什麼是「Harr-like feature」?
「Harr-like」是拿來做什麼?
「Harr-like」的好處?
「Harr classifier」?
實作小技巧
題外話:當初想說要好好的寫blog結果快1年沒更新了…
後來發現這blog除了學弟妹以外還是有人在看的@~@
不過寫了這麼久都還沒講解到我的研究究主題這事也是頗op...
基於最近在做template matching有用到Harr-like feature
於是有了這篇文章
什麼是「Harr-like feature」?
Harr-like feature(為了方便後面用Harr-like表示) 就是一些像下圖所呈現的方塊

方塊中由黑色及白色區塊所組成
其中並不限定黑色或白色區塊的數量
如下圖也算是Harr-like

「Harr-like」是拿來做什麼?
基本上Harr-like算是一種特徵值的提取方式
計算方法如下圖
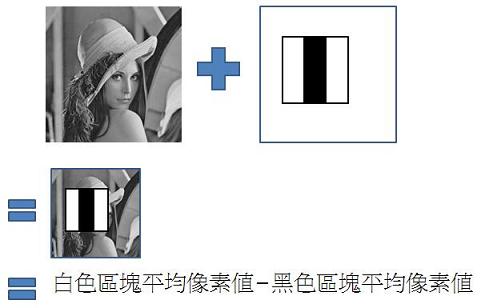
就是求出輸入影像中白色區塊及黑色區塊的差
「Harr-like」的好處?
Harr-like的好處有如下幾點
-
如同上面所說Harr-like得到的特徵值就是黑色區塊及白色區塊的差值
又因為特徵值是差值(可以想成是變化量)
所以Harr-like特徵具有一定程度的光源不變性
(特徵值不會因為同一張影像在不同光源下而有不同的特徵值或是特徵值的偏量較小) -
不同的Harr-like可以當成不同的特徵

如上兩個Harr-like所擷取的特徵是不一樣的
事實上左邊可以當成是兩個區塊的的水平變化
而右邊可以當成是兩個區塊的垂直變化
事實上根據Harr-like的不同得到的特徵也可以分為不同的種類
如邊緣特徵

線特徵
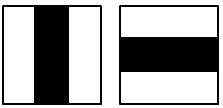
中心特徵

當然也可以組成更複雜的特徵如

而這些複雜的特徵可以當成是一種形狀特徵 -
Harr-like是利用區塊的平均值做計算
因此可以利用積分影像的方式來加速
「Harr classifier」?
一個Harr-like可以得到一個特徵值
事實上我們可以利用這個特徵值得到一個簡單的答案
如果 特徵值 大 => 具有該Harr-like所要描述的事物
相反的 特徵值 小 => 不具有該Harr-like所要描述的事物
如果判斷大小最簡單的方式還是用一個閥值
上述的事情用數學式表達如下
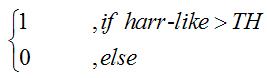
用1來表示具有要描述的事物
用0來表示不具有要描述的事物
因此一個Harr-like利用閥值區分為二
當成是一個簡單的二分類器
而Harr classifier就是利用adaboost 來訓練出多個 Harr-like弱分類器所組成的強分類器
其中每個Harr-like弱分類器使用的閥值是可以經由計算得知
概念大概就是這樣
關於Harr classifier詳細可以參考這裡
當然除了可以用adaboost方式來訓練外
如bagging的方式同樣可以訓練
只是得到的東西就不叫Harr classifier而已
實作小技巧
-
加速數值的提取
如果同一個Harr-like會在同一張影像重複提取多次特徵只是參考點不同如
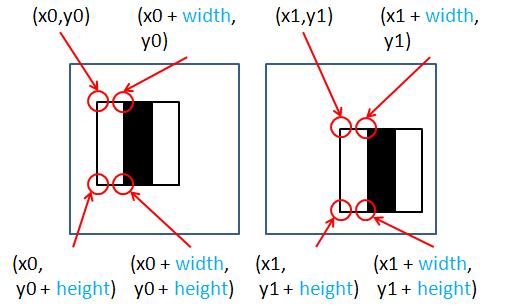
可以發現出了參考點(x,y)的不同
其餘的都是相同的
因此我們可以轉換一下型式
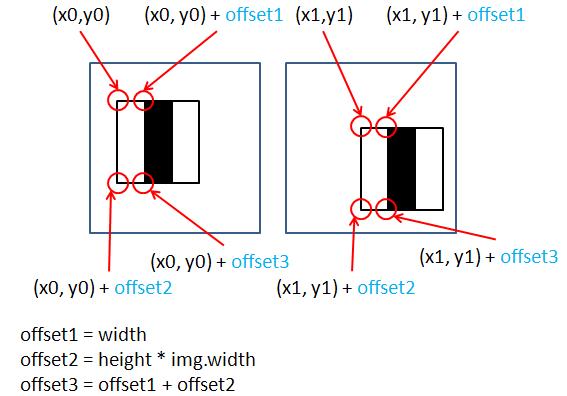
這邊有幾點提醒一下-
影像中的像素值通常被存在一個一維的陣列中
排序的方式如

- 通常要讀取位置(x,y)的程式為 img[y * width + x]
利用原本的方式要讀取4個點
我們需要計算img[y * width + x]
img[y * width + (x + width)]
img[(y + height) * width + x]
img[(y + height) * width + (x + width)]也就是有4次的乘法及8次的加法
如果改用偏移量的方式來計算
img[y * width + x]
img[y * width + x + offset1]
img[y * width + x + offset2]
img[y * width + x + offset3]實際上y * width + x只需計算一次
index = y * width + x
img[index]
img[index + offset1]
img[index + offset2]
img[index + offset3]因此只剩1次的乘法及4次的加法
當然offset1~3同樣需要經過計算
但如果同個offset被使用多次
則可以省少許多的計算時間 -
影像中的像素值通常被存在一個一維的陣列中
-
平均值計算的形式轉變
假設wSum和bSsum為白色及黑色區塊的總和
wP和bP為白色及黑色區塊的pixel數
則平均值的計算為
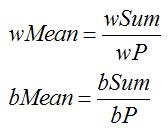
我們可以將wMean及bMean同乘bP * wP得到
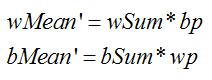
而wMean : bMean = wMean' : bMean'
這樣就能將除法運算改為乘法運算
而
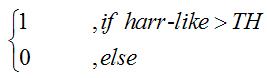
則可以改為
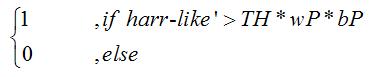
最後Harr-like是個簡單又好用的方法
當然我相信除了Harr classifier以外
Harr-like還有其它許多能發揮的地方
例如:如何在template matching中該如何像Harr classifier中選取有效的特徵
畢竟template matching中是沒有正負樣本可以拿來訓練的
而我的方式就是基於

可以表示一個形狀的特徵
以此為基礎去做延伸
此部份就先留給大家去研究
等有機會再把這部份做為文章寫出來吧...
新手發文如有錯誤,煩請指正!