重構
物件的演進
大物件和大類別的進化過程:遺留系統的大物件(類別)是伴隨業務系統逐漸成長出現)。
筆者覺得有意思的是文中提到,客觀規律-人的大腦認識的事物是一個由簡單到複雜的過程,這是客觀規律。
內容用了開立發票類別的演進,也是筆者最常遇到一個類別的演進過程。

上述演進過程反映出,實際最常見的困境:
- 超級大類別中的方法越來越多,方法底下夾雜一堆各種條件和迴圈的結構。
- 程式變得難理解。
- 看不懂代碼和夾雜一堆程式沒有結構狀況下,交付生產下降。
如何解決這樣問題,有一種方式就是【職責驅動設計】為中心。
透過這樣方式在重構過程中,來調整程式結構,建構【高內聚、低耦合】。
職責驅動設計:當筆者在看這個內容的解讀是都是有自己的職責定義,每個類別、介面、方法、屬性,圍繞它的規則走,是高度相關的,每個類別和介面不做跟自己職責無關的事,那些無關的應交給其他擁有職責類別來完成,自己僅僅呼叫,這是職責驅動設計思想,每個類別內部包含的功能所達到高度相關程度,叫做內聚。
這邊我覺得有兩點滿重要:
- 類別職責分和不分,取決軟體程式碼的複雜度。
- 判斷功能相關:是否引起軟體變更同一個的原因。
上述的例子來切入開發票業務類別,主要職責【完成開發票作業】,但有其他部分,這時候要開始拆分出以下:
- 各種檢驗類別
- 發票業務類別
- 會計統計類別
拆分可以透過開發票類業務類別變成管理別,不在參與具體工作,而工作分配給不同的人,成為組織協調者。
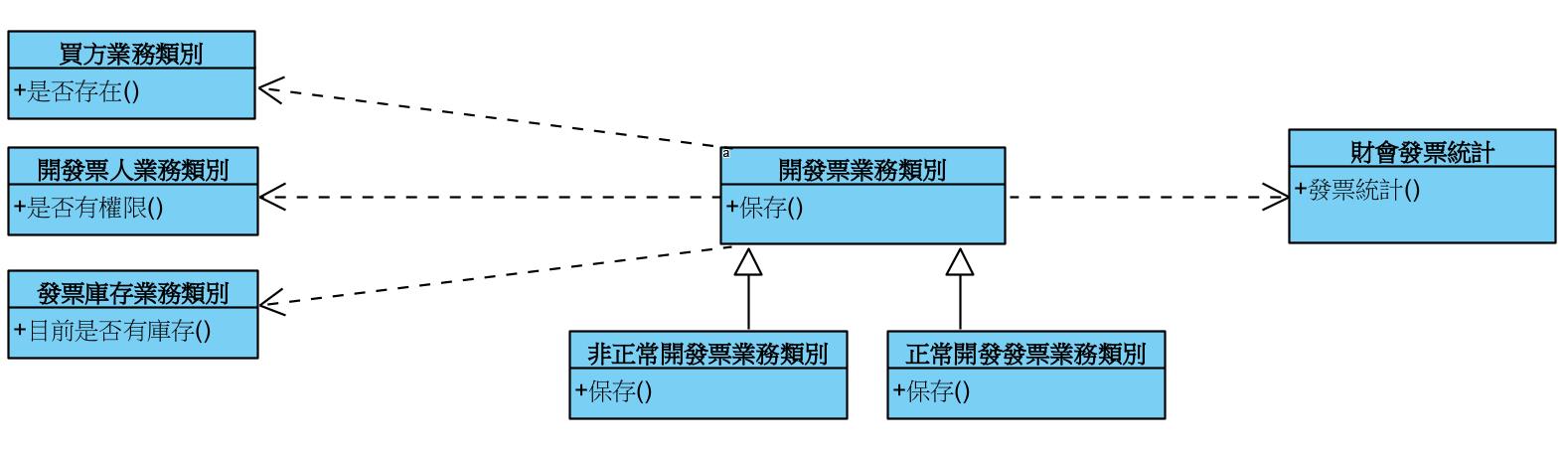
分拆大物件的手法,將原物件中方法移動到其他物件,重構手法為【抽取類別】(Extract Class)。
如何進行Extract Class?
分拆大物件或超級類別,必須要仰賴原則【職責驅動設計】,將行為和方法移動擁有該職責的類別。
原則:設計者要和真實世界保持一致。
如何把方法進行做歸類的方法,分別有:
- 分析領域模型
- 分析業務變更原因
- 尋找資訊專家
領域模型
領域模型是在【需求分析後期,設計開發初期】,完成模型分析。
- 站在使用者角度,分析業務領域相關相關事物、屬性、擁有的行為,事物與事物之間關係也要反映在軟體物件、屬性、行為、物件和物件之間關係。
- 領域模型分析是確保軟體系統設計與真實世界的對應一種保障。
- 在重構過程中繪製領域模型、按照領域模型的方法來建立物件,哪些方法分配給哪一個物件。
以發票類別為例,發票業務分配發給發票類別,與發票業務操作都是發票類別,有可能發票開立前的檢驗、檢查客戶狀態、客戶狀態、發票人權限,這些未必跟開立發票類別沒有直接關係,不是它的職責所在。
分析某個方法屬於哪個類別,採用尋找【資訊專家】。
GRASP是通用職責分配軟體模式(General Responsibility Assignment Software Patterns)的簡稱,是物件導向設計和職責分配中的九個基本原則[1]:6,最早是在克雷·拉蒙1997年的Applying UML and Patterns書中提到。
來自維基百科
關於資訊專家
筆者的解讀:是將某個方法分配給有執行這個方法的資訊專家(類別)。
採用資訊專家會得到是將上方的例子,會得到以下:
- 檢查客戶狀態,應屬於客戶資訊,分配給【客戶管理業務類別】。
- 檢查發票人權限,應屬於使用者權限資訊,分配給【使用者權限業務類別】。
- 檢查發票庫存,應屬於【發票庫存管理業務類別】。
好處:採用資訊專家可提高系統維護性,降低需求變更的影響。
但是採用以上職責分析設計有大有小,還是會有模糊不清帳況出現,這時候就要以SRP來做切入點改善。
單一職責原則與物件分拆
在人對職責理解是【職責是完成某方面的一件事情】,但採用SRP就是【每個類應該只有一個職責,對外只能提供一種功能,而引起類變化的原因應該只有一個,一個職責就是軟體變化的一個原因】。
單一職責原則的核心思想就是:系統中的每一個物件都應該只有一個單獨的職責,而所有物件所關注的就是自身職責的完成。
其實單一職責原則的意思就是開發人員經常說的【高內聚、低耦合】。
關於內聚、耦合
- 內聚:把相關性質用到程式和資料聚在一起,某一個模組中(method或是Class),模組單一性強,一個模組可以單獨個體執行。
- 耦合:模組之間的互相依賴,在改動過程中互相影響。
關於高內聚、低耦合
- 高內聚:就是指一個軟體由相關性很強的程式組成,只負責一項事情,就是常說的單一責任原則,一個好的內聚模組應恰好做一件事情(白話:一個模組內只完成一件工作)。
- 低耦合:就是物件相依關係越低越好。
關於內聚的補充:
- 內聚力:是在一個模組內完成一件工作的度量指標。
- 高內聚力:一個模組內只完成一件工作。
- 內聚力高:意味著模組更容易獨立運作、更容易重複使用(例如:一個類別只負責一件事)。
- 低內聚力:在一個模組內完成多份工作。
- 內聚力低:意味著這個模組會造成難以維護/測試/重用/理解(例如:一個類別或甚至一個方法程式碼五千多行)。
總結:實務上,我們要盡力的設計出高內聚力的程式碼(SRP原則會提高內聚力)。
接者回到拆解過程。
上述拆解過程的時候,會碰到下列狀況:
- 正常開發票和非正常開發票,許多地方業務流程是相同的,也有業務是不相同的狀況。
- 需求變更的狀況,正常發票變更,不代表非正常發票會出現變更。
當遇到1、2狀況下,按照SRP原則是要拆分的。
接者延伸出另一個問題,在開發正常開發票業務類別和非正常開發票業務類別造成重複程式出現,這時候叫要用OOAD的繼承方式來解決問題,那怎麼解決,步驟如下:
- 劃分業務相同與業務不同,落實相同程式與不同程式,採用提取方法,將不同代碼保留在原函數裡,將相同代碼抽離出新的函數。
- 進行拆分,將原有發票類別,拆成抽象開發票類別、正常開票業務類別、非正常開發票業務類別。
- 抽象開發票業務類別是爸爸、正常開票業務類別、非正常開發票業務類別是子類。
- 相同程式放在爸爸,不同程式放在正常開票業務類別、非正常開發票業務類別。
上述過程中叫做抽取父類,如下:
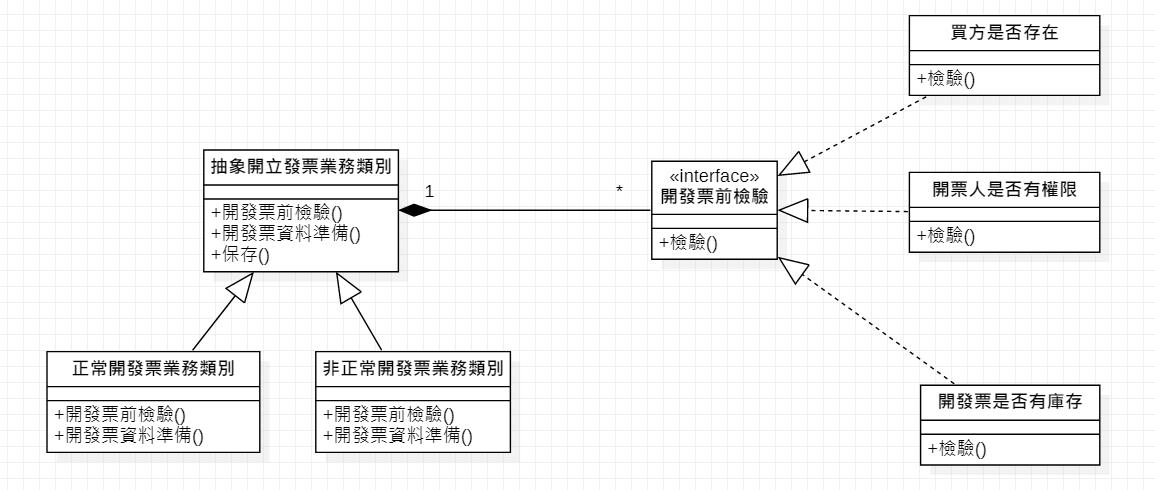
在上述過程中,在遺留系統能做到這樣很難立即判斷做出正確的分析,會遇到原有類別不合理,也有可能業務類別會增加,所以先做好類別的歸類在慢慢地逐步矯正到位,讓自己接手的系統好調整,甚至陸續加入測試程式。
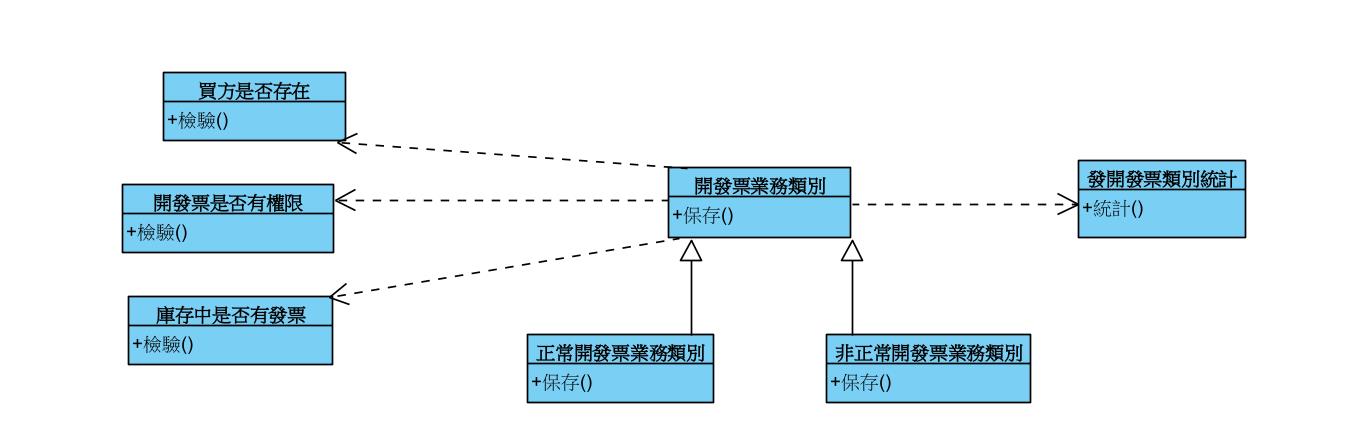
回到最早類別,如下:
接者我們開始拆類別,進行類別拆解,大物件拆解狀況下,形成如下:
接者拆完過程中,開始回歸領域模型將方法回歸對應的類別,如下:
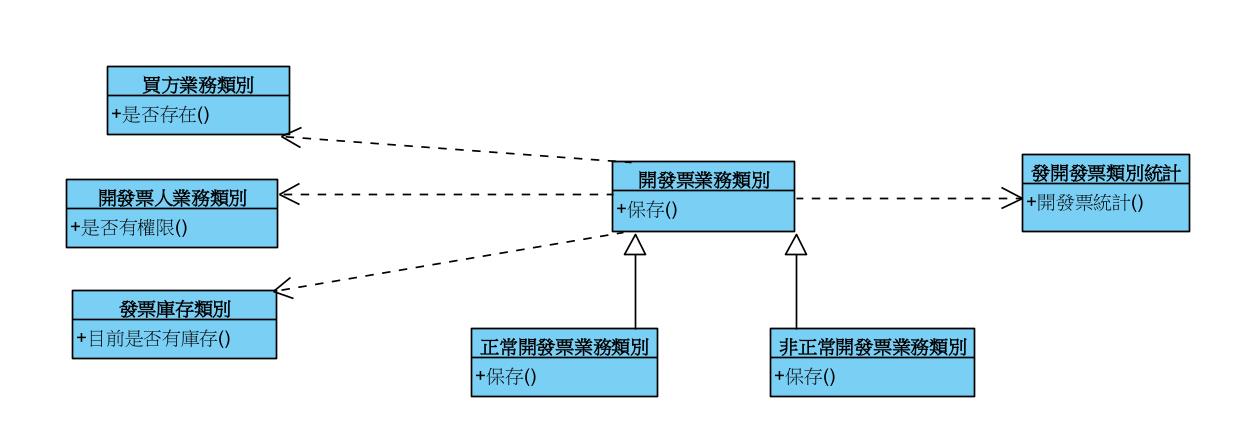
以上大概是介紹整個拆解物件的過程。
參考資料
亂談軟體設計(1):Cohesion and Coupling
元哥的筆記