微軟將 Azure AI Studio 以及 Azure Open AI 和其他 Azure AI 的服務整合之後推出了 Azure AI Foundry 這一個服務平台,讓我們在使用 Azure AI 服務的時候有同一個入口來管理和使用 Azure AI 的服務,而我們也可以在上面部署各式各樣的 LLM 模型,包含 Azure OpanAI 都可以在這邊部署並提供一個遊樂場讓我們可以免寫程式來測試部署好的 LLM 模型,後面就來介紹如何部署以及測試,最後也實做程式要來串接部署好的模型。

說明
Azure AI Foundry 的網址 (https://ai.azure.com/) 相當好記,就算不特別加入瀏覽器我的最愛也不太會忘記,首先連到 Azure AI Foundry 並透過 Azure 帳號登入。
導覽
第一次進來的話應該會是類似下面的畫面,因為我們要來部署 LLM 模型,所以點選探索模型按鈕來察看 Azure AI Foundry 有提供哪些模型可以使用。
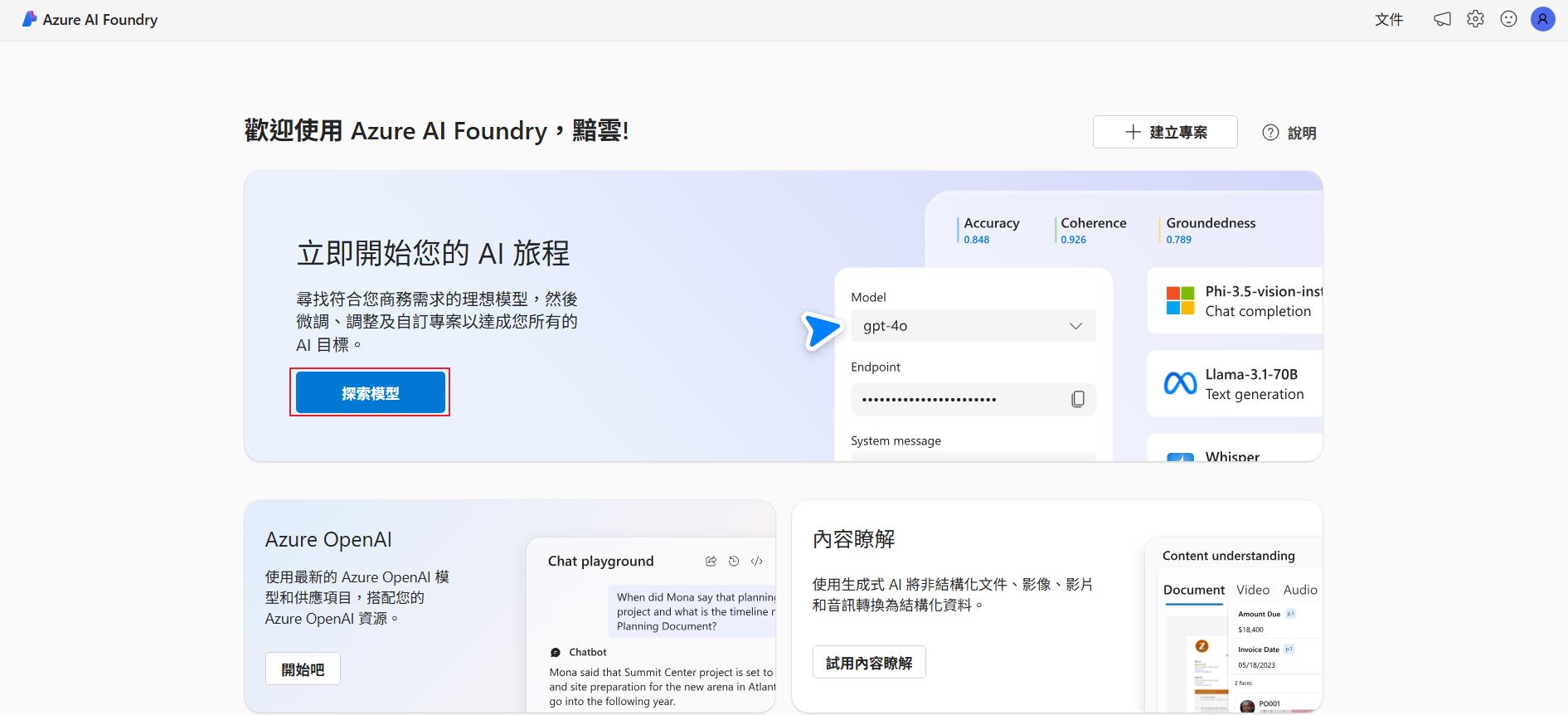
就本文撰寫的時間點來看目前提供了 1922 個 LLM 模型可以使用,也包含前幾天 OpenAI 才推出的 gpt-image-1 這個文字轉圖片的模型。
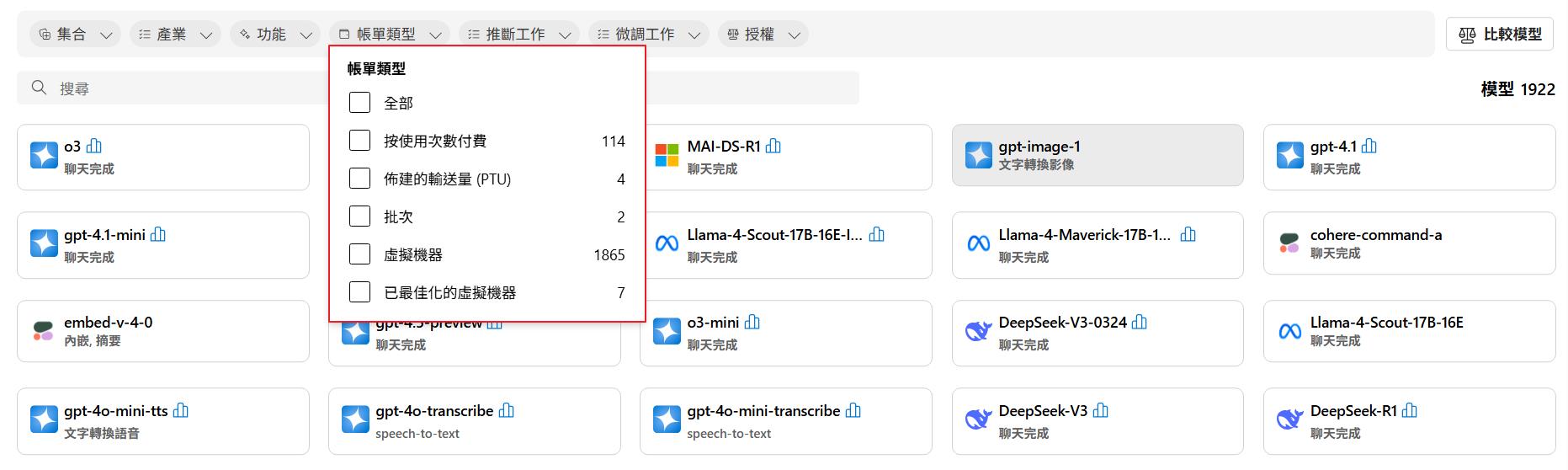
這邊要特別說明的是篩選條件的帳單類型,這會影響到我們的費用。
- 按使用次數付費:在這個條件下的模型可以建立起來 Serverless 的模型端點,計費方式是使用次數或是 Token 數量來計費。
- 佈建的輸送量 (PTU):這個條件篩選出來的是支援 PTU 計費的模型,PTU 可以想成 AI 的 RI,可以承諾一定的用量,而費用會有較大的折扣,目前支援的模型都是 OpenAI 的模型。
- 批次:支援批次的模型會是把每次的請求加入排程,會按照序列來處理結果,適合不需要及時回應的情境,通常費用也會較便宜一點,目前支援的也是 OpenAI 的模型。
- 虛擬機器:就是會建立虛擬機器來部署模型,費用就是虛擬機器的費用,但是通常會建立支援 GPU 的虛擬機器,所以費用也相對的貴。
- 已最佳化的虛擬機器:最佳化的虛擬機器是 Nvidia 的虛擬機器。
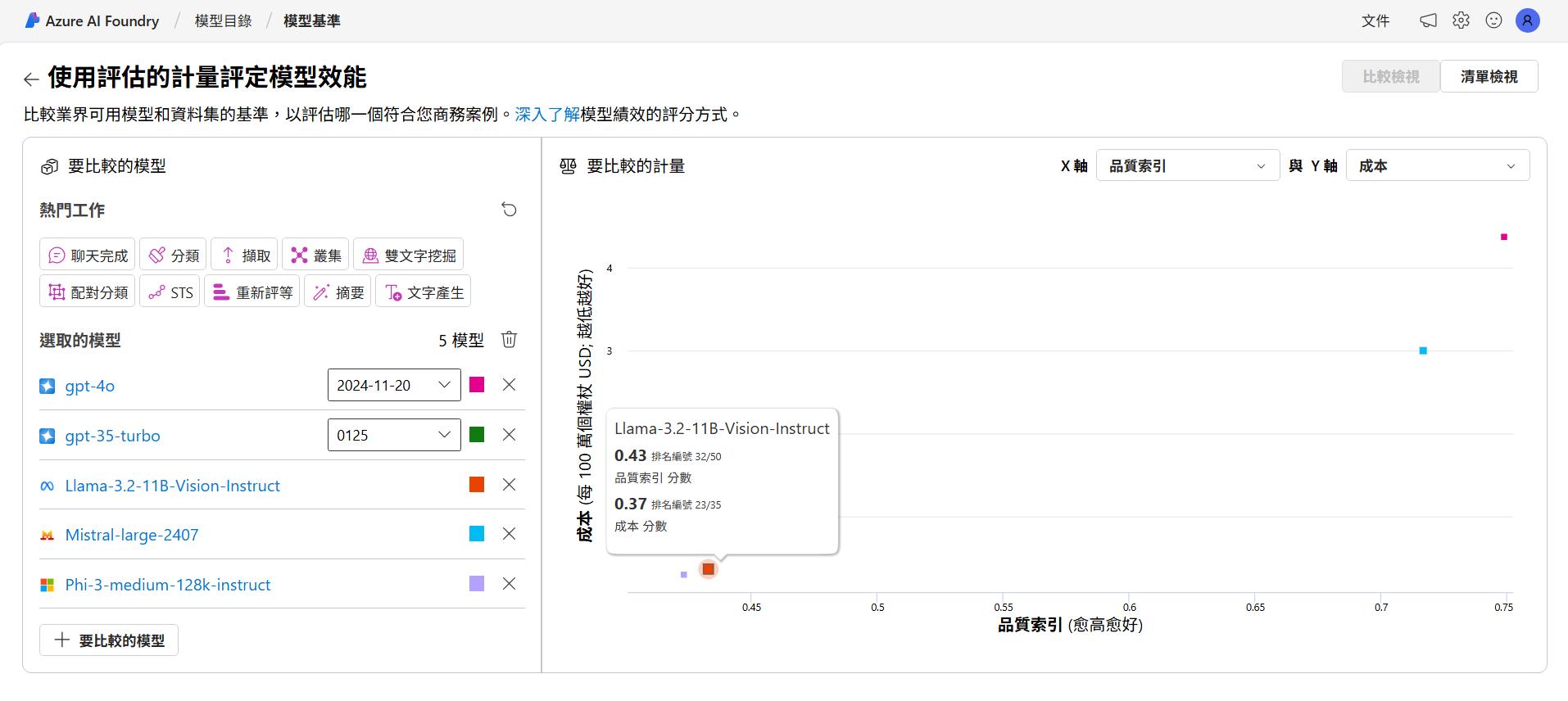
再來介紹一下比較模型這個功能,目前模型一直推陳出新,我們想要知道每個模型的效能、費用等等的比較,就可以點選右邊的比較模型來挑選模型來比較。
透過這個功能就可以挑選我們想要測試的模型,可以選擇想要比較的座標軸來比較,讓我們在挑選的時候有些參考的依據可以來評估要使用的模型。
部署模型
這邊我挑選微軟推出的 Phi-4 模型,因為它同時支援部署 Serverless 和虛擬機器的方式,後面可以來比較差異,點選左邊的部署按鈕來部署。
建立專案
首先會需要選取或是建立專案,它可以把我們要部署的 AI 服務關連在一起,比如說我們要針對某個情境來建立許多的 AI 服務,就可以關連在同一個專案裡面,未來要刪除也會比較方便。
再來會要選擇或是建立中樞 (Azure AI Hub),這個服務是可以共用的,它主要作用是可以管理和設定網路、安全性等,就可以讓多個專用共用同一組數定,方便 IT 人員管理相關的權限和安全性,比如說限制部署好的 LLM 模型的節點只有特定 IP 可以連線等,其他就保留預設值來建立。
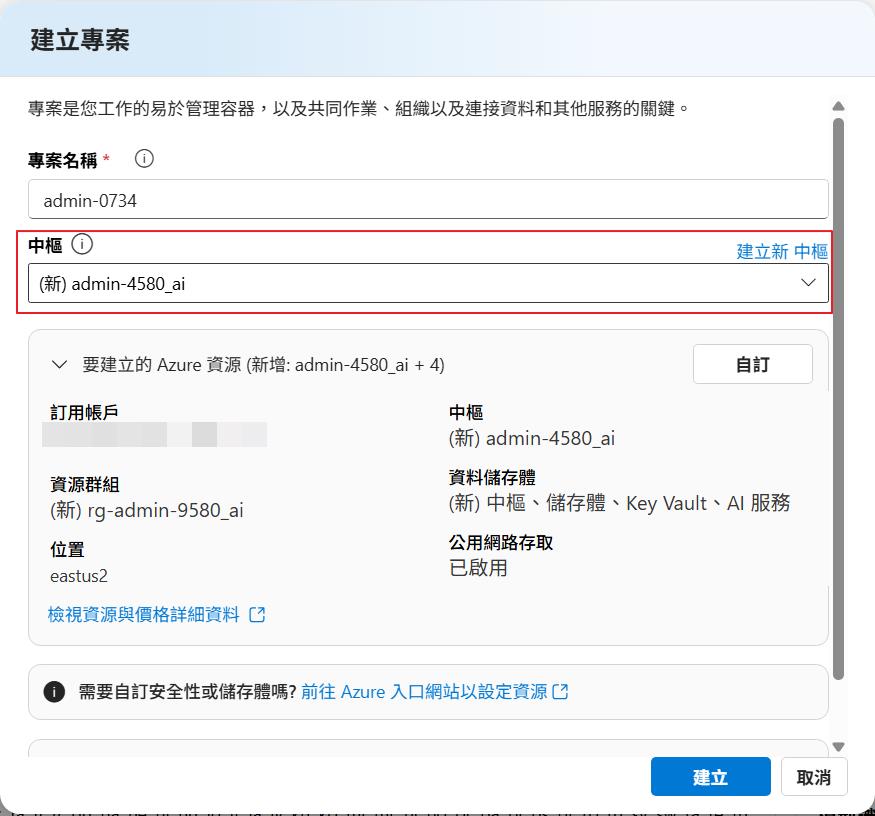
下一步就會列出會建立出來哪些服務出來,到這邊所建立出來的服務都還不會產生太多的費用,會有計費的項目就是儲存體帳戶和金鑰保存庫,這些都是有用到才會計費的項目。
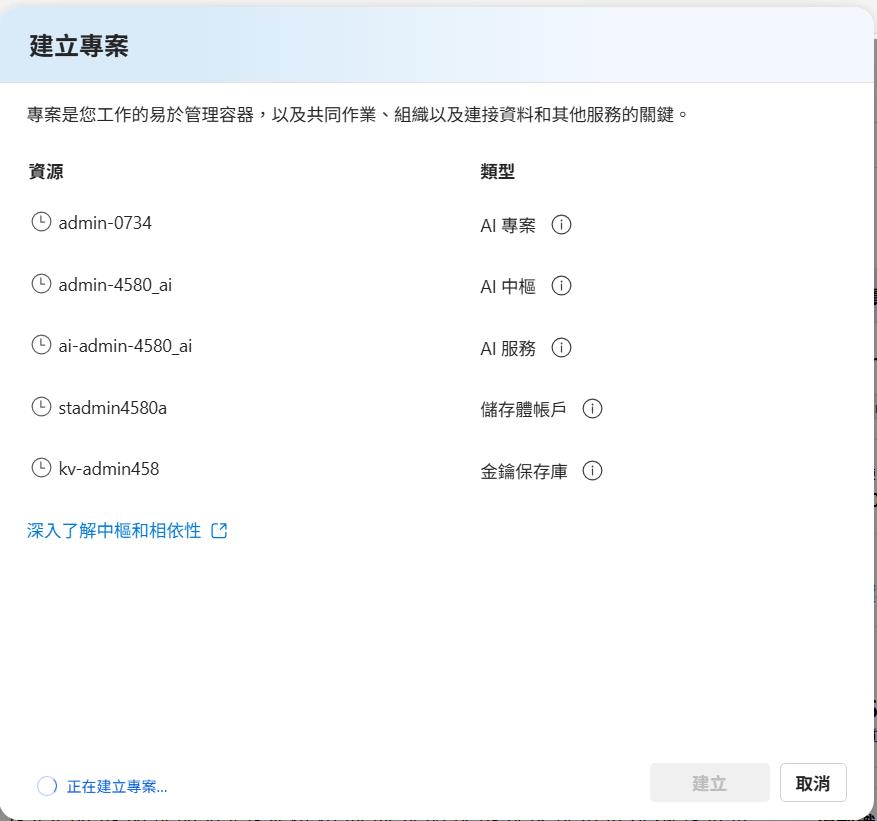
無伺服器部署
再來就是正式的部署了,因為特別挑選了支援兩種模式的模型,左邊就是 Serverless 的,右邊就是虛擬機器的,部署完之後都可以得到一個 Api 節點讓我們可以來呼叫使用,這邊先示範 Serverless 的,就選擇左邊的模式來部署。
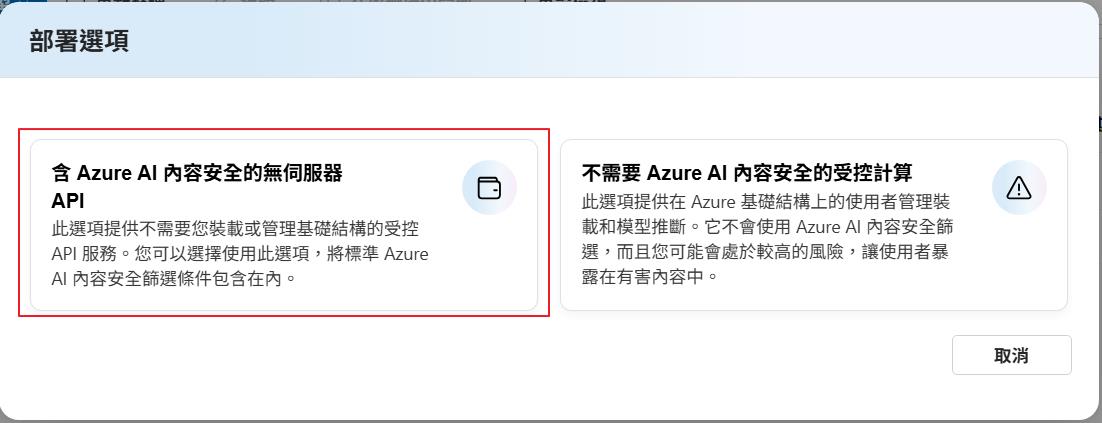
下個部署可以選擇是否要做內容篩選,建立正式環境一定要選取,才可以避免使用者詢問了一些問題導致模型回應一些不安全的內容給使用者。
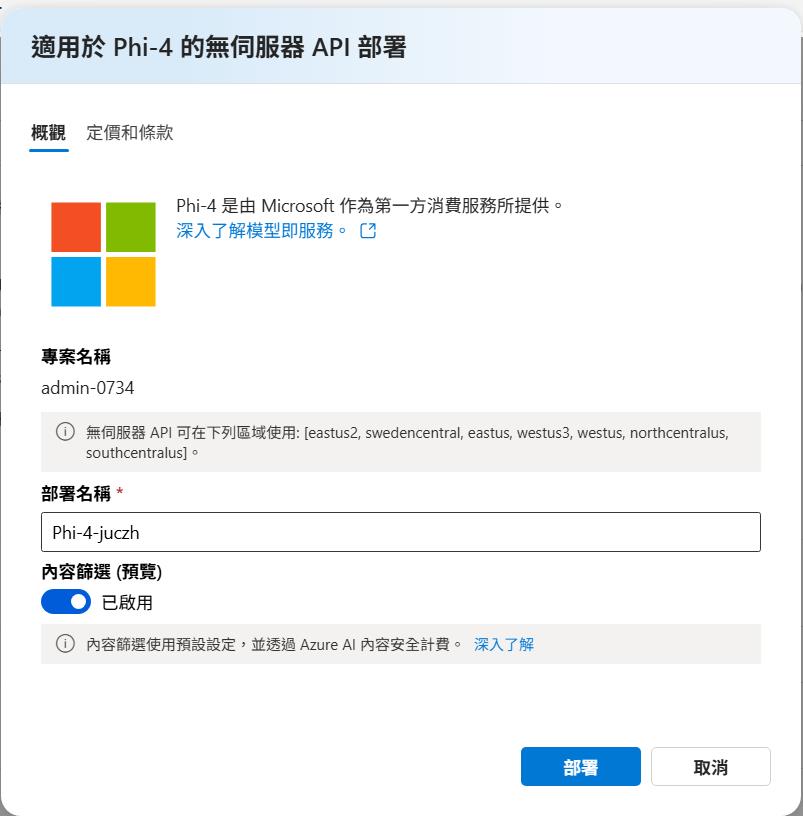
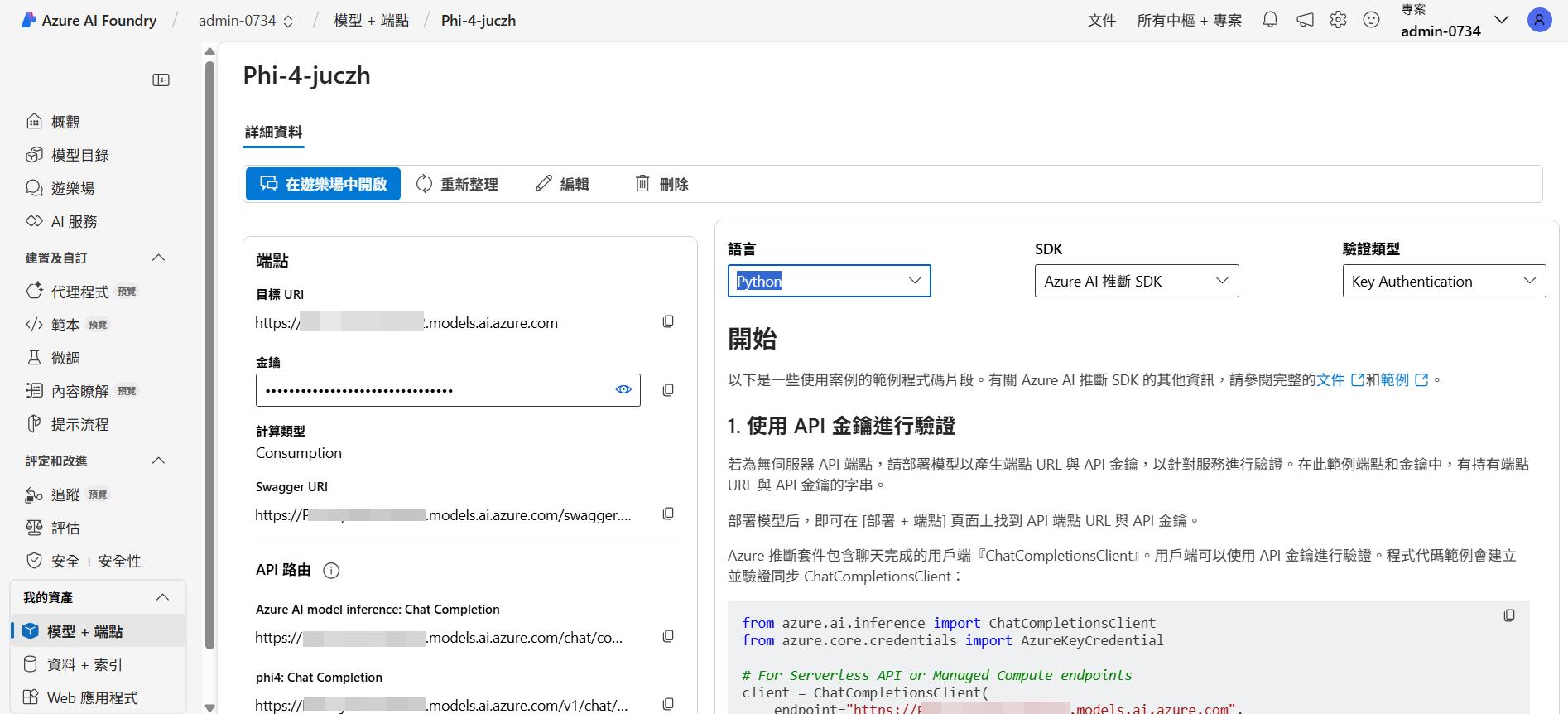
部署好之後就可以看到節點和金鑰,而支援的 Api 路由就類似 OpenAI 的模型的完成等方法可以使用,後面開發上就可以用支援的套件或是同樣的程式來呼叫,不同模型只需要換掉節點和金鑰就可以了,右邊也會有程式碼範例可以參考,目前支援的程式語言包含了常見的 Python、Javascript、Rest、Java、C# 等。
虛擬機器部署
再來示範部署虛擬機器的類型,點選模型+端點來部署模型。
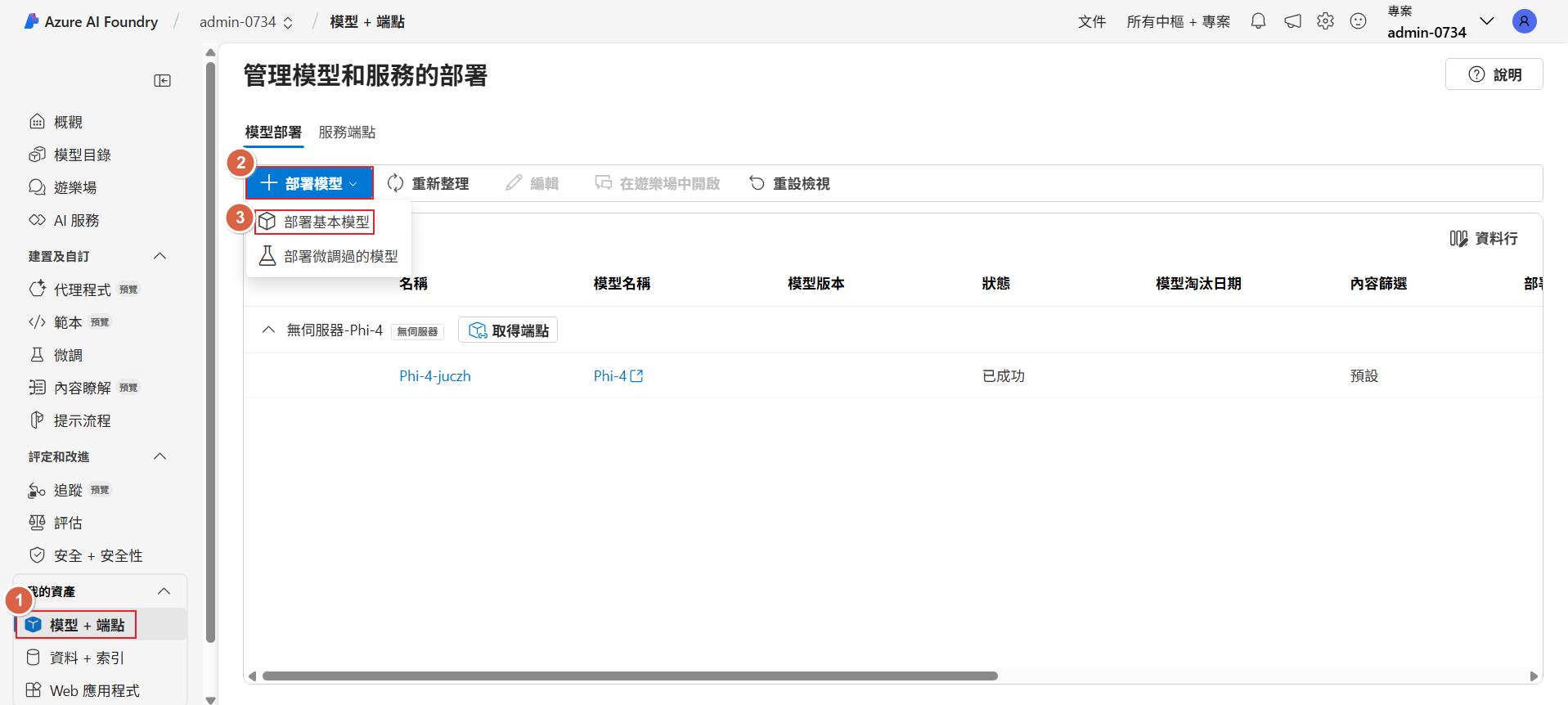
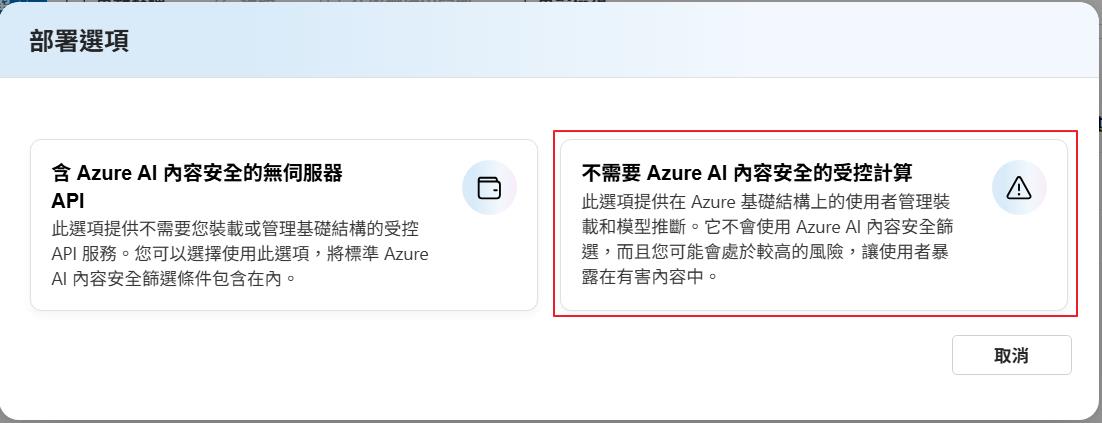
一樣選擇 Phi-4 模型,就會在出現前面的選項可以選擇,這次我們選右邊的選項。
因為我的訂閱沒有 GPU 系列的虛擬機器的核心數額度,但是我們可以把下面的選項打勾,就可以建立共用資源的虛擬機器來建立節點,而這個模式要注意的是測試完畢記得刪掉,不然就會一直計費,而這個模式在建立上也會比較花時間。
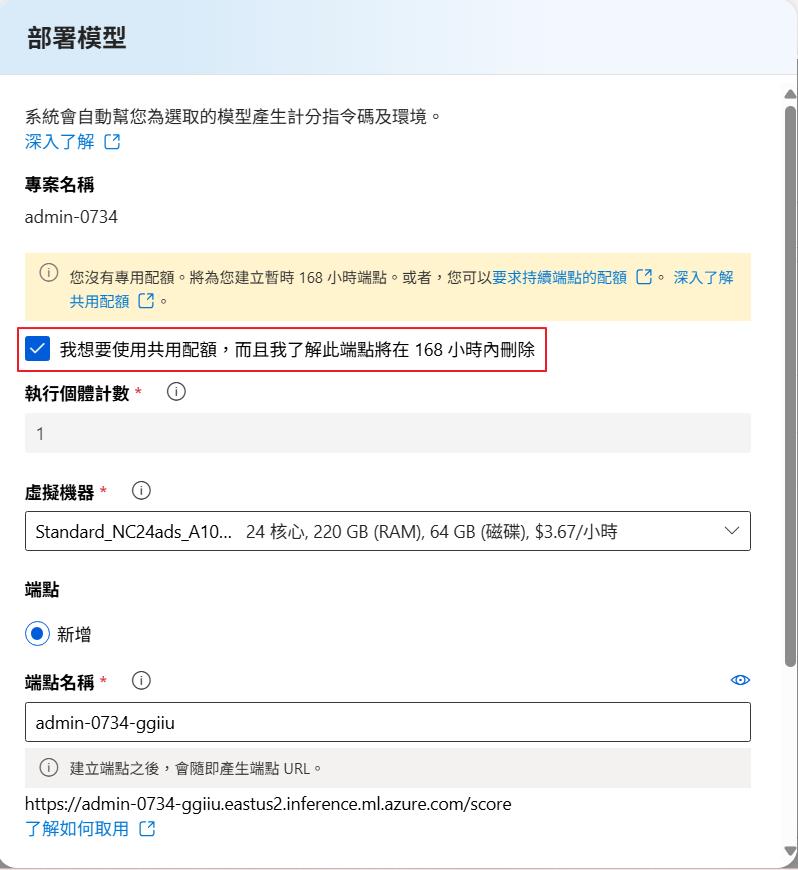
部署好之後就會看到列表有兩種不同類型的節點可以使用。
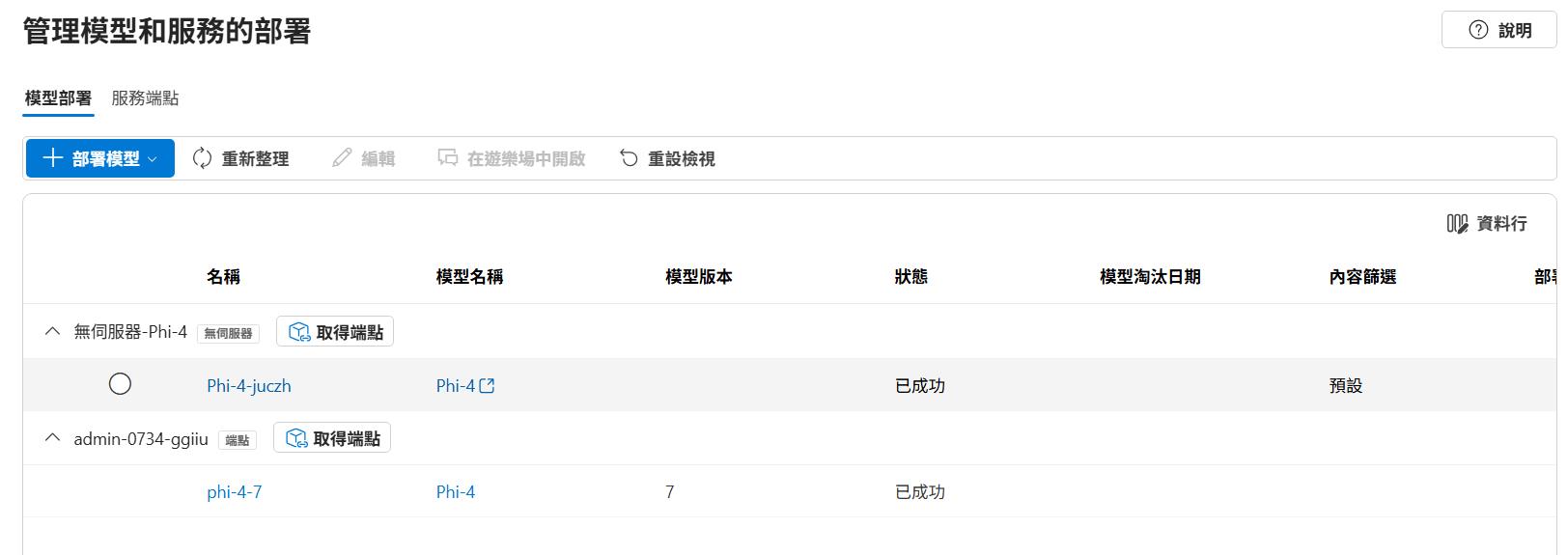
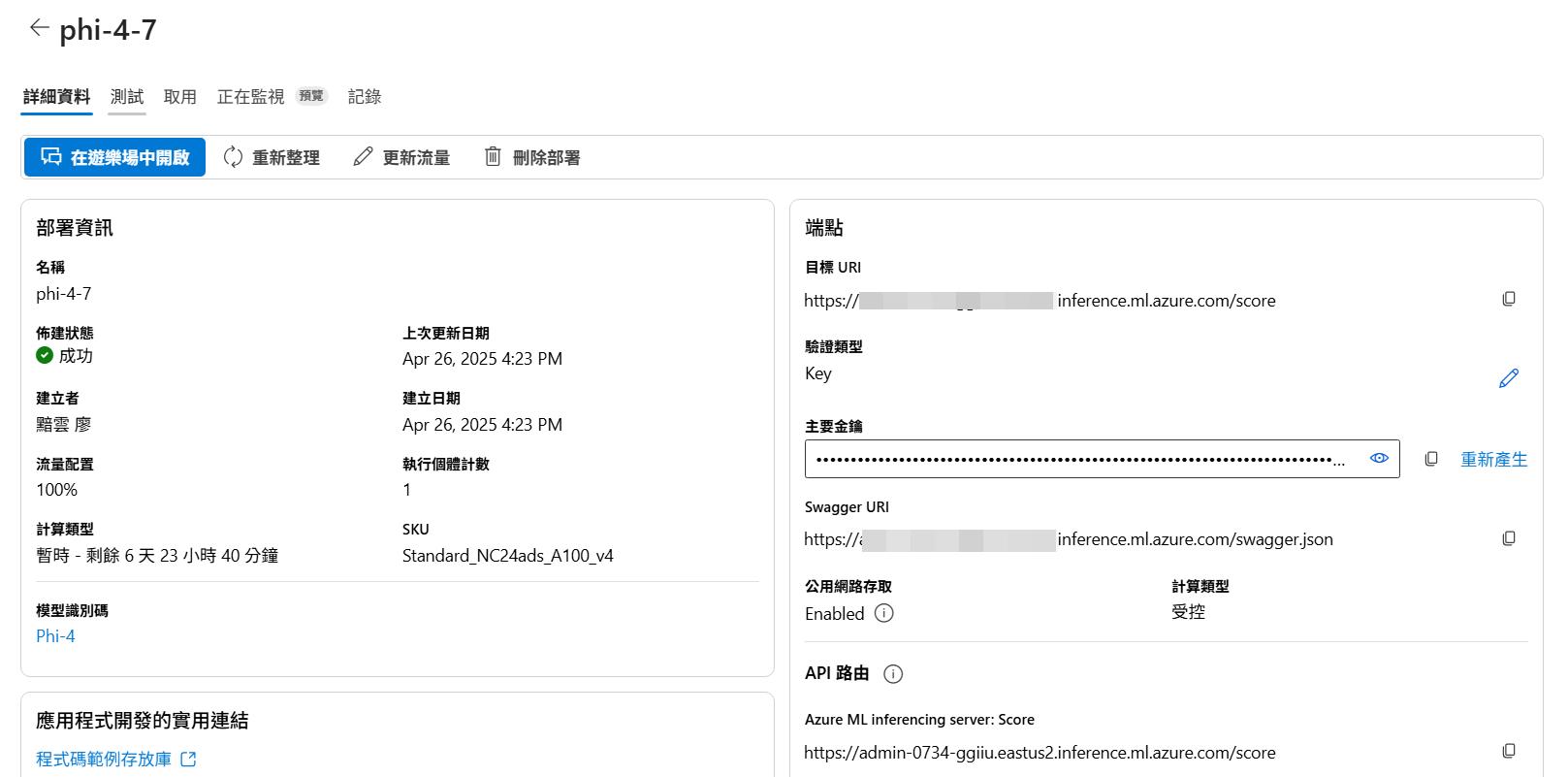
點進節點一樣可以取得節點位置跟金鑰,後面要用程式串接的時候就可以使用。
遊樂場測試
不管是哪種部署模式我們都可以透過遊樂場來測試部署好的模型,因為我們建立的是一般的聊天模型,所以選擇聊天遊樂場,如果建立的是產生圖片的模型就選擇相對應的遊樂場來測試。
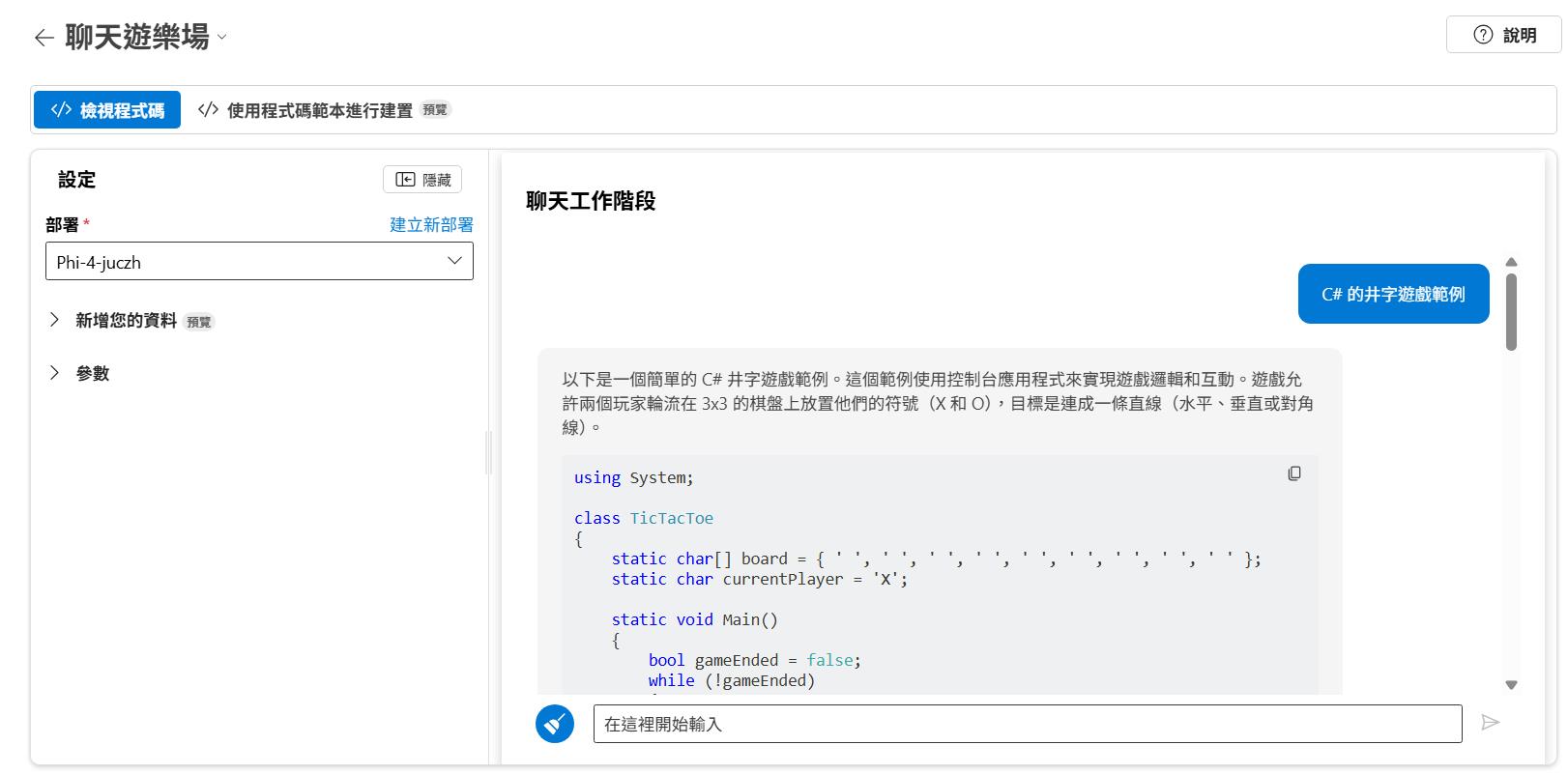
再來就看到熟悉的遊樂場可以測試了,這邊也有常見了可以新增自己的資料來做 RAG 或是設定模型的溫度等參數。
程式實做
最後就是透過程式來呼叫節點使用,如果是 Serverless 的模式,就可以用底下的程式碼來呼叫使用,底下程式碼使用的套件是微軟開發的 Azure.AI.Inference。這邊要注意的是需虛擬機器的節點記得去掉後面的 /score 才會是正確的。
using Azure.AI.Inference;
void Main()
{
var endpoint = new Uri("[Your Endpoint]");
var credential = new AzureKeyCredential("{Your Key}");
var model = "{Your Model Name}";
var client = new ChatCompletionsClient(
endpoint,
credential,
new ChatCompletionsClientOptions());
var requestOptions = new ChatCompletionsOptions()
{
Messages =
{
new ChatRequestUserMessage("C# 井字遊戲範例")
},
MaxTokens = 2048,
Temperature = 0.8f,
PresencePenalty = 0.0f,
FrequencyPenalty = 0.0f,
Model = model
};
Response<ChatCompletions> response = client.Complete(requestOptions);
System.Console.WriteLine(response.Value.Choices[0].Message.Content);
}執行程式之後就可以得到如下的回應了。
結論
現在各種 LLM 模型推陳出新,雖然可以在本機部署來測試和開發,但是就會需要有一定配置的硬體才可以跑得起來 LLM 模型,有些參數較大的模型也會需要更多的運算資源和儲存空間,如果單純要測試或是開發,透過微軟的 Azure AI Foundry 來部署,不僅快速又方便,未來更可以搭配 Azure 上面的服務來做 RAG,在開發上也可以用一致的套件來開發,程式碼也不需要做大幅度的調整,部署出來的節點支援標準的 AI 方法,包含 OpenAI 也都可以透過這樣的方式來部署跟測試,而且新的模型微軟也都很快就上架了,想測試的時候就可以上去點點選選就可以了。



