Neural Network -- 阿拉伯數字辨識
入門
照理講,我們應該先了解『神經網路』(Neural Network)概念,再談如何寫程式,但是,概念介紹內容有點硬,為了提高學習興趣,避免一開始就搞一堆數學公式,造成讀者跑光光,所以,還是柿子挑軟的吃,先從簡單的開始,與 Neural Network 先培養感情,如果您是條硬漢,可以等看完下一篇後,再回頭看這一篇。
我們就先來寫一支程式,目標是『辨識阿拉伯數字(0~9)』。
開發環境建置
首先是選擇開發環境,一般而言,Python 及 R 都有很好的支援及大量的函數庫(Library/Toolbox),而 Python 的框架較易於系統整合(Web、Mobile),因此我選擇 Python,但支援 Python 的 Neural Network 框架(Framework)也很多,參見下圖,要選擇哪一個呢?
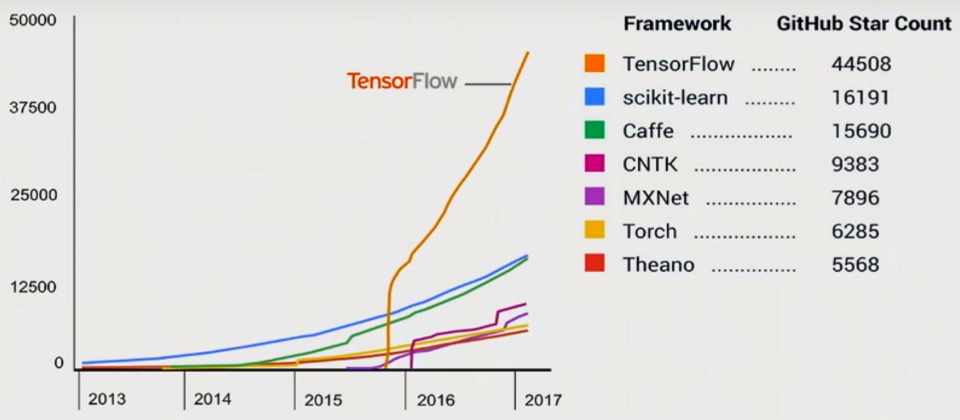
圖. Machine Learning 框架(Framework)GitHub評比,資料來源:【AI關鍵技術】三大熱門深度學習框架新進展。
其中,TensorFlow 網路聲量最高,因此,我們採用它作為程式開發的基礎,Keras 則是支援TensorFlow的更高階函數庫(Meta Framework),可以用很簡潔的程式碼完成一個 Neural Network 模型,非常適合入門學習,因此我們就從 Keras 開始學起。
首先我們要建構開發環境,筆者以 Windows 環境為例,依序安裝以下軟體:
- 安裝 Anaconda: 它包含 Python 及常用的套件(Packages),例如NumPy、Pandas等矩陣運算的套件,Python V2 與 V3 不相容,我們選 V3,除非你以前曾大量使用 V2。
- 安裝 Tensorflow:可以選擇CPU或GPU版,安裝CPU版,直接在 DOS 下,輸入 pip3 install tensorflow。
- 安裝 Keras:在 DOS 下,輸入 pip3 install keras。
就是這麼簡單,當然,為了加速運算,你也可以安裝支援GPU版本的Tensorflow,NVidia支援CUDA的顯示卡請參考這裡 ,相關安裝程序請參考tensorflow官網,如果要在 Linux 環境開發也行,安裝內容不變, 請參考這裡。
以我的電腦為例,配備如下圖,GPU顯示卡為NVIDIA GeForce GTX 750(1GB memory),實際安裝 Tensorflow GPU 版本的程序如下:
- 下載 CUDA Toolkit 8.0,不能是 9.x,需先至nVidia官網建立帳號,再至 https://developer.nvidia.com/cuda-toolkit-archive 下載。
- 安裝完 CUDA Toolkit 後,再下載 cuDNN v6.x ,並將壓縮檔解開,複製到 CUDA Toolkit 8.0 安裝目錄下同名子目錄下。
- 將 CUDA Toolkit 8.0 安裝目錄下bin子目錄 放到 環境變數 Path 中,在 DOS 中執行Tensorflow時,才找的到相關 Dll。
- 安裝 Tensorflow GPU 版本,執行
pip install --ignore-installed --upgrade tensorflow-gpu - 在 DOS 中執行 python,接著輸入下列程式,應該就會有相關訊息出現。
import tensorflow as tf
hello = tf.constant('Hello, TensorFlow!')
sess = tf.Session()
print(sess.run(hello))
實際測試簡單的程式,確實快很多,但是記憶體太小,遇到複雜的程式,例如後續的CNN程式,需要儲存大量矩陣時,就GG了,所以,奉勸各位,要學 Neural Network,還是要花錢買張新一點的顯示卡,才能省去執行時去泡茶、喝咖啡的時間。
如果一切順利完成,就可以開始寫程式了。等一下,那 IDE 呢? 你可以用記事本、NodePad++、或者PyCharm,我則是使用 VS 2017 Community 版本,它也是一個很不錯的選擇喔,可以像 C# 一樣的除錯。另外,使用 Jupyter Notebook,可以讓你像作筆記一樣的寫程式,總之,戲法人人會變,端看你熟悉甚麼樣的環境與工具。
程式撰寫
撰寫 Keras 程式,我們需要了解簡單的 Python 語法,建議快速瀏覽『Introducing Python』這本書的第二~四章就夠了,它不只有中文版,也有免費的PDF電子書喔。
以下範例主要是利用 MNIST 資料集的訓練資料,建立單一隱藏層(Hidden Layer)的 Neural Network 模型,以預測實際影像是哪一個阿拉伯數字,如下圖:
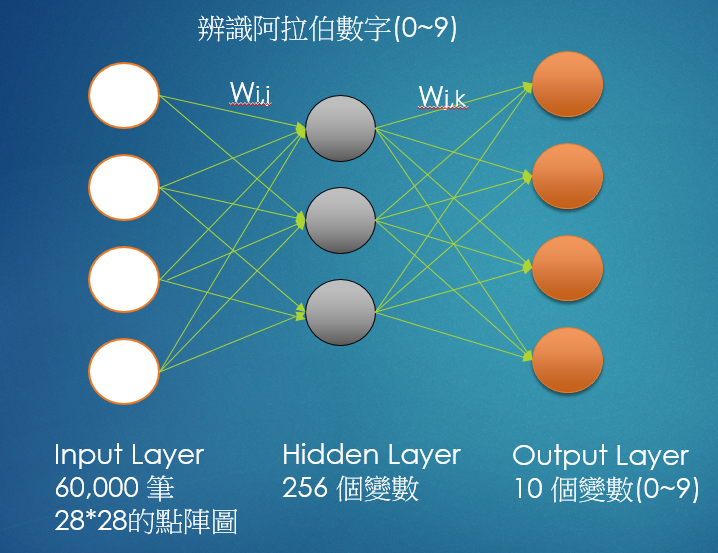
圖. 阿拉伯數字(0~9)辨識的流程
流程步驟如下:
- 先讀入訓練資料,本例為 60,000 筆資料,每筆資料是一個 28 * 28 的點矩陣圖形。
- 圖形的每一點都當成一個輸入變數(X),乘以一個權重W(i,j),向隱藏層(Hidden Layer)傳導,隱藏層的每一個節點會得到輸入變數的加權總和(W * X)。
- 再如法炮製,向輸出層傳導,輸出層的每一個節點會得到隱藏層的加權總和,將輸出層的每一個節點化為機率,就得到一個預測模型了。
- 之後我們將新資料輸入模型,就會得到 0~9 的機率,最大的機率對應的數字就是我們的預測值了。
- 權重(W)是唯一未知的變數,他們等於多少呢? 這就是 Neural Network 厲害的地方,它透過優化(Optimization)計算,就可以求出 W 的最佳解,構築出模型公式了。
程式很簡單,先看註解(#開頭),即可了解整個流程:
- 導入(import)要使用的函式庫,包括 NumPy(矩陣運算)、Keras、matplotlib(繪圖)。
- 從網路載入 MNIST 資料集,請 Keras 自動分為『訓練組』及『測試組』資料,MNIST 是由 AI 大師 Yann LeCun 所建立的手寫阿拉伯數字資料集(Dataset)。
- 建立最簡單的線性模型(Sequential),就是一層層往下執行,沒有分叉(If),也沒有迴圈(loop),這裡只設一層隱藏層(Dense)。
- 選擇損失函數(crossentropy)及優化方法(adam)及成效衡量方式(accuracy),就可以開始訓練。
- 執行模型評估,計算模型參數,即上圖的W(i,j)及W(j,k),模型就算完成了。
- 接著就可以使用這個模型,預測新資料了。
# 導入函式庫
import numpy as np
from keras.models import Sequential
from keras.datasets import mnist
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.utils import np_utils # 用來後續將 label 標籤轉為 one-hot-encoding
from matplotlib import pyplot as plt
# 載入 MNIST 資料庫的訓練資料,並自動分為『訓練組』及『測試組』
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 建立簡單的線性執行的模型
model = Sequential()
# Add Input layer, 隱藏層(hidden layer) 有 256個輸出變數
model.add(Dense(units=256, input_dim=784, kernel_initializer='normal', activation='relu'))
# Add output layer
model.add(Dense(units=10, kernel_initializer='normal', activation='softmax'))
# 編譯: 選擇損失函數、優化方法及成效衡量方式
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 將 training 的 label 進行 one-hot encoding,例如數字 7 經過 One-hot encoding 轉換後是 0000001000,即第7個值為 1
y_TrainOneHot = np_utils.to_categorical(y_train)
y_TestOneHot = np_utils.to_categorical(y_test)
# 將 training 的 input 資料轉為2維
X_train_2D = X_train.reshape(60000, 28*28).astype('float32')
X_test_2D = X_test.reshape(10000, 28*28).astype('float32')
x_Train_norm = X_train_2D/255
x_Test_norm = X_test_2D/255
# 進行訓練, 訓練過程會存在 train_history 變數中
train_history = model.fit(x=x_Train_norm, y=y_TrainOneHot, validation_split=0.2, epochs=10, batch_size=800, verbose=2)
# 顯示訓練成果(分數)
scores = model.evaluate(x_Test_norm, y_TestOneHot)
print()
print("\t[Info] Accuracy of testing data = {:2.1f}%".format(scores[1]*100.0))
# 預測(prediction)
X = x_Test_norm[0:10,:]
predictions = model.predict_classes(X)
# get prediction result
print(predictions)
執行方法很簡單,在DOS執行Python,接著將以上程式一段段貼上即可,我們就可以觀察每段程式的用途,要看變數內容,只要輸入變數名稱即可,全部執行完,可以看到準確率有 85%,夠神奇吧,畢竟我們只寫了10多行的程式(不含註解)。
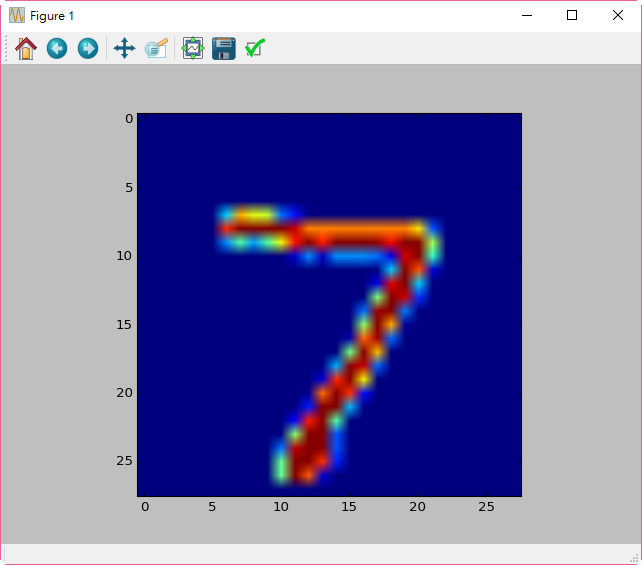
要確認預測是否正確,可以再貼上下列程式,查看影像:
# 顯示 第一筆訓練資料的圖形,確認是否正確
plt.imshow(X_test[0])
plt.show()
如果我們要看優化的過程,可以輸入以下程式,結果如下圖:
plt.plot(train_history.history['loss'])
plt.plot(train_history.history['val_loss'])
plt.title('Train History')
plt.ylabel('loss')
plt.xlabel('Epoch')
plt.legend(['loss', 'val_loss'], loc='upper left')
plt.show()
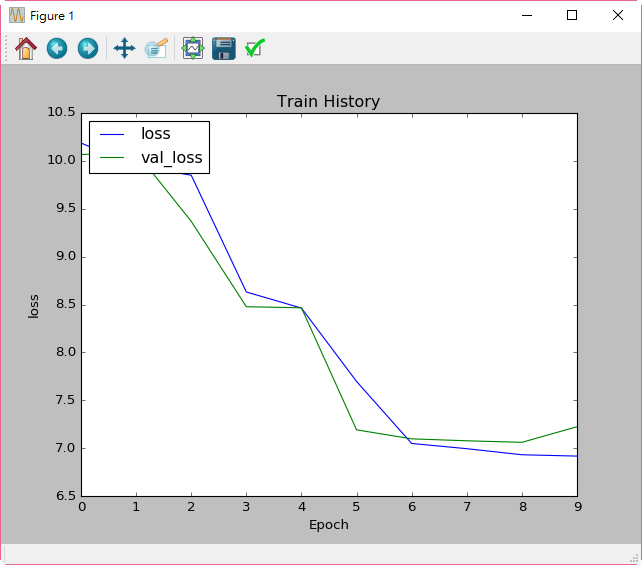
圖. 優化過程的損失函數(Loss)的變化
進行到這裡,我們已經跨出了一小步,後續我們接著抽絲剝繭,好好研究它為什麼可以這麼厲害。
相關程式請至這裡 下載,本範例為0.py。
註:本系列發文,會同時在 IT Home 鐵人賽發佈。