關於 Keras 的一些小技巧
前言
再往下探究之前,我們輕鬆一點,先作點實驗,驗證上上篇的程式辨識準確率是否真的那麼高? 可否在應用系統上使用? 譬如,阿拉伯數字辨識率如果那麼高,我們是否可以提供手寫板,讓用戶直接輸入,用於輸入密碼、開鎖、填寫問卷、考試答題...等等。
另外,在實驗之前,我們先討論一些 Keras 小技巧,讓我們在開發程式時更有效率,包括:
- 模型存檔
- Keras 組態
- 資料集(Datasets)
- Keras事先訓練好的應用程式(Applications)
模型存檔(Persistence)
模型訓練完畢後,結果如可接受,可以將模型存檔,下次要再測試時,就可直接載入,不需重新訓練,模型的資訊包括結構及訓練出來的權重(W)。
- 模型結構存檔:以下程式將結構存到 model.config 檔案,檔案為JSON或YAML格式。
from keras.models import model_from_json
json_string = model.to_json() with open("model.config", "w") as text_file:
text_file.write(json_string)
- 權重(W)存檔:以下程式將權重存到 model.weight 檔案。
model.save_weights("model.weight")
- 同時儲存結構與權重,檔案的類別為HDF5。
from keras.models import load_model
model.save('model.h5') # creates a HDF5 file 'model.h5'
模型載入
之後,我們要使用時,可輸入下列程式碼,載入模型結構及權重(W)。
import numpy as np
from keras.models import Sequential
from keras.models import model_from_json
with open("model.config", "r") as text_file:
json_string = text_file.read()
model = Sequential()
model = model_from_json(json_string)
model.load_weights("model.weight", by_name=False)
或者直接載入HDF5檔案
from keras.models import load_model
# 刪除既有模型變數
del model
# 載入模型
model = load_model('my_model.h5')
Keras 組態
- Keras 組態檔名稱為 keras.json,會儲存在使用者資料夾下的『.keras』子目錄。
- 如果你下載Keras事先訓練好的應用程式(Applications),它就會放在使用者資料夾下的『.keras\models』子目錄。
- 如果你下載Keras的資料集(Datasets),例如,之前程式下載 MNIST 阿拉伯數字資料集,它就會放在使用者資料夾下的『.keras\datasets』子目錄。不用 (X_train, y_train), (X_test, y_test) = mnist.load_data(),要直接開啟檔案,程式碼如下:
f = np.load(get_file("mnist.npz", origin="~/.keras"))
x_train = f['x_train']
y_train = f['y_train']
x_test = f['x_test']
y_test = f['y_test']
f.close()
如果,直接從網路下載,可改為
f = np.load(get_file("mnist.npz", origin="https://s3.amazonaws.com/img-datasets/mnist.npz"))
Keras事先訓練好的應用程式(pre-trained Applications)
Keras提供幾個事先訓練好的經典應用程式,不必重新訓練,可直接套用,請參考官方文件,使用方法如下:
from keras.applications.vgg16 import VGG16
from keras.applications.vgg16 import preprocess_input
import numpy as np
model = VGG16(weights='imagenet', include_top=False)
官方文件找不到詳細用法,我花費好一番功夫才弄懂,後面談到 CNN 會詳細介紹,敬請期待。
資料集(Datasets)
Keras提供幾個現成的資料集,可作為訓練/測試資料,,請參考官方文件,包括手寫數字、分類圖片、影評、新聞、... 等。也可以自其他網站下載,例如,你覺得辨識0~9不過癮,也想辨識 A~Z, a~z,可至這裡下載。
實驗
我用C#寫了一個Draw.exe 小程式, Source Code 放在這裡,可以使用滑鼠,書寫數字,並將它存成與MNIST類似的格式(.csv),再用Python程式載入,依照訓練出來的模型測試是否可以辨識,步驟如下:
- 執行 Draw.exe,書寫 0~9,並存成 0.csv, 1.csv ..., 9.csv。
- 在DOS下,執行 python 0_1.py,假設此程式與*.csv放在同目錄。
- 可以看到10個數字的辨識結果,如果都正確,那就恭喜你了。
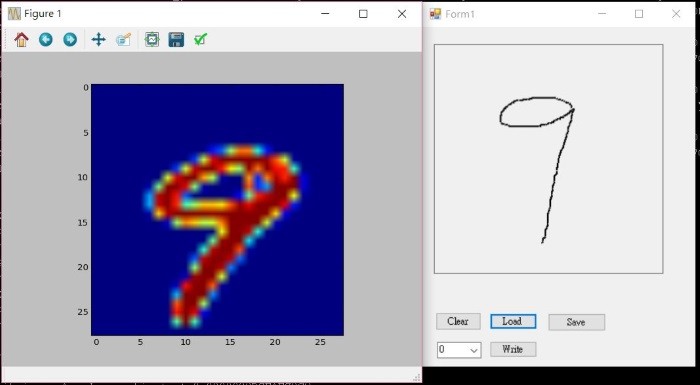
圖. 手寫數字 9 的比較,左為 MNIST, 右為筆者以 Draw.exe 手寫的數字
結論
筆者反覆測試多次,發覺測試結果並不如MNIST測試資料那麼準確,可能原因有二,正所謂『盡信書,不如無書』:
- 筆者書寫阿拉伯數字的樣貌與外國人不同。
- 筆畫的粗細/陰影(Anti-alias)與MNIST有差異,造成辨識率不佳。
另外,訓練出來的準確率均達85%,甚至95%,乍看很高,但仔細想想,如果是應用在銀行存款數目的辨識,使用者輸入10位數,只要一個數字錯,銀行老董可能就要崩潰了,反之,用在遊戲中,使用者可能會讚聲連連,驚嘆不已,所以,Machine Learning 的應用還是必須考量使用的時機與應用場域,才能贏得掌聲。