摘要:Asp.net - 抓取網頁使用HTML Agility Pack(進階)
這篇是此篇和.Net Regex這篇的綜合進階版,總而言之就是Regex真是學完不常用又忘,
每次要用真是整X趴火,乾脆網路爬文找出這種DOM架構的DLL,自己消化文章完後
再改成我要的進階功能 ! 後來發現用這種方式抓網頁,真的是很方便,特此紀錄分享。
看到這個有人應該就想到可以把這些資料抓進DB中,剛才前面有寫到一篇批入輸入到DB
的文,剛好可以派上用場,這些數據未來就可以拿來製作曲線等各種圖表供分析,如果有
時間希望能補上一個Third Party的物件來將這些數據圖形化。
客官可以上網找HtmlAgilityPack.Dll下載,然後加入參考中
程式如下
Imports HtmlAgilityPack
Protected Sub Page_Load(ByVal sender As Object, ByVal e As System.EventArgs) Handles Me.Load
Dim DT As New DataTable
Dim row As DataRow = Nothing
'下載
Dim client As WebClient = New WebClient()
Dim ms As MemoryStream
'使用預設編碼讀html
Dim doc As HtmlDocument = New HtmlDocument()
'要抓的標的物陣列
Dim Url(0) As String
'鴻海
Url(0) = "https://tw.stock.yahoo.com/q/ts?s=2317"
For Each sUrl As String In Url
ms = New MemoryStream(client.DownloadData(sUrl))
doc.Load(ms, Encoding.Default)
Dim docStockContext As HtmlDocument = New HtmlDocument()
docStockContext.LoadHtml(doc.DocumentNode.SelectSingleNode("/html[1]/body[1]/center[1]/table[3]/tbody[1]/tr[2]/td[1]/table[1]/tbody[1]").InnerHtml)
Dim nodes As HtmlNodeCollection = docStockContext.DocumentNode.SelectNodes("./tr")
Dim columns As HtmlNodeCollection = docStockContext.DocumentNode.SelectNodes("./tr[1]/td")
'抓取表頭
If DT.Columns.Count = 0 Then
For j As Integer = 0 To columns.Count - 1
Dim column0 As New DataColumn(columns.Item(j).InnerText, System.Type.GetType("System.String"))
DT.Columns.Add(column0)
Next
End If
'抓取內容
For i As Integer = 1 To nodes.Count - 1 '第一欄圍欄位Title
row = DT.NewRow()
row(0) = Replace(nodes.Item(i).SelectSingleNode("./td[1]").InnerText.Trim(), " ", "")
row(1) = Replace(nodes.Item(i).SelectSingleNode("./td[2]").InnerText.Trim(), " ", "")
row(2) = nodes.Item(i).SelectSingleNode("./td[3]").InnerText.Trim()
row(3) = nodes.Item(i).SelectSingleNode("./td[4]").InnerText.Trim()
row(4) = nodes.Item(i).SelectSingleNode("./td[5]").InnerText.Trim()
row(5) = nodes.Item(i).SelectSingleNode("./td[6]").InnerText.Trim()
DT.Rows.Add(row)
Next
Next
GridView1.DataSource = DT
GridView1.DataBind()
End Sub
解釋一下這行,以DOM的架構角度來看,就是第一個html下的第一個body下的第一個center下的第三個table..............以此類推。
這樣直覺式的方式去抓取,就比較好理解了。
doc.DocumentNode.SelectSingleNode("/html[1]/body[1]/center[1]/table[3]/tbody[1]/tr[2]/td[1]/table[1]/tbody[1]")
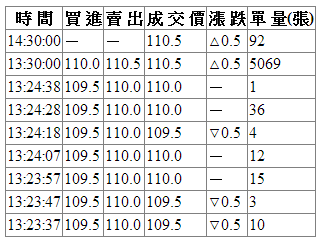
最後GridView顯示畫面如下 ,我用了這方法幫公司抓了一些政府網站上的資訊,以即時讓部門相關單位
得知產品的狀態,已經運行半年有餘,CP值挺高的。