摘要:同樣都是二進位序列化後壓縮為什麼壓縮後資料大小不一樣呢?
之前在寫 二進位序列化+壓縮 發現了一個問題。
下面的Compress_0、Compress_1 function同樣都是序列化後壓縮,
但是為什麼Compress_0壓縮不如Compress_1,怎麼不是一樣大呢???
讓我們來探討一下吧!
要序列化的資料結構
[Serializable]
class date
{
public DateTime a1;
public DateTime a2;
public DateTime a3;
public DateTime a4;
public DateTime a5;
public DateTime a6;
public date()
{
a1 = a2 = a3 = a4 = a5 = a6 = DateTime.Now;
}
}
第一種壓縮方式(Compress_0 function),邊序列化邊壓縮
static byte[] Compress_0(date obj)
{
MemoryStream zippedStream = new MemoryStream();
using (GZipStream gzip = new GZipStream(zippedStream, CompressionMode.Compress))
{
BinaryFormatter bfmt = new BinaryFormatter();
bfmt.Serialize(gzip, obj);
gzip.Flush();
}
byte[] zippedBuf = zippedStream.ToArray();
return zippedBuf;
}
第二種壓縮方式(Compress_1 function),將物件完全序列化後才一次全部壓縮
static byte[] Compress_1(date obj)
{
//先將物件完全序列化
BinaryFormatter ser = new BinaryFormatter();
MemoryStream stream = new MemoryStream();
stream.Position = 0;
ser.Serialize(stream, obj);
//將序列化完後的全部資料,進行壓縮
byte[] serbyte = stream.ToArray();
MemoryStream ms = new MemoryStream();
ms.Position = 0;
using (GZipStream zipStream = new GZipStream(ms, CompressionMode.Compress))
{
zipStream.Write(serbyte, 0, serbyte.Length);
}
return ms.ToArray();
}
接下來讓我們透過WIN FROM執行上面兩個方法
private void button1_Click(object sender, EventArgs e)
{
date myDate = new date(); //要序列化的物件
var c0 = Compress_0(myDate);
var c1 = Compress_1(myDate);
label1.Text = c0.Length.ToString();
label2.Text = c1.Length.ToString();
}
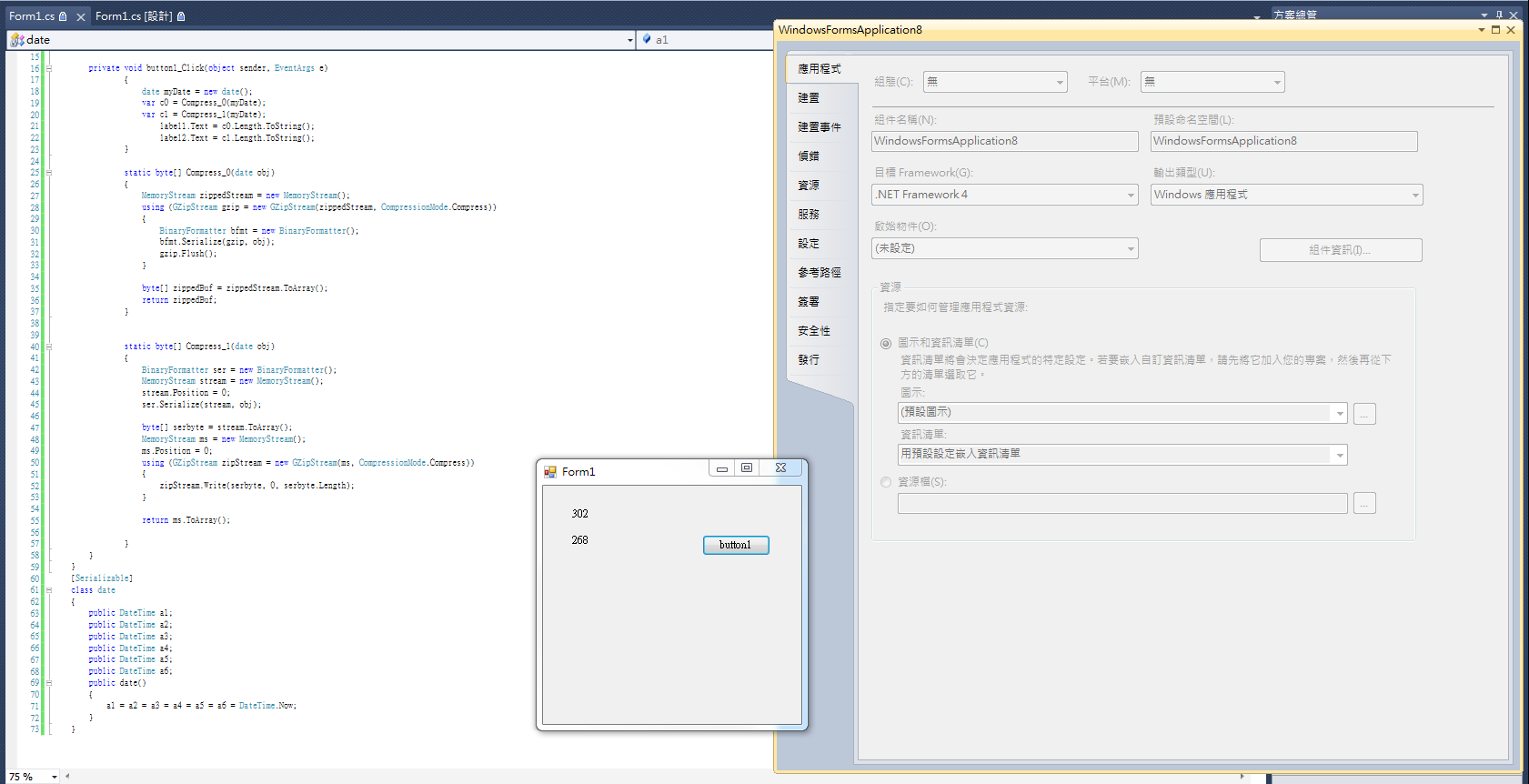
執行結果如下(label1.Text=302、label2.Text =268,環境執行WIN7系統.net 4.0),WIN FORM去執行在XP x86和WIN7 X64及皆用.net 4.0跑但是label1.Text一直都沒有等於label2.Text
答案:經過google一番搜尋,發現有相關的解答。
static byte[] Compress_0(date obj)
{
byte[] zippedBuf;
MemoryStream zippedStream = new MemoryStream();
using (GZipStream gzip = new GZipStream(zippedStream, CompressionMode.Compress))
{
using (var bstream = new BufferedStream(gzip, 65536))//設定Buffere大小64k
{
BinaryFormatter bfmt = new BinaryFormatter(); //將序列化加一個64k BufferedStream做為緩衝區
bfmt.Serialize(bstream, obj);
}
zippedBuf = zippedStream.ToArray();
}
return zippedBuf;
}
額外補充:
在取出MemoryStream.ToArray()前必須先關閉相關的Stream(如GZipStream或BufferedStream),否則在反序列化時,會有SerializationException的錯誤。
感恩下面的作者
相關參考:http://stackoverflow.com/questions/12091404/using-gzipstream-with-one-or-two-memory-streams-makes-a-big-difference
相關參考:http://stackoverflow.com/questions/12088623/how-to-serialize-object-compress-it-and-then-decompress-deserialize-without
相關參考:http://stackoverflow.com/questions/12088623/how-to-serialize-object-compress-it-and-then-decompress-deserialize-without