[Redis]使用opserver來監控redis的狀況
前言
之前有寫過關於opserver的文章,有興趣者可參考(https://dotblogs.com.tw/kinanson/2018/03/07/103038),其實opserver可以監控很多東西,在此就要來研究一下,如何使用opserver監控redis,而且我們如何知道這些監控的數據是什麼意思呢?
為opserver開啟redis的監控功能
其實我們只要在config的資料夾裡面找到RedisSettings.example.json,並且改成RedisSettings.json之後,並加上自己公司相關參數,就能監控redis了,算是挺簡單,example如下
/* Configuration for the Redis dashboard */
{
"Servers": [
{
"name": "172.16.45.34",
"instances": [
{
"name": "DEV-Redis",
"port": 9379
//"password": "superSecret", // Instance has a password
//"useSSL": "true" // Connect via SSL (not built into redis itself - default is false)
}
]
},
{
"name": "172.17.23.89",
"instances": [
{
"name": "qat-redis",
"port": 9379
//"password": "superSecret", // Instance has a password
//"useSSL": "true" // Connect via SSL (not built into redis itself - default is false)
}
]
}
]
}
為了方便展示,筆者使用的是公司的測試環境來做展示,當我們完成設定,並開啟畫面之後,就會看到如圖示例

我們點進去可以看到更詳細的訊息,筆者就做個筆記來寫一下我認知上監控的數據
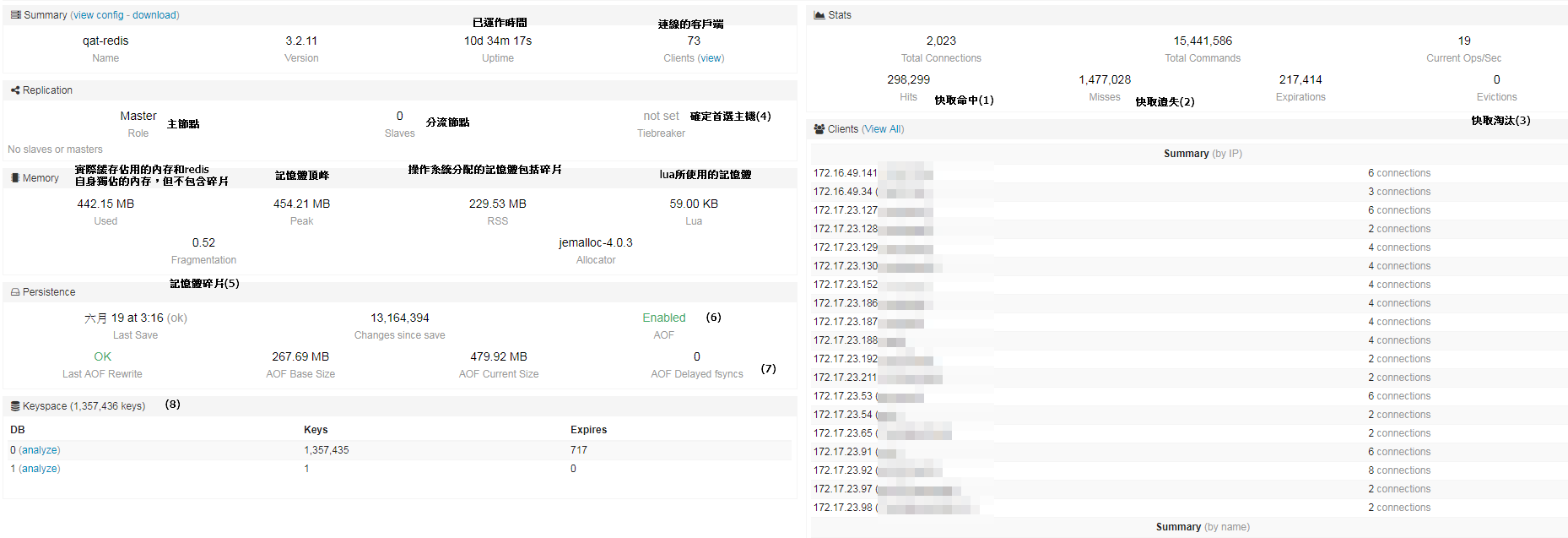
圖中有標記數字的說明如下
(1)Hits-快取命中:
所指定報告間隔期間的成功金鑰查閱數目
(2)Misses-快取錯失:
所指定報告間隔期間的失敗金鑰查閱數目。 快取遺漏不一定表示快取發生問題。 例如,使用另行快取程式設計模式時,應用程式會先在快取中尋找項目。 如果項目不存在 (快取遺漏),項目會從資料庫中擷取,並在下次新增至快取中。 快取遺漏是另行快取程式設計模式的正常行為。 如果快取遺漏數目高於預期,請檢查可填入且讀取自快取的應用程式邏輯。 如果因記憶體壓力而正在收回快取中的項目,則可能會有一些快取遺漏,但監視記憶體壓力的較佳度量是 Used Memory 或 Evicted Keys
(3)Evictions-快取淘汰:
可以設定maxmemory和選擇memory-policy的規則,規則有以下幾種選項
(4) Tiebreaker -確定首選主機:
通常 StackExchange.Redis 都會自動解析 主/從節點。然而如果你不使用諸如redis-sentinel 或redis 集群之類的管理工具,有時你會有多個主節點(例如,在重置節點以進行維護時,它可能會作為主節點重新顯示在網絡上)。為了幫助解決這個問題,StackExchange.Redis 可以使用 tie-breaker 的概念 - 這僅在檢測到多個主節點時使用(不包括需要多個主節點的redis集群)。為了與 BookSleeve 兼容,tiebreaker 使用默認的key為 "__Booksleeve_TieBreak" (總是在數據庫0中)。這用作粗略的投票機制,以幫助確定首選主機,以便能夠按正確的路由工作。
(5)Fragmentaion-記憶體碎片:
(6)AOF:
AOF 持久化記錄服務器執行的所有寫操作命令,並在服務器啟動時,通過重新執行這些命令來還原數據集。 AOF 文件中的命令全部以 Redis 協議的格式來保存,新命令會被追加到文件的末尾。
使用 AOF 持久化會讓 Redis 變得非常耐久,你可以設置不同的 fsync 策略,比如無 fsync ,每秒鐘一次 fsync ,或者每次執行寫入命令時 fsync 。 AOF 的默認策略為每秒鐘 fsync 一次,在這種配置下,Redis 仍然可以保持良好的性能,並且就算發生故障停機,也最多只會丟失一秒鐘的數據。
(7)AOF Delayed fsyncs:
當要執行sync備份時,如果之前的sync未結束,就delay的總數量
(8)Keyspace:
可以針對資料庫的鍵和值有影響的操作事件發出pub,或者延遲時間發出pub,2.8.0後推出的redis功能。
上述如有錯誤,再請糾正筆者哦。
