模擬器程式優化心得
現在電腦效能不知道強以前多少倍,以模擬早期8bit或是16bit遊戲機種來說,即使是C#也完全可以勝任沒問題(多虧JIT技術),所以如何提升效能的議題對於這類遊戲機種的模擬器撰寫來說完全不是議題,寫得好不好反來是對於硬體特性熟悉的夠不夠透徹而定,至於程式大概是都可以過最少60FPS門檻不是問題,但一些優化的經驗或許可以使用在日後別的進階機種上,或是把壓榨出的效能放到畫面特效的部分,或是寫出手機版本可以更省電之類的,總之雖然至少以紅白機模擬器來說,效能不會是問題,但學習的經驗是後可用,而看著效能越來越好,fps速度越來越高也是滿有成就感的.
程式寫得好不好其實有很多指標,效能(執行速度)只是一種面向,其他還包括了優不優雅.結構化程度.物件有沒有包得精緻.好不好維護.code長短.所佔記憶體,這些其實都是個別的獨立事件,甚至某些指標還可能有著某些互斥關係,所以當你想優化程式時後,你要想清楚你的目的為何.
另外c#效能優化的好不好其實靠感覺很不準,有某些撇步幾乎可以說是通則,但有某些只成立在某些條件下,你幾乎很難說用怎樣的方式就是比較好,就算你把優化目標縮限在速度這點,靠經驗法則其實還是有點不可靠,stopwatch看一下cost time才可信,而模擬器則剛好有fps的數據可以參考.
難以捉摸的原因是在於幾點 1.環境.硬體.版本.編譯條件差異,這些都會導致你以為的通則失效 2.編譯成為IL code,雖然可以反組譯看一下 IL code內容,但這還不是實際執行的行為,最後還有 JIT 的影響,而最關鍵的JIT 除非去追X86的asm,不然就是一個黑箱(真的很謎樣) 3.連帶影響性,好比說你改用了某個寫法,那寫法雖然比較快,但因為你改了另一種寫法,code的其他部分得相對修改,而相對修改的其他的code部分反來拖慢速度,所以看速度最好是最後整體結果測量
所以目前得到的感想是,反正就是stopwatch觀察看看,真的很可以確定是優化通則的就自己筆記下來,其他的case by case 測試,沒什麼很一定的道理,因為一切到了 JIT 層後沒人會知道實際上做了啥事(雖然實際上也視有方法可以去trace就是)
現在就來示範一段實際的優化過程(剛好也心血來潮地就順道筆記一下)..
首先是模擬器啟動後無限迴圈的反覆動作,先示範一個尚未優化版本
static public void run()
{
StopWatch.Restart();
while (!exit)
{
cpu_step();
do { ppu_step(); ppu_step(); ppu_step(); } while (--cpu_cycles > 0);
}
Console.WriteLine("exit..");
}
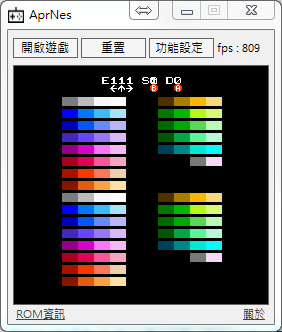
FPS大概在 810左右
接下來進行優化,可以從code看出這模擬器程式裡頭有一個不斷進行的反覆迴圈,在.net後來的版本增加了一個屬性叫 [MethodImpl(MethodImplOptions.AggressiveInlining)] , 就我的理解有這個屬性宣告method實際上運作會內崁處理 , 應該是會省去 metohd 呼叫必要的 stack push pop 時間,在這種高度頻繁的呼叫下,對於節省時間有幫助,不過還是要實際測試一下,因為是做類似內崁的動作,導致一個method裡面的code實際上體積是變大了,CPU還得考慮到code cache等等複雜問題, 有過加入 [MethodImpl(MethodImplOptions.AggressiveInlining)] 屬性宣告下能反來下降的狀況,似乎只適合某些條件,否則可能會有反效果.(這部分其實可以談的很深入,但小弟外行只以結果論).
PS.以往習慣用 .NET Framework 4.0搭配 vs2010開發,但後來發現 .net 4.5真的有不少必要的好處,包括像是我程式開zip檔有直接內建class可以用,記憶體使用上限可以突破4G,以及新增的 [MethodImpl(MethodImplOptions.AggressiveInlining)]等等好處,讓我從善如流改用新版了,時間過得真的是很快阿....
在這while迴圈中 cpu_step() 與 ppu_step() 執行是相當吃重的兩個部份 , 那我們就將這兩個部份加上 [MethodImpl(MethodImplOptions.AggressiveInlining)]
[MethodImpl(MethodImplOptions.AggressiveInlining)]
static void cpu_step()
{
[MethodImpl(MethodImplOptions.AggressiveInlining)]
static void ppu_step()
{
在這邊大家會注意到為啥我的method會使用static,因為static class 內static method與static method呼叫可以省去傳遞一個 this 指標 , IL code可以看出差異 , 實際執行整體速度也拉上上去,但依照維護的觀點來說,這並不是一個值得鼓勵的做法.
接著也是一個比較有影響的優化環節....先解釋一下模擬器需要實做記憶體介面的部分,也就是依照memory map做一個處理router,怎樣的address的讀與寫應該做那些動作,這個介面的router常常會用到(nes rom的mapper也是一個例子,但不知道我在說啥就算了....),這邊先對cpu使用的記憶體sapce來優化,首先是原始版本
namespace AprNes
{
unsafe public partial class NesCore
{
byte* NES_MEM;
byte Mem_r(ushort address)
{
if (address < 0x2000) return NES_MEM[address & 0x7ff];
else if (address < 0x4020) return IO_read(address);
else if (address < 0x6000) return MapperRouterR_ExpansionROM(address);
else if (address < 0x8000) return MapperRouterR_RAM(address);
else return MapperRouterR_RPG(address);
}
void Mem_w(ushort address, byte value)
{
if (address < 0x2000) NES_MEM[address & 0x7ff] = value;
else if (address < 0x4020) IO_write(address, value);
else if (address < 0x6000) MapperRouterW_ExpansionROM(address, value);
else if (address < 0x8000) MapperRouterW_RAM(address, value);
else MapperRouterW_PRG(address, value);
}
}
}
它可以有幾個後續的改良版本,包括像是按照address可能的出現頻率,將 address的區域判斷做上下調整,頻率較高的擺前面一點,或是改用 switch , 但我對switch印象其實不是很好,若是case數量在4.5個內,我常比較習慣使用if else來解決.
拿Mem_w method示範一下switch
[MethodImpl(MethodImplOptions.AggressiveInlining)]
static void Mem_w(ushort address, byte value)
{
switch (address & 0xf000)
{
case 0:
case 0x1000:
NES_MEM[address & 0x7ff] = value;
break;
case 0x2000:
case 0x3000:
case 0x4000:
IO_write(address, value);
break;
case 0x5000:
MapperObj.MapperW_ExpansionROM(address, value);
break;
case 0x6000:
case 0x7000:
MapperObj.MapperW_RAM(address, value);
break;
case 0x8000:
case 0x9000:
case 0xa000:
case 0xb000:
case 0xc000:
case 0xd000:
case 0xe000:
case 0xf000:
MapperObj.MapperW_PRG(address, value);
break;
}
}
接著就是一次到位的方式.....跟switch一樣是有點類似的味道,但可以做到更直接的定位,但是算是以空間換取時間的方法,而且剛好也可以用在這種早期8bit cpu 的記憶體空間(16bits的address line有64KByte範圍,依照現在的眼光來說小case).
static Action<ushort, byte>[] mem_write_fun = null;
static Func<ushort, byte>[] mem_read_fun = null;
先宣告Action與Func的array , 若是熟悉 delegate 的用法也習慣使用delegate ,當然也可以用它,實際上測試起來差不多...不過delegate我是覺得多那麼一點麻煩就是...
接著初始化這兩個array
static void init_function()
{
mem_write_fun = new Action<ushort, byte>[0x10000];
mem_read_fun = new Func<ushort, byte>[0x10000];
for (int address = 0; address < 0x10000; address++)
{
if (address < 0x2000) mem_write_fun[address] = new Action<ushort, byte>((addr, val) => { NES_MEM[addr & 0x7ff] = val; });
else if (address < 0x4020) mem_write_fun[address] = new Action<ushort, byte>(IO_write);
else if (address < 0x6000) mem_write_fun[address] = new Action<ushort, byte>(MapperObj.MapperW_ExpansionROM);
else if (address < 0x8000) mem_write_fun[address] = new Action<ushort, byte>(MapperObj.MapperW_RAM);
else mem_write_fun[address] = new Action<ushort, byte>(MapperObj.MapperW_PRG);
}
for (int address = 0; address < 0x10000; address++)
{
if (address < 0x2000) mem_read_fun[address] = new Func<ushort, byte>((addr) => { return NES_MEM[addr & 0x7ff]; });
else if (address < 0x4020) mem_read_fun[address] = new Func<ushort, byte>(IO_read);
else if (address < 0x6000) mem_read_fun[address] = new Func<ushort, byte>(MapperObj.MapperR_ExpansionROM);
else if (address < 0x8000) mem_read_fun[address] = new Func<ushort, byte>(MapperObj.MapperR_RAM);
else mem_read_fun[address] = new Func<ushort, byte>(MapperObj.MapperR_RPG);
}
}
原本兩個Mem_r 跟 Mem_w內容改成
[MethodImpl(MethodImplOptions.AggressiveInlining)]
static byte Mem_r(ushort address)
{
return mem_read_fun[address](address);
}
[MethodImpl(MethodImplOptions.AggressiveInlining)]
static void Mem_w(ushort address, byte value)
{
mem_write_fun[address](address, value);
}
順道也加上 [MethodImpl(MethodImplOptions.AggressiveInlining)] 屬性宣告....
來看調整完的效率....
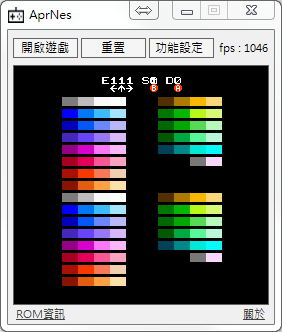
相當可怕 810 提升到 1040多.... 因為對於硬體的正確性一直有許多地方沒有好好study去突破,常常就把心力放在調整效能的部分上,結果調一調最後就是這樣的結果,當然1040的fps根本不能玩,還得加上limite fps的步湊....
ps.藉著這種做法,其實還有PPU memory的介面處理可以優化 ,以及ppu timing step路由也可這樣處理,所以其實還可以再大幅度提升一段,但想等模擬的正確性確認後,再繼續進行這種議題的優化.
這效能其實比多數其他c/c++開發的模擬好太多了,但這麼說也不公平,因為它們的實作是更完整.更複雜的,cost當然也更高,以及以一個程式開發而言,很多人追求維護與結構化更甚於追求效能為目標.
附帶一提,我有幾次進行效能為導向的重構每次都有大幅度提升
1.任何關於array的部分(可以取到item大小的,Action跟Func這種managed的class就沒辦法瞜...).建立存取全改用指標.得借助 Marshal 的功能才能建立 unmanaged 的 pointer , 在C#中應該不是很鼓勵這樣做,這比較是C/C++的玩法.
2.使用static class , 裡面所有method和field都是static的.
3.Mapper的部分改用interface取代自己原先switch的路由實做.
像是影像濾鏡.邊解碼.模擬器等等程式照理來說是c/c++的天下,但工作熟悉的就是C#,所以才想嘗試使用C#,不然使用C/C++或是組語應該會有更多議題空間.
其實模擬器真的比工作上的東西有趣多了,無奈的是模擬器的重點並不在於code,而是在於對於硬體特性掌握度,功能有沒有完善才是重點,所以硬體study才是比較大的議題,但一但對硬體掌握度夠,就可以打開另外一片天空,很有趣.
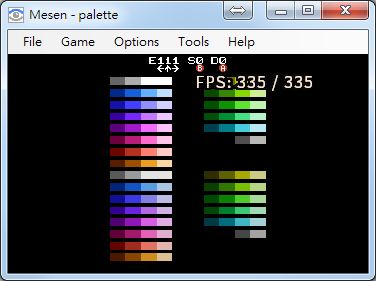
跟另一款效能比較 約335左右...,其他模擬器只要有可以全速運做,能夠設定不limite fps的都也可以比較看看,應該是沒有能夠到1000多fps的...畢竟實作較為完整可靠.
ps.截至到目前為止2017.01.21,我還沒將project code更新上去,所以github都還是舊的東西,想將很多問題解決掉再說.