用 TDD 來練習完成 leet code 的第 220 題,題目描述如下。
Given an array of integers, find out whether there are two distinct indices i and j in the array such that the absolute difference between nums[i] and nums[j] is at most t and the absolute difference between i and j is at most k.
這一題是 leet code 219 的延伸題,看起來貌似多一個變化,在效能的作法上卻是截然不同的思路。
第一個紅燈,k =0 應回傳 false
測試程式碼如下:
[TestMethod]
public void k_is_0_should_return_false()
{
var nums = new int[] { 9 };
var k = 0;
var t = 0;
Assert.IsFalse(new Solution().ContainsNearbyAlmostDuplicate(nums, k, t));
}
產品程式碼,是由測試程式碼透過 Visual Studio 產生的 class 與 function,內容如下:
public class Solution
{
/// <summary>
/// 給定整數數組,找出在陣列中是否存在兩個不同的索引i和j,
/// 使得nums [i]和nums [j]之間的絕對差最大為t,
/// 並且i和j之間的絕對差最大k。
/// </summary>
/// <param name="nums">The nums.</param>
/// <param name="k">The k.</param>
/// <param name="t">The t.</param>
/// <returns></returns>
public bool ContainsNearbyAlmostDuplicate(int[] nums, int k, int t)
{
throw new NotImplementedException();
}
}
用最簡單的程式碼,符合測試案例邏輯,迅速通過第一個紅燈,得到第一個綠燈。
public bool ContainsNearbyAlmostDuplicate(int[] nums, int k, int t)
{
if (k == 0)
{
return false;
}
throw new NotImplementedException();
}
重構測試程式,以便加速後續 TDD 過程
ShouldlBeFalse() 方法出來,後續就可以透過 Visual Studio 的 intellisense 協助,輸入 SBF 就能用最快速度完成 assertion 程式碼。重構完的測試程式如下:
[TestMethod]
public void k_is_0_should_return_false()
{
var nums = new int[] { 9 };
ShouldBeFalse(nums, 0, 0);
}
private static void ShouldBeFalse(int[] nums, int k, int t)
{
Assert.IsFalse(new Solution().ContainsNearbyAlmostDuplicate(nums, k, t));
}
新增一個測試案例,當 nums 長度小於 2,應回傳 false
測試程式如下:
[TestMethod]
public void nums_length_less_than_2_should_return_false()
{
var nums = new int[] { 9 };
ShouldBeFalse(nums, 1, 1);
}
產品程式碼:
public bool ContainsNearbyAlmostDuplicate(int[] nums, int k, int t)
{
if (k == 0 || nums.Length < 2)
{
return false;
}
throw new NotImplementedException();
}
新增一個失敗的測試案例,當 t = 0 時,應等同於 leet code 219 的需求
測試程式如下:
[TestMethod]
public void when_t_is_0_and_k_is_1_nums_5_5_should_return_true()
{
var nums = new int[] {5, 5};
ShouldBeTrue(nums, 1, 0);
}
private void ShouldBeTrue(int[] nums, int k, int t)
{
Assert.IsTrue(new Solution().ContainsNearbyAlmostDuplicate(nums, k, t));
}
使用 leet code 219 透過 HashSet<T> 的方式來通過測試案例
產品程式碼:
public bool ContainsNearbyAlmostDuplicate(int[] nums, int k, int t)
{
if (k == 0 || nums.Length < 2)
{
return false;
}
var set = new HashSet<int>();
for (int i = 0; i < nums.Length; i++)
{
if (!set.Add(nums[i])) return true;
}
throw new NotImplementedException();
}
新增相關測試案例與產品代碼,以滿足所有 t = 0 的情況
測試程式:
[TestMethod]
public void when_t_is_0_and_k_is_1_nums_5_6_5_should_return_false()
{
var nums = new int[] { 5, 6, 5 };
ShouldBeFalse(nums, 1, 0);
}
產品程式碼:
public bool ContainsNearbyAlmostDuplicate(int[] nums, int k, int t)
{
if (k == 0 || nums.Length < 2)
{
return false;
}
var set = new HashSet<int>();
for (int i = 0; i < nums.Length; i++)
{
if (!set.Add(nums[i])) return true;
if (i >= k) set.Remove(nums[i - k]);
}
return false;
}
重構產品程式碼
nums.Length < 2
public bool ContainsNearbyAlmostDuplicate(int[] nums, int k, int t)
{
if (k == 0)
{
return false;
}
var set = new HashSet<int>();
for (int i = 0; i < nums.Length; i++)
{
if (!set.Add(nums[i])) return true;
if (i >= k) set.Remove(nums[i - k]);
}
return false;
}
新增第一個 t 不為 0 失敗的測試案例
測試程式:
[TestCategory("t is not 0")]
[TestMethod]
public void when_t_is_1_and_k_is_1_nums_5_6_should_return_true()
{
var nums = new int[] { 5, 6 };
ShouldBeTrue(nums, 1, 1);
}
用最直覺方式,通過第一個 t 不為 0 的測試案例
nums[i] - nums[i-1] == t hard-code 來滿足。產品程式碼差異如下:
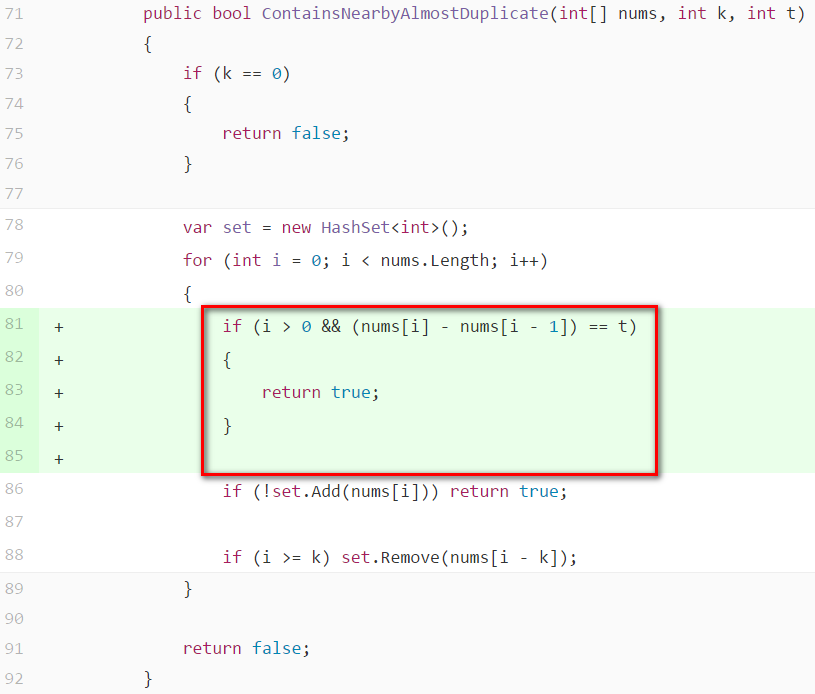
新增一個失敗的測試案例,nums={6,5}, k=1, t=1
測試案例:
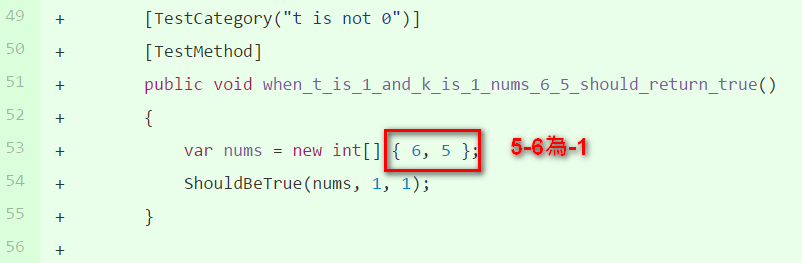
產品程式碼加上 Math.Abs() 來通過測試案例
產品程式碼差異如下:
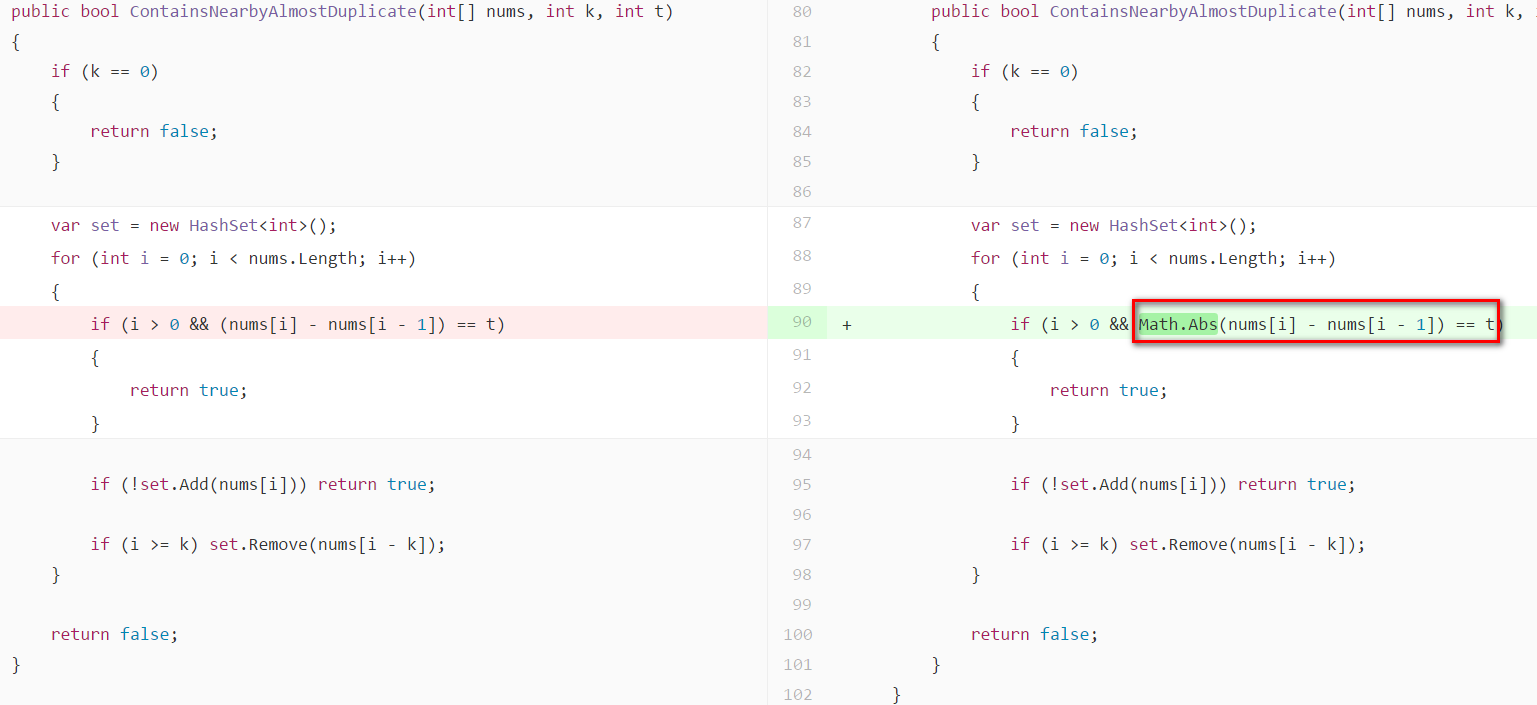
新增一個 k = 2, t = 1 失敗的測試案例
測試程式如下:
[TestMethod]
public void when_t_is_2_and_k_is_2_nums_6_5_4_should_return_true()
{
var nums = new int[] { 6, 5, 4 };
ShouldBeTrue(nums, 2, 2);
}
使用 HashSet<T> 可傳入 IEqualityComparer<T> 的建構式來通過測試
產品程式碼如下:
public class Solution
{
public bool ContainsNearbyAlmostDuplicate(int[] nums, int k, int t)
{
if (k == 0)
{
return false;
}
var set = new HashSet<int>(new DiffEqualityComparer(t));
for (int i = 0; i < nums.Length; i++)
{
if (!set.Add(nums[i]))
{
return true;
}
if (i >= k) set.Remove(nums[i - k]);
}
return false;
}
}
internal class DiffEqualityComparer : IEqualityComparer<int>
{
private readonly int _t;
public DiffEqualityComparer(int t)
{
this._t = t;
}
public bool Equals(int x, int y)
{
return Math.Abs(x - y) == this._t;
}
public int GetHashCode(int obj)
{
return 0;
}
}
GetHashCode() 回傳 0,是希望 HashSet 只依據 Equals() 的邏輯來判斷。但也因此,失去了 HashSet 透過 hash 判斷帶來優越效能的好處。新增失敗的測試案例,t 的判斷並非 == 而是 <= t 即可回傳 true
測試程式:

產品程式碼:
internal class DiffEqualityComparer : IEqualityComparer<int>
{
private readonly int _t;
public DiffEqualityComparer(int t)
{
this._t = t;
}
public bool Equals(int x, int y)
{
return Math.Abs(x - y) <= this._t;
}
public int GetHashCode(int obj)
{
return 0;
}
}
新增失敗的測試案例,修正當 int 為邊界值時,x - y 發生溢位的問題
測試案例:
[TestMethod]
public void nums_intMaxValue_should_not_throw_overflowException()
{
var nums = new int[] { int.MaxValue, -1 };
ShouldBeFalse(nums, 1, 1);
}
在 x - y 的過程中,改為 long 型態處理,通過測試案例
產品程式碼:
internal class DiffEqualityComparer : IEqualityComparer<int>
{
private readonly int _t;
public DiffEqualityComparer(int t)
{
this._t = t;
}
public bool Equals(int x, int y)
{
return Math.Abs((long)x - (long)y) <= this._t;
}
public int GetHashCode(int obj)
{
return 0;
}
}
產品程式碼雖然正確且漂亮,但無法通過 leet code 效能的測試案例
目前的產品程式碼讀起來很好懂,但 leet code 大部分都是考 algorithm 的效能,所以最後一個測試案例還是失敗了。如下圖所示:
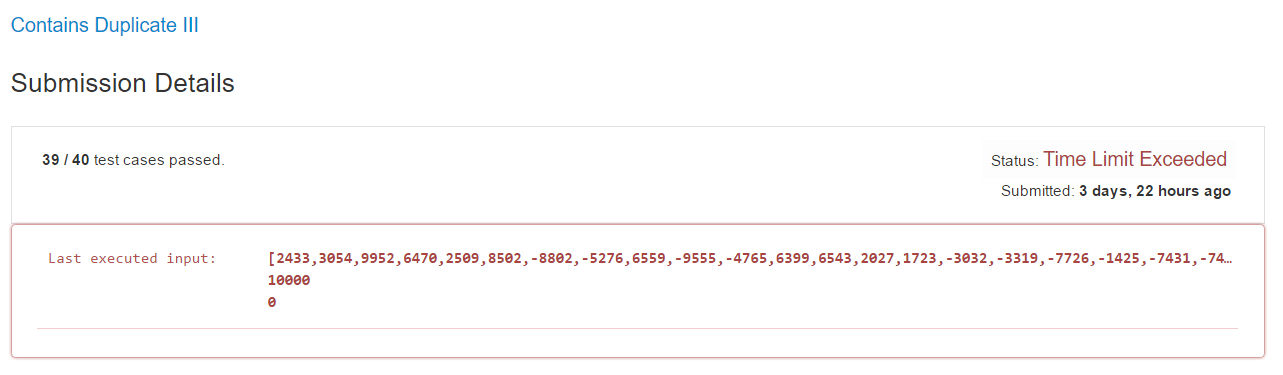
讓我們在欣賞一次目前漂亮的產品程式碼之後,接下來就是要調整演算法以通過所有測試案例。

演算法思路
通常,差值 == t 判斷相等的部分,思路用 hash 是正確的。index 差距 <= k 用 slide window 的概念也頗正確,但差距值 <= t,又想讓比較的次數減少,我想到了排序。
產品程式碼演算法實現
產品程式碼:
public bool ContainsNearbyAlmostDuplicate(int[] nums, int k, int t)
{
if (k == 0)
{
return false;
}
var orderByNum = nums.Select((x, index) => Tuple.Create(index, x))
.OrderBy(x => x.Item2).ToList();
var list = new List<int>();
for (int i = 0; i < orderByNum.Count; i++)
{
list.Add(orderByNum[i].Item2);
if (i > 0)
{
//single
var counter = 1;
while ((i - counter) >= 0)
{
var diffValue = (long)list[i] - (long)list[i - counter];
if (diffValue > t)
{
break;
}
var diffIndex = Math.Abs(orderByNum[i].Item1 - orderByNum[i - counter].Item1);
if (diffIndex <= k)
{
return true;
}
counter++;
}
}
}
return false;
}
程式碼摘要說明:
- 因為原本為 int array,在排序的過程中,仍須記錄其原始 index 以便 k 的判斷,這裡透過
Tuple<int, int>來記錄 index 與 num 的值。 - 改用一個 List 來取代原本的 HashSet,這個 List 在 for 迴圈中加入的 num 都是有序的,由小到大排列。以 List 來取其 index 索引子進行比較。
- 當發現目前的 num 與List 中遞減的索引子的值首次 > t 時,代表後面的索引子值差距,肯定都 > t ,就不需要再往後面的值做比較。
- 如果差距值沒有進入 > t 而 break while 迴圈,代表找到符合 t 的值,接著比較兩者的 index 差距是否小於 k。這邊因為已經重新依據值做排序過,所以 index 差距需取絕對值,故使用
Math.Abs()。
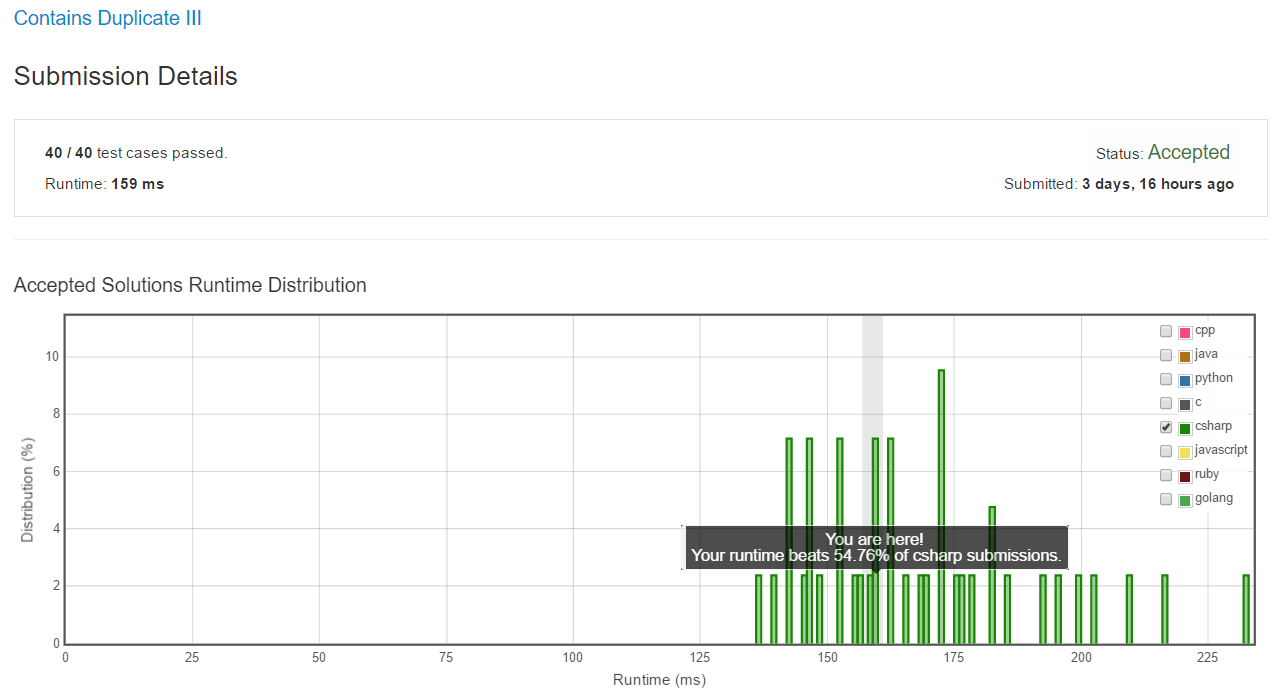
通過 leet code 上 40 個 test cases,包含效能測試。
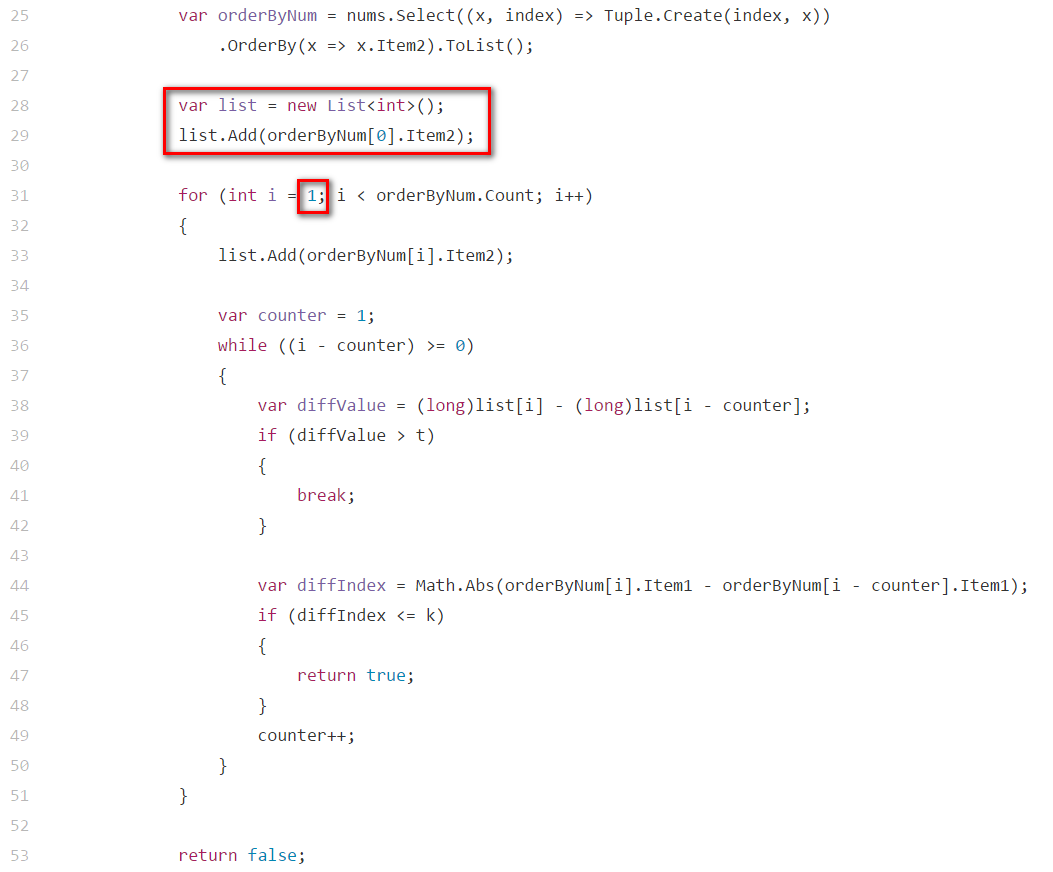
重構程式碼,將 i > 0 的判斷式由迴圈中抽出處理
結論
leet code 最後的瓶頸,果然還是在演算法的效能、資料結構的選擇、型別運算可能溢位的基本觀念。
如果要我選擇產品程式碼的寫法,我可能還是會為了可讀性,而選擇用前面 HashSet + IEqualityComparer 的作法。不過,目前的 while 迴圈也還算清楚,但練習 leet code 就是單純逼出自己搾出效能的極限,挺有趣的!
效能當然還有優化的空間,但可能要手刻 java 的 TreeSet 資料結構會比較有機會一點。
blog 與課程更新內容,請前往新站位置:http://tdd.best/
