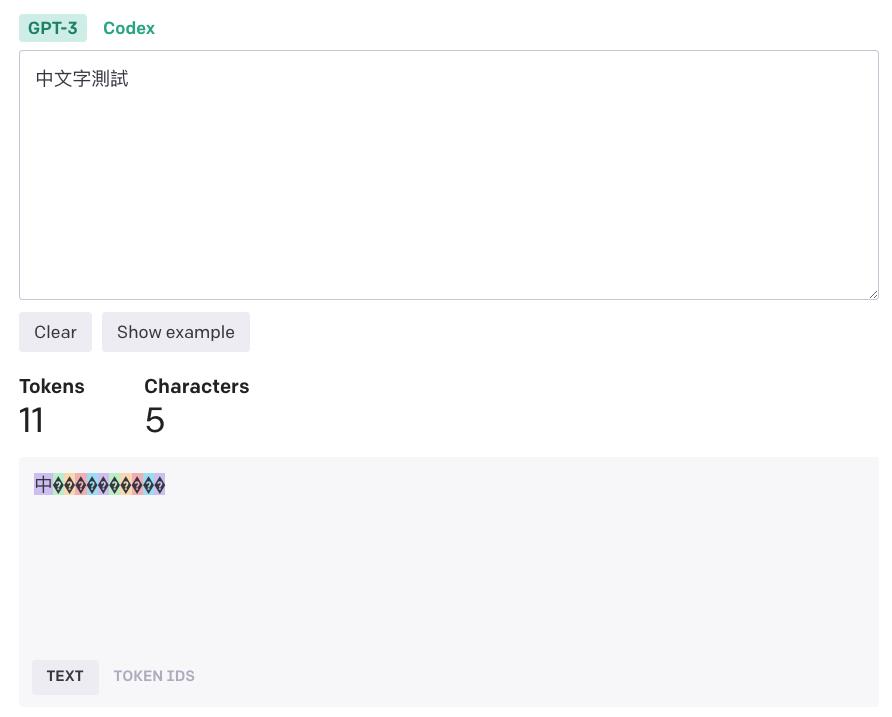
這時候如果點選底下的 TOKEN IDS 就可以看到文字是被轉換成怎樣的 Token。

使用官方套件 tiktoken 來計算 Token
那要我們想要計算 ChatGPT 所使用的 Token 數該怎麼辦呢?這時候可以參考 OpenAI 官方 How to count tokens with tiktoken 這份 Jupyiter notebook 文件。裡面有提到 tiktoken 這一個 Python 套件可以用來計算 Token,它是基於 BPE 標記器的開源套件。
我一樣測試「中文字測試」,然後選擇使用 ChatGPT 的模型來計算,可以得到結果是 6 個 Tokens 和前面的 11 Tokens 不一樣。
import tiktoken
encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")
test = encoding.encode("中文字測試")
print(test)
也找了一下 C# 的相關資料,有找到 TiktokenSharp 這一個開源專案,目前有實做好 ChatGPT 用的編碼,所以是可以拿來計算 Tokens 的,至於其他的計算編碼類型就等作者實做了,或是可以使用 GPT Tokenizer 這一個開源專案來計算。
但是因為 ChatGPT 需使用 ChatML 這個標記語言來作為 Prompt,所以計算上會稍微複雜,可以透過 OpenAI 官方提供的這段函示來計算。
def num_tokens_from_messages(messages, model="gpt-3.5-turbo-0301"):
"""Returns the number of tokens used by a list of messages."""
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
print("Warning: model not found. Using cl100k_base encoding.")
encoding = tiktoken.get_encoding("cl100k_base")
if model == "gpt-3.5-turbo":
print("Warning: gpt-3.5-turbo may change over time. Returning num tokens assuming gpt-3.5-turbo-0301.")
return num_tokens_from_messages(messages, model="gpt-3.5-turbo-0301")
elif model == "gpt-4":
print("Warning: gpt-4 may change over time. Returning num tokens assuming gpt-4-0314.")
return num_tokens_from_messages(messages, model="gpt-4-0314")
elif model == "gpt-3.5-turbo-0301":
tokens_per_message = 4 # every message follows <|start|>{role/name}\n{content}<|end|>\n
tokens_per_name = -1 # if there's a name, the role is omitted
elif model == "gpt-4-0314":
tokens_per_message = 3
tokens_per_name = 1
else:
raise NotImplementedError(f"""num_tokens_from_messages() is not implemented for model {model}. See https://github.com/openai/openai-python/blob/main/chatml.md for information on how messages are converted to tokens.""")
num_tokens = 0
for message in messages:
num_tokens += tokens_per_message
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name":
num_tokens += tokens_per_name
num_tokens += 3 # every reply is primed with <|start|>assistant<|message|>
return num_tokens傳入的資料範例為:
example_messages = [
{
"role": "system",
"content": "You are a helpful, pattern-following assistant that translates corporate jargon into plain English.",
},
{
"role": "system",
"name": "example_user",
"content": "New synergies will help drive top-line growth.",
},
{
"role": "system",
"name": "example_assistant",
"content": "Things working well together will increase revenue.",
},
{
"role": "system",
"name": "example_user",
"content": "Let's circle back when we have more bandwidth to touch base on opportunities for increased leverage.",
},
{
"role": "system",
"name": "example_assistant",
"content": "Let's talk later when we're less busy about how to do better.",
},
{
"role": "user",
"content": "This late pivot means we don't have time to boil the ocean for the client deliverable.",
},
]就可以使用底下的程式來驗證
for model in ["gpt-3.5-turbo-0301", "gpt-4-0314"]:
print(model)
# example token count from the function defined above
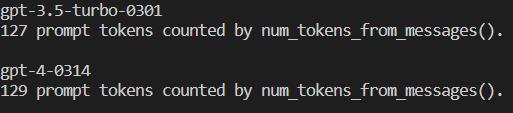
print(f"{num_tokens_from_messages(example_messages, model)} prompt tokens counted by num_tokens_from_messages().")
print()就可以得到以下的結果了。
Encodings
另外從 tiktoken 原始碼可以看到編碼方式總共有 5 種,我把編碼和對應的模型整理如下:
| 編碼名稱 | 適用模型 |
| cl100k_base | // chatgpt-3.5-turbogpt-4// embeddings text-embedding-ada-002 |
| p50k_base | // texttext-davinci-003text-davinci-002// code code-davinci-002code-davinci-001code-cushman-002code-cushman-001davinci-codexcushman-codex |
| r50k_base | // texttext-davinci-001text-curie-001text-babbage-001text-ada-001davincicuriebabbageada// old embeddings text-similarity-davinci-001text-similarity-curie-001text-similarity-babbage-001text-similarity-ada-001text-search-davinci-doc-001text-search-curie-doc-001text-search-babbage-doc-001text-search-ada-doc-001code-search-babbage-code-001code-search-ada-code-001 |
| p50k_edit | // edittext-davinci-edit-001code-davinci-edit-001 |
| gpt2 | gpt2 |
結論
本文僅針對如何計算 Token 整理了一些相關的資訊和可以使用的函示庫,這些應該對於想用程式來計算 Token 已經足夠了,而正確的 Token 計算除了影響到價錢之外,每個模型每次呼叫的時候也會有 Token 上限,這時候就可以事先計算好是否會超過,這時候可以參考這篇文章,把文本分段做摘要,然後再把這些摘要匯總之後再做摘要的方式來處理。



