簡單介紹一下如何使用Python寫一個台灣股價查詢程式
最近開始初學Python,Python最厲害就是網路爬蟲
就來實作一個台灣股價爬蟲吧!!
我不會描述語法為什麼會這樣寫,你應該先去這邊把Python基本語法看完
然後怎麼安裝Python,看這邊,建議安裝Python 3以後的版本
先附上程式碼 :
#!/usr/bin/python3.6
import requests,datetime
from bs4 import BeautifulSoup
now = datetime.datetime.now()
today = now.strftime('%Y%m%d')
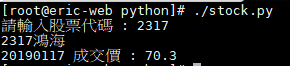
stock_id = input("請輸入股票代碼 : ")
url = 'https://tw.stock.yahoo.com/q/q?s='+stock_id
try:
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
table = soup.find_all(text='成交')[0].parent.parent.parent
stock_name = table.select('tr')[1].select('td')[0].text
price = table.select('tr')[1].select('td')[2].text
print(stock_name.strip('加到投資組合'))
print(today,'成交價 :',price)
except:
print('股票代碼錯誤或查無此代碼!!')
因為本身的作業系統在Linux底下,為了方便使用,第一行直接宣告環境變數,讓python程式可以和shell script有一樣的執行方式
Python強大的地方就是很多module可以套用,第二行import的部分我導入了兩個modules : reuqests datetime
reuqest : 負責擷取html原始碼,讓我可以透過原始碼找到我們想爬的資訊 (需要透過pip另外安裝)
datetime : 日期時間相關module,這邊我需要顯示當天日期,所以呼叫它
from bs4 import BeautifulSoup
這邊html parser的部分我用BeautifulSoup來進行,查了一下它是蠻有名的套件啦!! (需要透過pip另外安裝)
接著,我是透過Yahoo股票來做為查詢目標,所以先用chrome開發者人員工具來看看股價的原始碼
可以發現 : https://tw.stock.yahoo.com/q/q?s=0050 這個url就可以查到台灣50(0050)的股價
html原始碼如下 :
<table border=0 cellSpacing=0 cellpadding="0" width="750">
<tr>
<td>
<table border=2 width="750">
<tr bgcolor=#fff0c1>
<th align=center >股票<br>代號</th>
<th align=center width="55">時間</th>
<th align=center width="55">成交</th>
<th align=center width="55">買進</th>
<th align=center width="55">賣出</th>
<th align=center width="55">漲跌</th>
<th align=center width="55">張數</th>
<th align=center width="55">昨收</th>
<th align=center width="55">開盤</th>
<th align=center width="55">最高</th>
<th align=center width="55">最低</th>
<th align=center>個股資料</th>
</tr>
<tr>
<td align=center width=105><a
href="/q/bc?s=0050">0050元大台灣50</a><br><a href="/pf/pfsel?stocklist=0050;"><font size=-1>加到投資組合</font><br></a></td>
<td align="center" bgcolor="#FFFfff" nowrap>09:25</td>
<td align="center" bgcolor="#FFFfff" nowrap><b>75.55</b></td>
<td align="center" bgcolor="#FFFfff" nowrap>75.55</td>
<td align="center" bgcolor="#FFFfff" nowrap>75.60</td>
<td align="center" bgcolor="#FFFfff" nowrap><font color=#000000>0.00
<td align="center" bgcolor="#FFFfff" nowrap>1,800</td>
<td align="center" bgcolor="#FFFfff" nowrap>75.55</td>
<td align="center" bgcolor="#FFFfff" nowrap>75.60</td>
<td align="center" bgcolor="#FFFfff" nowrap>75.90</td>
<td align="center" bgcolor="#FFFfff" nowrap>75.55</td>
<td align=center width=137 class="tt">
<a href="/q/ts?s=0050">成交明細</a><br><a href="/q/ta?s=0050">技術</a> <a href='/q/h?s=0050'>新聞</a><a href='/d/s/company_0050.html'><br>基本</a> <a href='/d/s/credit_0050.html'>籌碼</a><br><a target='_blank' style='color:red' href='https://tw.rd.yahoo.com/referurl/stock/other/SIG=125v47s73/**https://tw.screener.finance.yahoo.net/screener/check.html?symid=0050'>個股健診</a></font></td> </tr>
</table>
</td>
</tr>
</table>
這個html table裡面,已經有我們想要的全部資料(股票名稱和成交價),然後第一個關鍵字"成交",就可以找到這個html table描述
所以
1. 先把今天日期做出來,先用datetime.now()抓出今天日期,再利用strftime把日期自定成我們想要的格式 (20190117)
now = datetime.datetime.now()
today = now.strftime('%Y%m%d')
2. https://tw.stock.yahoo.com/q/q?s= 這個 q/q?s= 後面只要帶上股票代碼就可以連結到該檔股票頁面,所以讓使用者透過輸入股票代碼的方式帶入
stock_id = input("請輸入股票代碼 : ")
url = 'https://tw.stock.yahoo.com/q/q?s='+stock_id
3. 接著透過requests module去把url中的網頁原始碼拉回來,呼叫BeautifulSoup module裡面的html.parser來準備進行網頁爬蟲
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
4. soup.find_all可以在所有原始資料中找到第一個關鍵字 : 成交 soup.find_all(text='成交')[0]
5. 根據html原始碼,找到成交之後,上一層是一個<th>,再上一層是一個<tr>,在上一層就是<table>描述,所以利用parent來切換三層,找到整個table資料
table = soup.find_all(text='成交')[0].parent.parent.parent
6. 現在整個table資訊都被存到table變數中,BeautifulSoup的select功能,可以在html table描述中透過位置幫我們找到所要的資訊
第一個要抓股票名稱 : 0050元大台灣50,這個關鍵字位在第二個<tr>的第一個<td>中 (位置從0開始計算)
所以 stock_name = table.select('tr')[1].select('td')[0].text 就抓出股票名稱,並透過.text存成文字
第二個要抓成交價,這個關鍵字位在第二個<tr>的第三個<td>中
所以price = table.select('tr')[1].select('td')[2].text就抓出成交價,並透過.text存成文字
7. 然後,股票名稱抓出來會一起帶出 : 0050元大台灣50加到投資組合,所以要把"加到投資組合"給處理掉,透過strip來處理
print(stock_name.strip('加到投資組合'))
8. 加上當天日期以及成交價輸出 : print(today,'成交價 :',price)
9. 最後加上例外處理,不得不說,python的例外處理真的太簡單了,如果使用者打錯股價怎麼辦?
利用 try: and expect: 就好了啦!!不用寫一大堆判斷了!!!
10. 打完收工!!
![]()