我們之前有提過微軟為了資料分析的發展在SQL 2016 正式加入併購進來的 Revolution Analytics解決方案,在本文中將以預防性的維修示範如何使用 R語言來進行資料分析。額外提醒一下External scripts與LaunchPad service是 SQL Server在做 ML資料分析的必要條件。

首先要介紹預防性維修的情境,讓大家能知道為何而戰?事關飛航安全以及資源調度,某個飛機公司需要了解飛機上關鍵的零組件的使用狀態,以及欲更換零組件要事先運送到飛機的所在位置,來爭取時效,實現最小的損失與更高的營收。因此他們想要了解三個問題,分別是如何透過廻歸演算法,預測零組件的可使用時間、損壞時間;如何透過二元分類演算法預測零組件是否會在某個時間點內故障,例如在台北-洛杉機這14小時的航程中;如何透過多元分類演算法預測零組件是否會在不同的時間內故障。細節可以參考官網的說明,以及Github上的範例資源檔 在上圖中,從網頁的View Code按鈕也能引導你到Github網站中
在上圖中,從網頁的View Code按鈕也能引導你到Github網站中
 在這個Repository中提供了DSVM(Data Science Virtual Machine)、範例資料集、其他相關的資源。例如在 Data 目錄中包含了四個檔案
在這個Repository中提供了DSVM(Data Science Virtual Machine)、範例資料集、其他相關的資源。例如在 Data 目錄中包含了四個檔案
.\Data\PM_train.csv 飛機引擎狀態的原始資料
.\Data\PM_test.csv 飛機引擎正常狀態(故障前)的原始資料
.\Data\PM_truth.csv 人工標記的飛機引擎狀態(監督式學習所需的正確數值)
.\Data\PM_Score.csv 將測試資料進行模型訓練所得到的分數
在開始之前你還需要下載 SSMS與R Studio,這個之前已經介紹過了,若你想要一個全新而且還預載資料科學家的工作環境,你可以選擇DSVM(下方藍色的按鈕)。以及plyr 與 zoo 的R語言 Package函式庫
 下圖是DSVM的畫面
下圖是DSVM的畫面
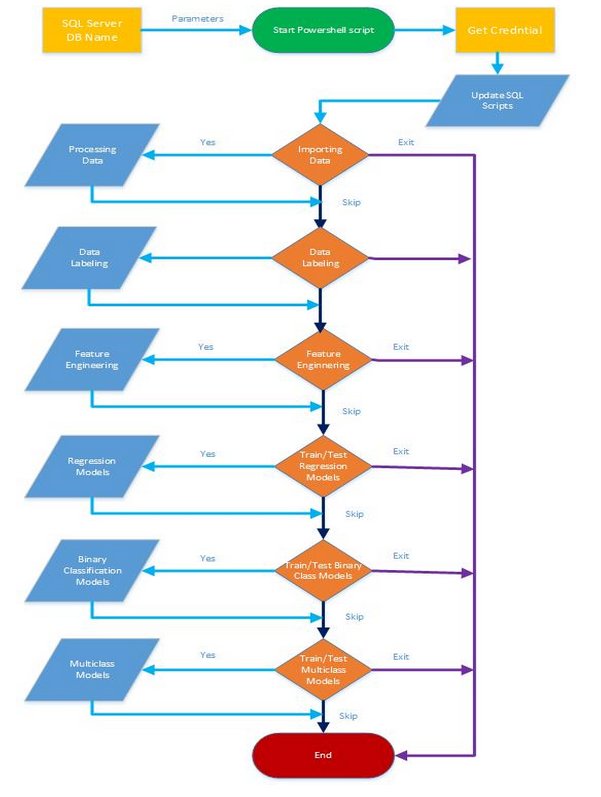
 本資料分析的流程
本資料分析的流程
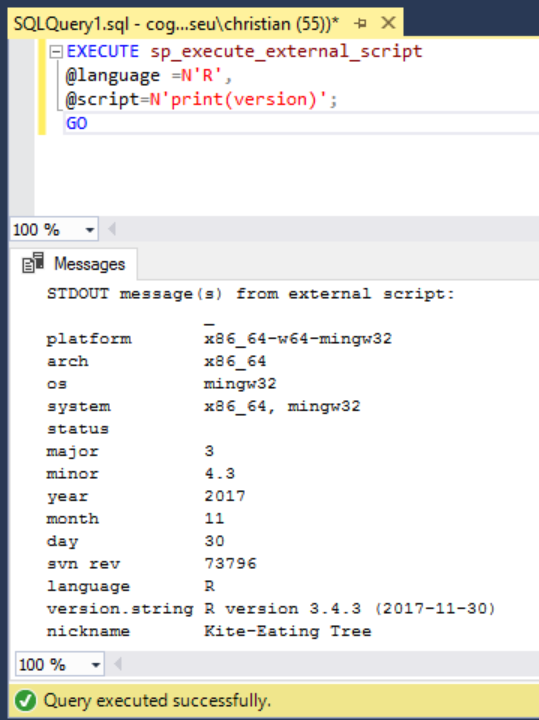
 1、從 Github中把整份相關檔案clone到本機,並且確認一下 R Service已經 Ready了
1、從 Github中把整份相關檔案clone到本機,並且確認一下 R Service已經 Ready了
 2、為了讓 SQL Server實現 In Database Analysis,需要透過 PowerShell來設定SQL Server在 Machine Learning的權限。先要開啟 Windows PowerShell ISE視窗程式,來執行PredictiveMaintenanceSetup.psl
2、為了讓 SQL Server實現 In Database Analysis,需要透過 PowerShell來設定SQL Server在 Machine Learning的權限。先要開啟 Windows PowerShell ISE視窗程式,來執行PredictiveMaintenanceSetup.psl
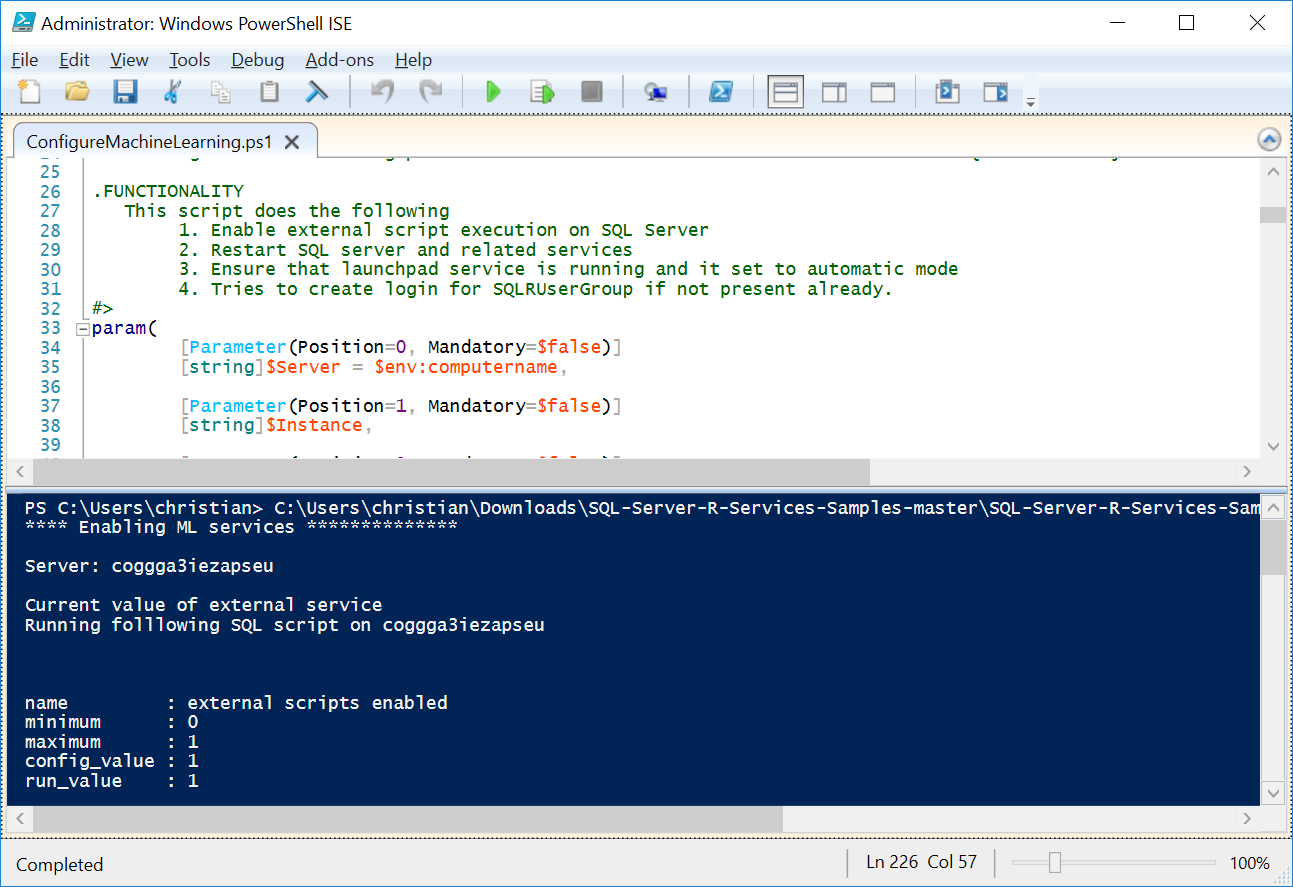 過程中,SQL Server會被更改一些系統設定,包含(以下的指令)能連上網際網路下載 R Package擴充函式庫,並且會需要你 Stop/ Restar下上服務。若你的公司不允許讓 Production資料庫,就需要再找一台來擔任 ML專用伺服器,還是可以做資料分析。如果你只需要獨立的安裝R 請參考官網的說明
過程中,SQL Server會被更改一些系統設定,包含(以下的指令)能連上網際網路下載 R Package擴充函式庫,並且會需要你 Stop/ Restar下上服務。若你的公司不允許讓 Production資料庫,就需要再找一台來擔任 ML專用伺服器,還是可以做資料分析。如果你只需要獨立的安裝R 請參考官網的說明
 由於安全性的考量 SQL Server 預設是不能連外網的,但是這個跟 R有超過 7000個 CRAN 擴充函式庫的優勢,卻是背道而馳,需要規劃清楚!
由於安全性的考量 SQL Server 預設是不能連外網的,但是這個跟 R有超過 7000個 CRAN 擴充函式庫的優勢,卻是背道而馳,需要規劃清楚!
EXEC sp_configure 'external scripts enabled', 1;
RECONFIGURE WITH OVERRIDE
以上是截取至 PowerShell中,你若不習慣也可以把相關的指令,帶到 SSMS來執行,或是透過客製化的 SSRS Reports 來查詢狀況並設定 R服務
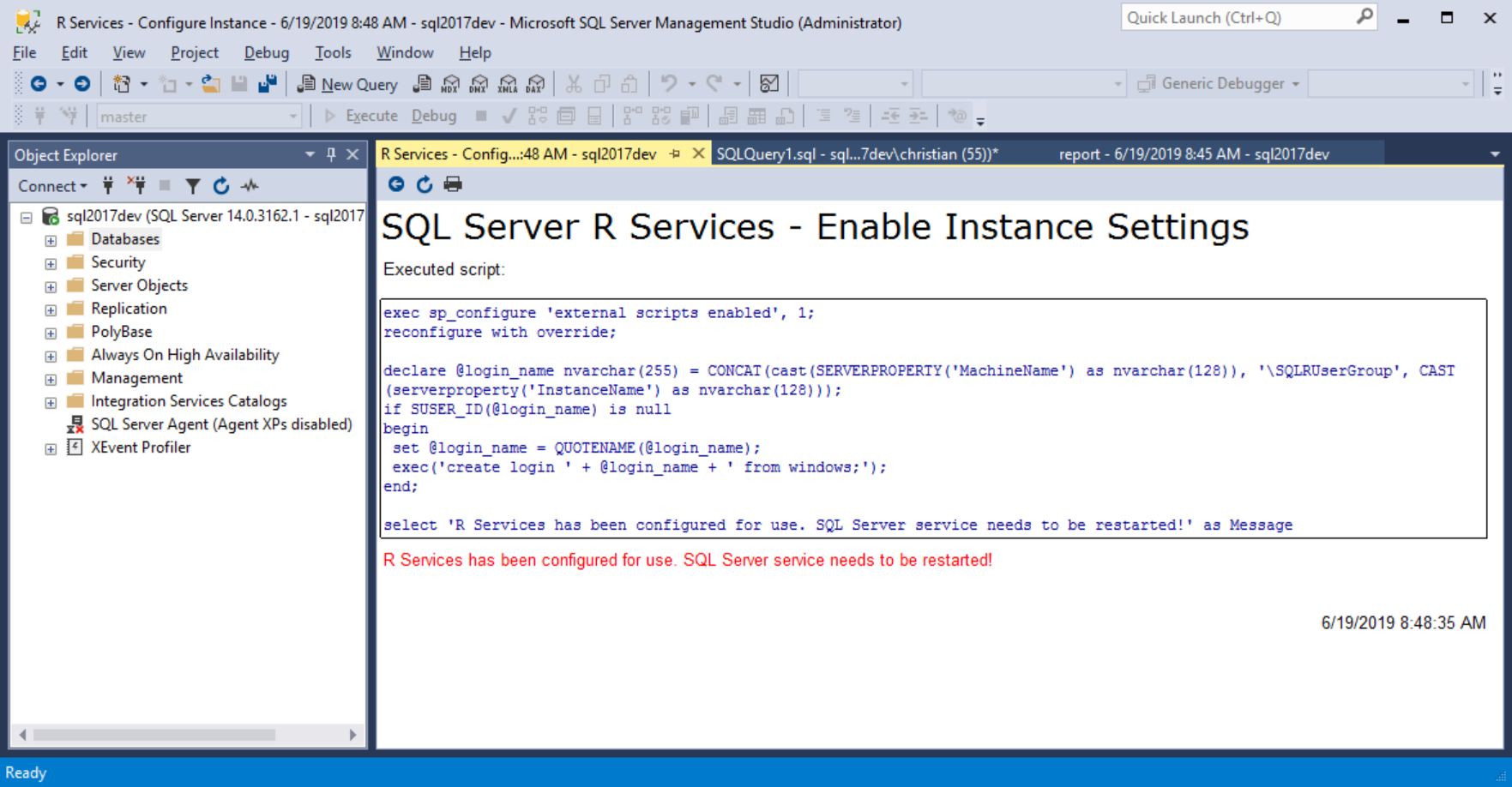 檢視 SQL Lauchpad Service的狀況
檢視 SQL Lauchpad Service的狀況
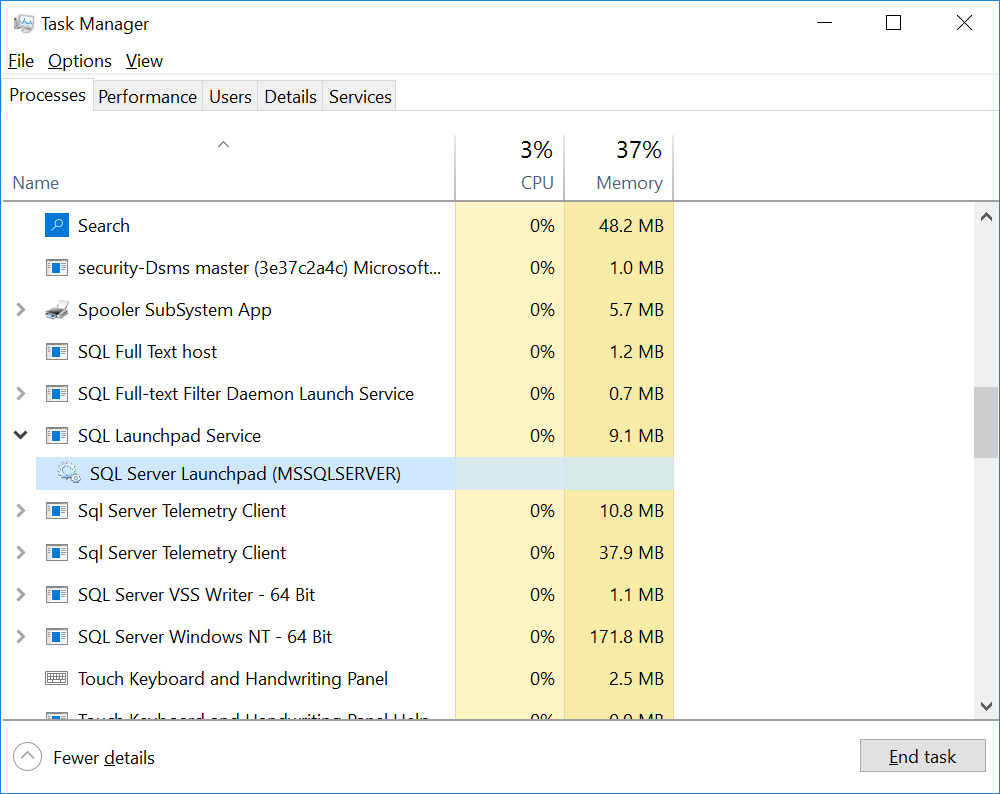 然後SQL Server Launchpad 己經能透過 Vobose驗證,待命來執行 Machine Learning作業。補充一下 Revolution R與 Open R的差別是多執行緒與單一執行緒,而 Launchpad Service就是在負責多執行緒的管理與資料隔離的重要服務。
然後SQL Server Launchpad 己經能透過 Vobose驗證,待命來執行 Machine Learning作業。補充一下 Revolution R與 Open R的差別是多執行緒與單一執行緒,而 Launchpad Service就是在負責多執行緒的管理與資料隔離的重要服務。
接著再執行 PredictiveMaintenanceSetup.psl,把資料庫的 Schema建立好
 剛才提到的 plyr與zoo R package也會幫你下載好
剛才提到的 plyr與zoo R package也會幫你下載好
3、切換至SQLR目錄中,開始應用 SQL2016來分析,以下是分解動作
Step 1: Data Preparation
Step 2: Feature Engineering
Step 3A: Train/test Regression Models
Step 3B: Train/test Binary Classification Models
Step 3C: Train/test Multi-class Classification Models
Step 4: Production Scoring
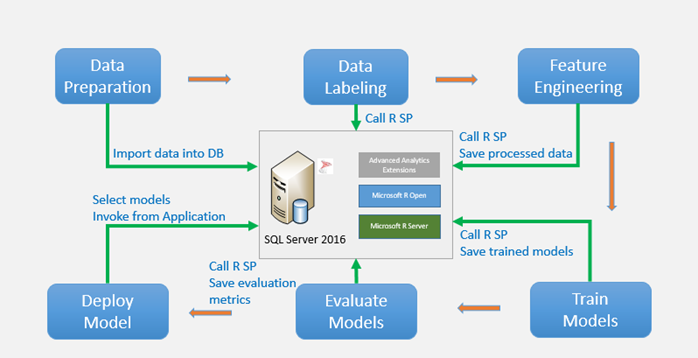 上圖是各個步驟在 SQL Server 中的 Data flow
上圖是各個步驟在 SQL Server 中的 Data flow
在Step1 Data prepare階段,會將 4個原始資料,透過 bcp匯入SQL Server,然後再進行資料分析並產生 6個 Table。PM_train表中是訓練資料、PM_test表中是測試資料、PM_truth表中是人工標記的正確資料、PM_models表是儲存訓練好的模型、Labeled_train_data表是訓練資料再加上標記的資訊、Labeled_test_data表是測試資料再加上標記的資訊
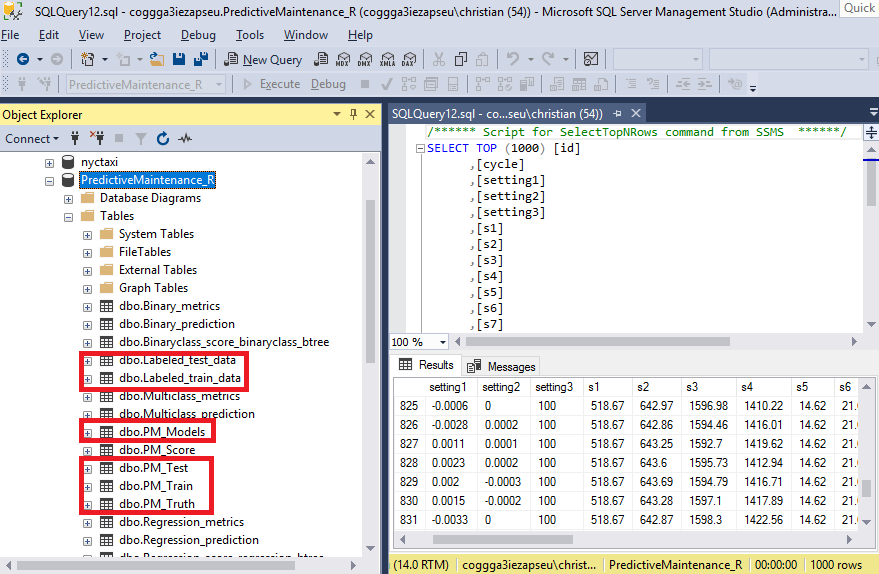 在Step2 Feature engineering階段,會應用 feature_engineering.sp這支預存程式,透過 plyr與zoo函式庫將資料進行彙總與運算(像是平均值、標準偏差),以及資料的標準化(Normalization),分別會產生4個Table,train_Features、test_Features、train_Features_Normalized、test_Features_Normalized
在Step2 Feature engineering階段,會應用 feature_engineering.sp這支預存程式,透過 plyr與zoo函式庫將資料進行彙總與運算(像是平均值、標準偏差),以及資料的標準化(Normalization),分別會產生4個Table,train_Features、test_Features、train_Features_Normalized、test_Features_Normalized
進行廻歸分析,將會在 Table中新增一個 RUL欄位,並且填入還能用幾次(Cycle)
進行二元分類分析,將會在 Table中新增一個 lable1欄位,並且填入是否會在W1 時間內發生故障(正常的值為0;故障的值為1)
進行多元分類分析,將會在 Table中新增一個 lable2欄位,並且填入是否會在不同的時間內發生故障,例如0代表W0(15天);1代表W1(30天);2代表W2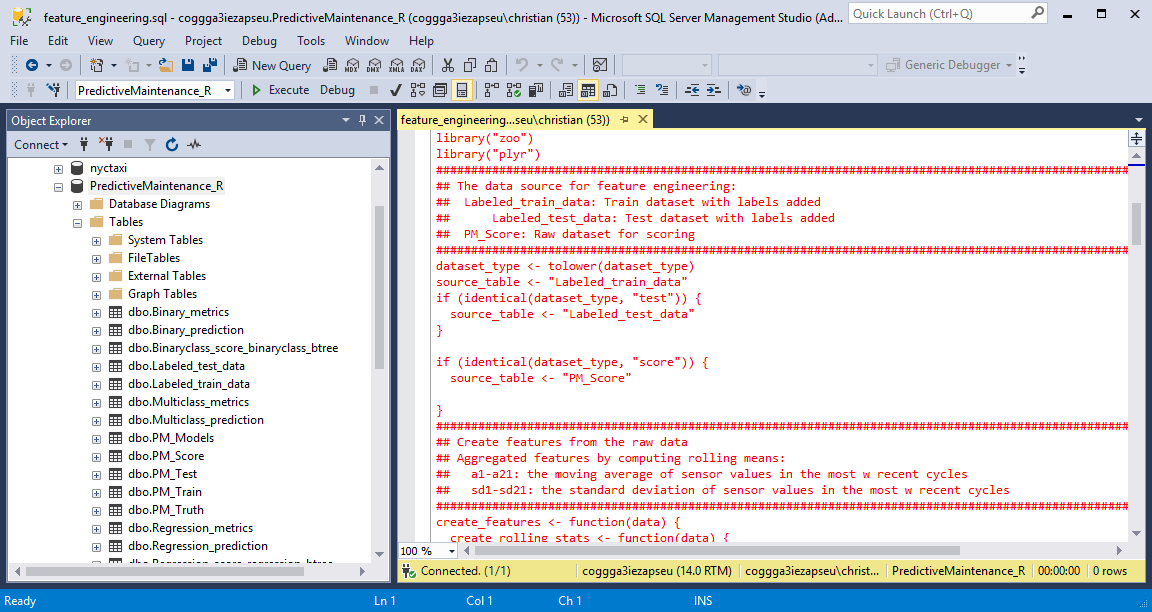 在Step3 Train and Evaluate regression/binary classification/multi-classification models 階段中,迴歸分析將會應用 train_regression_model.sql與 test_regression_model.sql,先訓練模型再用測試資料集產生驗證的分數。在模型中將會應用Decision Forest Regression/Boosted Decision Tree Regression/Poisson Regression/Neural Network Regression來取得較好的結果;同理在二元分類分析中,也是應用 Two-Class Logistic Regression/Two-Class Boosted Decision Tree/Two-Class Decision Forest/Two-Class Neural Network 來取得較好的結果;同理在多元分類分析中,也是應用 Multi-class Decision Forest/Multi-class Neural Network 來取得較好的結果
在Step3 Train and Evaluate regression/binary classification/multi-classification models 階段中,迴歸分析將會應用 train_regression_model.sql與 test_regression_model.sql,先訓練模型再用測試資料集產生驗證的分數。在模型中將會應用Decision Forest Regression/Boosted Decision Tree Regression/Poisson Regression/Neural Network Regression來取得較好的結果;同理在二元分類分析中,也是應用 Two-Class Logistic Regression/Two-Class Boosted Decision Tree/Two-Class Decision Forest/Two-Class Neural Network 來取得較好的結果;同理在多元分類分析中,也是應用 Multi-class Decision Forest/Multi-class Neural Network 來取得較好的結果
 接著,在Step4 Production scoring 階段中,首先是應用 create_table_score.sql 來上傳資料至 PM_Score Table中,再執行 feature_engineering_scoring.sql 得到新的 feature與 Normalize標準化的結果,就能依據執行score_regression_model.sql、score_binaryclass_model.sql、score_multiclass_model.sql 來得到驗證的分數
接著,在Step4 Production scoring 階段中,首先是應用 create_table_score.sql 來上傳資料至 PM_Score Table中,再執行 feature_engineering_scoring.sql 得到新的 feature與 Normalize標準化的結果,就能依據執行score_regression_model.sql、score_binaryclass_model.sql、score_multiclass_model.sql 來得到驗證的分數
李秉錡 Christian Lee
Once worked at Microsoft Taiwan