卷積神經網路(Convolutional Neural Network)
『自然使用者介面』(Natural User Interface, NUI)
這一波的人工智慧在自然使用者介面(Natural User Interface, NUI)有突破性的進展,包括影像(Image、Video)、語音(Voice)與文字(Text)的辨識、生成與分析,機器透過這種人類與生俱來的溝通能力,與使用者互動不僅更具親和力,也能對週遭的環境作出更合理、更有智慧的判斷與反應,尤其是,將這種能力附加到產品上,使產品應用發展產生無限的發展潛力,包括無人駕駛車、無人機、智慧家庭(Smart Home)、製造機器人(Robot)、聊天機器人(ChatBot) ...等。
從這一篇開始,我們就逐一來探討影像(Image、Video)、語音(Voice)、文字(Text)的相關演算法,之前我們只用10幾行程式辨識阿拉伯數字,就令筆者興奮不已,接下來,介紹另一個演算法『卷積神經網路』(Convolutional Neural Network, CNN),它可以自動進行『特徵萃取』(Feature Extraction),從而應用在影像辨識及自然語言處理(NLP)上,也因『卷積層』(Convolution Layer)概念的導入,可以非常有效減輕 Neural Network 訓練的負載。
卷積神經網路(Convolutional Neural Network, CNN)
CNN 也是模仿人類大腦的認知方式,譬如我們辨識一個圖像,會先注意到顏色鮮明的點、線、面,之後將它們構成一個個不同的形狀(眼睛、鼻子、嘴巴...),這種抽象化的過程就是CNN演算法建立模型的方式。卷積層(Convolution Layer) 就是由點的比對轉成局部的比對,透過一塊塊的特徵研判,逐步堆疊綜合比對結果,就可以得到比較好的辨識結果,過程如下圖。
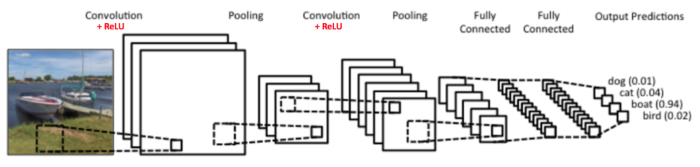
圖. CNN概念,圖片來源:An Intuitive Explanation of Convolutional Neural Networks
卷積層(Convolution Layer)
那我們如何從點轉成面呢? 很簡單,就是以圖像的每一點為中心,取周遭 N x N 格的點構成一個面(N 稱為 Kernal Size,N x N 的矩陣權重稱為『卷積核』),每一格給予不同的權重,計算加權總和,當作這一點的 output,再移動至下一點以相同方式處理,至圖像的最後一點為止,這就是 CNN 的卷積層(Convolution Layer),請參考下圖,CS231n: Convolutional Neural Networks for Visual Recognition 一文的Convolution Demo段落,它以動畫的方式說明取樣的方式。卷積層處理方式與影像處理方法類似,採用滑動視窗(Sliding Window)運算,藉由給予『卷積核』不同的權重組合,就可以偵測形狀的邊、角,也有去除噪音(Noise)及銳化(Sharpen)的效果,萃取這些特徵當作辨識的依據,這也克服了迴歸(Regression)會受『異常點』(Outliers)嚴重影響推測結果的缺點,好比說一個人的鼻子長了一顆痣,我們也應該能依據形狀辨識出那是鼻子。
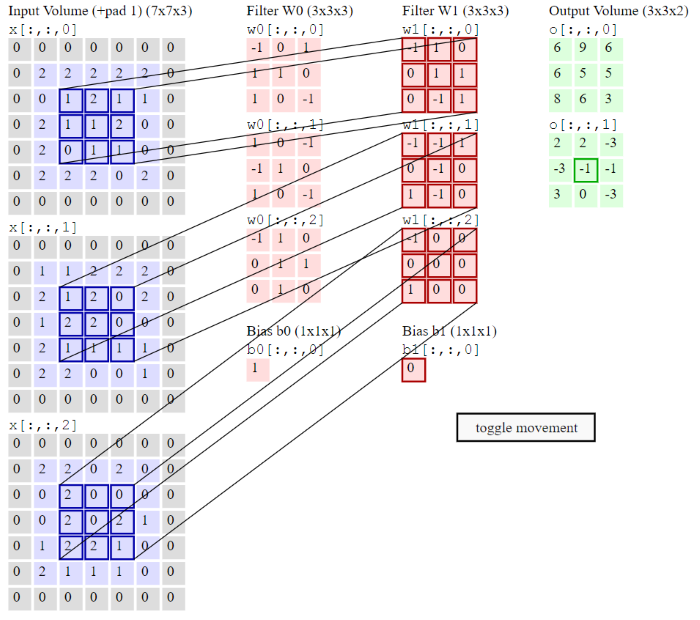
圖. 卷積層(Convolution Layer) 運算方式,圖片來源:CS231n: Convolutional Neural Networks for Visual Recognition
若不引入卷積層,使用單純的隱藏層(Dense),即第二篇的作法,不僅需要很大的記憶體,計算也會耗費很長的時間,我們看一個真實的案例,ImageNet 2012 挑戰賽的題目,辨識 227 x 227 點的全彩圖案,每一點R/G/B各佔24 bits,故輸入層單一張圖的資料量就有 227 x 227 x 96,假設有60,000個樣本,隱藏層輸出1000個變數,那矩陣運算就是(60000, 227 x 227 x 96) 與 (227 x 227 x 96, 1000)的內積,那是一個多麼龐大的迴圈運算。而卷積層的概念是假設我們在看一張圖時,每個神經元只會接收一小塊區域的反射光線,稱為『感受野』(receptive field),也就是說,隱藏層的神經元只會連接上一層『感受野』內的Input(11x11),而不會連接『所有』的Input(227x227),稱之為『局部連接』(Locally Connected),而非『完全連接』所有 Input。
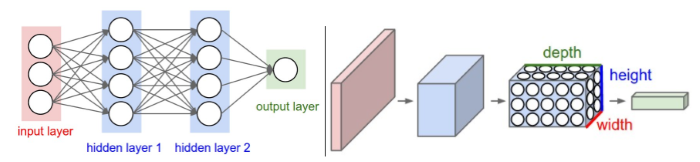
圖. 『完全連接』(Fully Connected) vs.『局部連接』(Local Connected),圖片來源:CS231n Convolutional Neural Networks for Visual Recognition
每個隱藏層的神經元就只跟Input矩陣(11, 11)作運算,運算負擔就明顯減輕了,另外,還有一個假設,稱為『共享權值』(Shared weights),就是每一個『感受野』對下一隱藏層均使用相同的一組權重(Weight Matrix),請參閱下圖,這樣要推估的權重數量減少,又可以減輕運算的負擔,所以,運用卷積層的目的就是針對圖像或語言的特性,簡化計算的過程,進而縮短運算的時間。
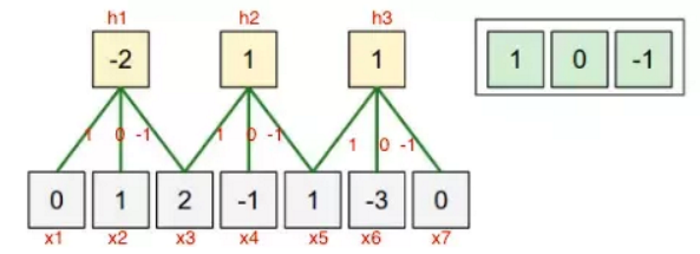
圖. 『權值共享』(Shared weights),圖片來源:What exactly is meant by shared weights in convolutional neural network?
在使用卷積層函數(Conv1D、Conv2D、Conv3D...)時,我們可以設定濾波器(Filter)的數目,系統在訓練的過程中,就會根據Input圖形,幫我們找出圖中出現的各種形狀濾波器(Filter),例如(+、X、O...),再往下加幾層卷積層,我們就可能找出圖像會包含的各種特徵,例如,眼睛、嘴巴、鼻子等,我們來看卷積四次的濾波器(Filter),圖片來源為 https://cs.nyu.edu/~fergus/drafts/utexas2.pdf ,第一層只偵測到線,到了第四層,就幾乎得到整個輪廓了。

圖. 第一層濾波器(Filter)。

圖. 第二層濾波器(Filter)。
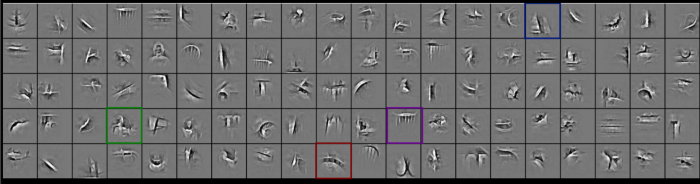
圖. 第三層濾波器(Filter)。

圖. 第四層濾波器(Filter)。
池化層(Pooling Layer)
卷積層之間通常會加一個池化層(Pooling Layer),它是一個壓縮圖片並保留重要資訊的方法,取樣的方法一樣是採滑動視窗,但是通常取最大值(Max-Pooling),而非加權總和,若滑動視窗大小設為2,『滑動步長』(Stride) 也為 2,則資料量就降為原本的四分之一,但因為取最大值,它還是保留局部範圍比對的最大可能性。也就是說,池化後的資訊更專注於圖片中是否存在相符的特徵,而非圖片中『哪裡』存在這些特徵,幫助 CNN 判斷圖片中是否包含某項特徵,而不必關心特徵所在的位置,這樣圖像偏移,一樣可以辨識出來(部分文字引用自卷積神經網路的運作原理 一文)。
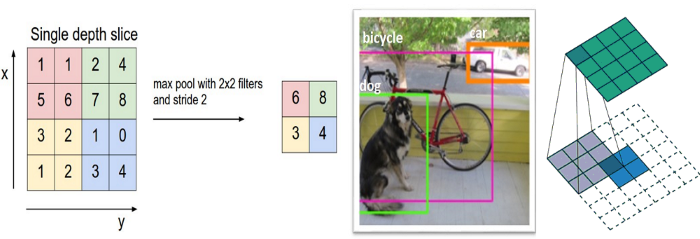
圖. Max-Pooling, 視窗大小為2,『步長』(Stride)也為 2的取樣方法,圖片來源:A Beginner's Guide To Understanding Convolutional Neural Networks
結語
透過多層卷積/池化,萃取特徵當作 Input,再接至一到多個完全連接層,進行分類,這就是CNN的典型作法,下一篇我們就用 CNN 來作阿拉伯數字的辨識,看看有甚麼不同,緊接著,我們再介紹兩個 CNN 應用,說明 Neural Network 不是只能作分類而已。
弄懂這些概念,對後續實作有很大的幫助,請耐心看完,之後的應用都跟本篇有密切的關聯。
明天見了 !!