[C#]生產者vs消費者的典型案例(使用TPL來加快速度)
前言
其實要構成一個完整龐大的web網站絕對不是一件簡單的事情,因為你要考慮到db端的效能還有知識,還有C#方面的更龐大的知識,最後還有前端這種怪獸般的演進..

不過持續的以更有效率和更好的方式去完成整個網站,還是我們必須要不斷學習的目標,這篇想來談談什麼叫做是生產者vs消費者,其實我們常常會遇到很多情境,就是把資料庫的東西準備好了,然後丟到一個演算法裡面(生產者),最後算出一個數據之後,再經由我們的呼叫端來轉化成正確存進db的資料(消費者),很多時候我們取出資料的時候,假設有兩仟筆,一筆一筆進演算法算出結果,然後再一筆一筆的轉成正確的格式,其實就會造成速度非常的緩慢。
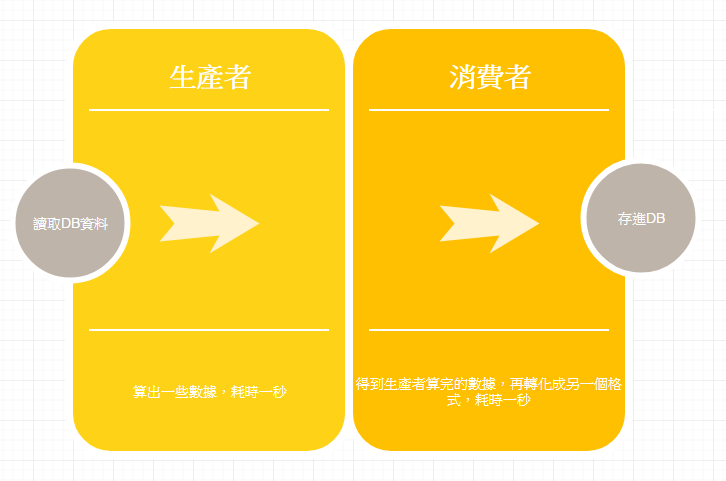
可以想像一下如果我們的生產者需要一秒鐘處理完成,然後消費者也要一秒鐘處理完,才算把這兩仟筆的數據全部處理完,那我們光處理生產者就要兩仟秒再加上消費者處理兩仟秒,總共要就要花掉了四仟秒的時間才能完成這系統的數據核算,是否能有更快的方式來處理這樣子的需求呢?
導覽
現在我要新增兩個方法,一個就叫做是Producer(生者者),一個則是Consumer(消費者),然後來模擬類似的做法,每個處理為免浪費太多時間,處理100毫秒。
void Main()
{
Producer();
Consumer();
}
private static List<int> data = new List<int>(); //共享資料
private static void Producer() //生產者
{
for (int ctr = 0; ctr < 20; ctr++)
{
Thread.Sleep(100);
data.Add(ctr);
}
}
private static void Consumer() //消費者
{
foreach (var item in data)
{
Console.WriteLine(item);
Thread.Sleep(100);
}
}
以目前的範例來說就是完全同步的,所以執行這個任務估計就是要花掉4秒鐘,可以從下圖看到一開始在算數據的時候,大約花了兩秒鐘才開始跑,接著才每100毫秒的一筆一筆顯示出來

接著我們改成TPL的寫法吧,我們希望的是生產者再執行的時候,消費者就能同時的去處理了,也就是類似queue一進一出的概念,而不是全部執行完一整串的任務,才去處理這一整串的任務。
void Main()
{
var producer = Task.Run(() => Producer()); //改成TPL的方式
var consumer = Task.Run(() => Consumer());
}
private static List<int> data = new List<int>(); //共享資料
private static void Producer() //生產者
{
for (int ctr = 0; ctr < 20; ctr++)
{
Thread.Sleep(100);
data.Add(ctr);
}
}
private static void Consumer() //消費者
{
foreach (var item in data)
{
Console.WriteLine(item);
Thread.Sleep(100);
}
}
但是當我們執行的時候,並無法正確的執行,會發生了thread safe的問題,之前有說明過在不同執行緒之間共同操作變數,會導致資料不正確或者是發生expection的狀況,如果我們要保証thread safe的話我們就必須使用lock的方式,但這就很麻煩了,因為當我們同時多個執行緒在跑的時候,我們很難預測到底要lock哪邊才會正確,甚至還能保持我們想要同步的效果。
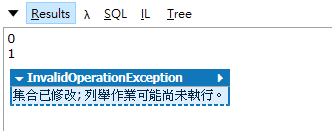
使用BlockingCollection來保證thread safe
接下來就介紹這個阻塞集合的使用來完成我們這次的主題,BlockingCollection可以完全的保證thread safe,而且因為我們跑了兩個Task,所以只要有數據的話,就會馬上去處理掉,裡面GetConsumingEnumerable的命名,根本就可以說是為了消費者而定義的方法。
void Main()
{
var producer = Task.Run(() => Producer()); //改成TPL的方式
var consumer = Task.Run(() => Consumer());
}
private static BlockingCollection<int> data = new BlockingCollection<int>(); //共享資料
private static void Producer() //生產者
{
for (int ctr = 0; ctr < 20; ctr++)
{
Thread.Sleep(100);
data.Add(ctr);
}
}
private static void Consumer() //消費者
{
foreach (var item in data.GetConsumingEnumerable())
{
Console.WriteLine(item);
Thread.Sleep(100);
}
}

各位應該有發現當我馬上執行的時候,就馬上開始跑了,生產者100毫秒處理完,消費者就馬上處理,直到BlockingCollection完全處理完,以這個例子我們原本的四秒就硬是壓縮變成兩秒就處理完畢了。
如果以上述的例子,其實已經算是非常快的了,但如果數量很大,或者我們機器真的夠強的時候,其實還是可以使用Parallel來讓執行效率再加速,不過請注意一下如果執行速度很快就結束了,用這個方式可不一定會更快,而且因為筆者的電腦是雙核心的,所以更強的硬體執行效率都會不一樣,不過在網站這種資料貧乏的狀況下,去隨便大量使用執行緒來處理不一定會是好主意哦。
void Main()
{
var producer = Task.Run(() => Producer()); //改成TPL的方式
var consumer = Task.Run(() => Consumer());
}
private static BlockingCollection<int> data = new BlockingCollection<int>(); //共享資料
private static void Producer() //生產者
{
Parallel.For(0, 20, (ctr) => //這邊改成並行去跑迴圈的方式,而不是傳統的一筆一筆跑
{
Thread.Sleep(100);
data.Add(ctr);
});
}
private static void Consumer() //消費者
{
foreach (var item in data.GetConsumingEnumerable())
{
Console.WriteLine(item);
Thread.Sleep(100);
}
}
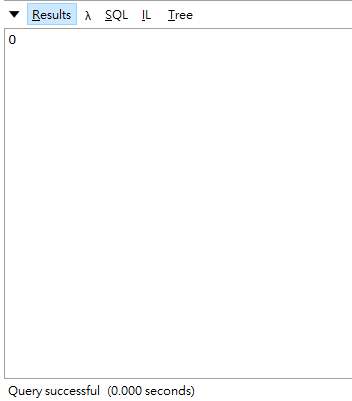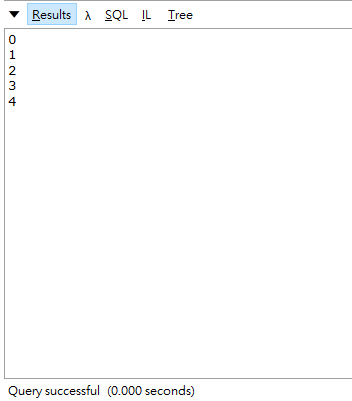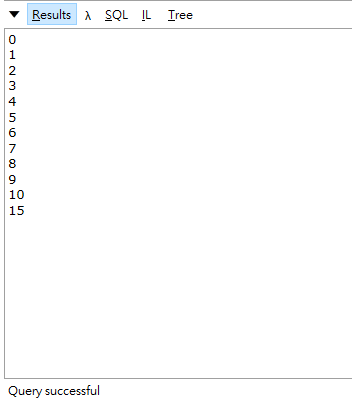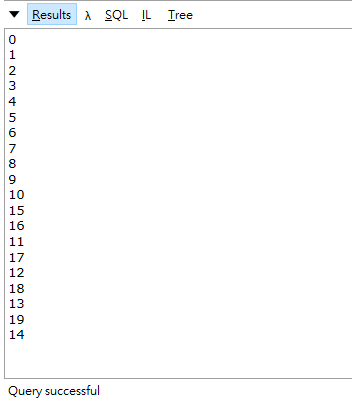
其實我覺得寫程式最重要的還是維護性跟安全性,不過以這種方式來增進效能,卻也保留了維護性,不至於需要自己去注意哪邊要使用lock來處理,也是一種很好的方式,但有時候擠乾所有硬體來讓執行效率加快,也不一定是件好事,我們還是應該要視情況來決定怎麼處理效能上的問題,如果user覺得3秒的速度能接受,我們就不一定需要使用tpl的方式來處理,或者公司願意花更多的預算買進更高級的機器,都會影響我們處理效能上的決策,如果有誤或更好的做法,再請多多指導。
