摘要:[ASP.NET] 好用的HTML Paser - Html Agility Pack
之前朋友希望能幫他抓每日的一些股價,
就發現了這個好用的HTML Paser,主要是用XPath來抓取要的資料,
(如果不清楚XPath的,點連結可以參考)
它可以用XPath擷取網頁上的任何資料,就不用再用分割字串割來割去的,
網址: http://htmlagilitypack.codeplex.com/
下載完成解壓縮後可以把其中的HtmlAgilityPack.dll,放到所需要的專案中(bin資料夾),

雖然到他的下載區還有一個 HAP Explorer 的XPath解析器,讓你可以看到你想要的XPath,而不用自己在那邊慢慢算,
可是我覺得不是很好用,可能我用的不習慣,現在有很多XPath的解析器,
我比較習慣使用Firefox(FF)的XPath附加元件,
請用FF到 https://addons.mozilla.org/zh-TW/firefox/ 搜尋XPath,就可以找到一堆,
我是用https://addons.mozilla.org/zh-TW/firefox/addon/1192/ 這套,
直接示範如何使用比較快,找了小小郭的新聞來示範一下,
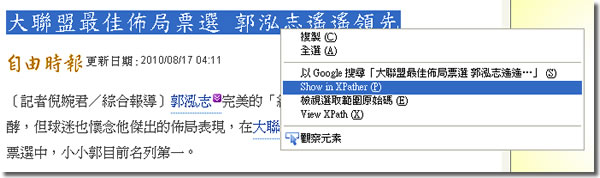
選你要的部分,按下滑鼠右鍵,選「Show In XPather」,就可以看到解析結果,
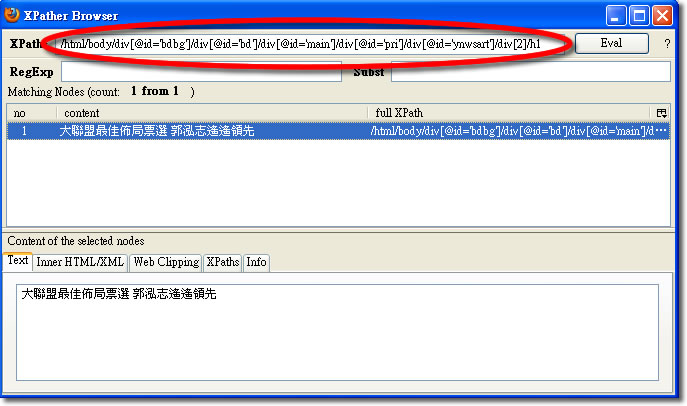
都準備好後,就可以來試試看Html Agility Pack ,
如果是VB請記得加上Imports HtmlAgilityPack,C#的話就是加上using HtmlAgilityPack;
拿剛剛小郭的新聞標題來示範,
01  Friend Sub HTMLPrint()
Friend Sub HTMLPrint()
02 ' 下載你要的網頁資料,這裡是用小小郭的新聞
' 下載你要的網頁資料,這裡是用小小郭的新聞
03 Dim client As New WebClient()
04 Dim ms As New MemoryStream(client.DownloadData("http://tw.news.yahoo.com/article/url/d/a/100817/78/2b8i6.html"))
05
06 ' 使用預設編碼讀入 HTML
07 Dim HtmlPage As New HtmlDocument()
08 '選擇編碼
09 HtmlPage.Load(ms, Encoding.UTF8)
10
11 Dim HtmlText As New HtmlDocument()
12
13 '帶入XPath
14 HtmlText.LoadHtml(HtmlPage.DocumentNode.SelectSingleNode("/html/body/div[@id='bdbg']/div[@id='bd']/div[@id='main']/div[@id='pri']/div[@id='ynwsart']/div[2]").InnerHtml)
15
16 Dim Str As String() = HtmlText.DocumentNode.SelectSingleNode("./h1").InnerText.Trim().Split(ControlChars.Lf)
17
18 My.Response.Write(Str(0).Trim())
19
20 HtmlPage = Nothing
21 HtmlText = Nothing
22 client = Nothing
23 ms.Close()
24 End Sub
End Sub
25
26 Protected Sub Page_Load(ByVal sender As Object, ByVal e As System.EventArgs) Handles Me.Load
Protected Sub Page_Load(ByVal sender As Object, ByVal e As System.EventArgs) Handles Me.Load
27 HTMLPrint()
28 End Sub
End Sub
Friend Sub HTMLPrint()  Friend Sub
Friend Sub02
' 下載你要的網頁資料,這裡是用小小郭的新聞 03
Dim client As New WebClient() 04
Dim ms As New MemoryStream(client.DownloadData("http://tw.news.yahoo.com/article/url/d/a/100817/78/2b8i6.html")) 05
06
' 使用預設編碼讀入 HTML 07
Dim HtmlPage As New HtmlDocument() 08
'選擇編碼 09
HtmlPage.Load(ms, Encoding.UTF8) 10
11
Dim HtmlText As New HtmlDocument() 12
13
'帶入XPath 14
HtmlText.LoadHtml(HtmlPage.DocumentNode.SelectSingleNode("/html/body/div[@id='bdbg']/div[@id='bd']/div[@id='main']/div[@id='pri']/div[@id='ynwsart']/div[2]").InnerHtml) 15
16
Dim Str As String() = HtmlText.DocumentNode.SelectSingleNode("./h1").InnerText.Trim().Split(ControlChars.Lf) 17
18
My.Response.Write(Str(0).Trim()) 19
20
HtmlPage = Nothing 21
HtmlText = Nothing 22
client = Nothing 23
ms.Close() 24
End Sub 25
26
Protected Sub Page_Load(ByVal sender As Object, ByVal e As System.EventArgs) Handles Me.Load  Protected
Protected27
HTMLPrint() 28
End Sub

這樣就可以秀出我們要的標題,還不錯用
END ...