在資料庫設計上,PK (主鍵) 一直都是設計的重點之一,但主鍵使用的資料型態有可能直接或間接影響到資料庫的存取效能,然而技術是會演進的,30年前可能不行的作法在30年後的今天是否仍然不適用? 似乎有待商榷。
主鍵 (Primary Key) 在資料庫設計中一直都是重要的因子,它具有唯一性 (unique),與其他資料表鍵值的連結 (Foreign Key, FK),達成邏輯上的參考完整性 (Referential Integrity),有助於消除重覆性資料以及提升資料的可維護性,然而在實務上,參考完整性愈強的資料庫,在異動鍵值的運算 (最常見的是新增資料與刪除資料) 會觸發對參考目標的資料表的鍵值比對運算,會增加些許的比對損耗。不過,雖然鍵值在資料庫設計中很重要,但實際上資料庫在運作時,主鍵和外來鍵組成的參考完整性運算,使用的是索引 (index),索引連結到資料儲存的位址,一個資料庫如果沒有任何索引的話,存取資料的速度會慢到超乎想像,所以資料庫內一定要有索引,否則每次的 SQL 指令運算都要去掃一次資料表所有資料,光是掃瞄資料的 I/O 速度就足以讓人哭出來了。
資料庫索引概念
索引是一種資料庫物件,它會以設定的條件在資料庫的儲存區域內建立一個搜尋樹 (Search Tree),資料庫所使用的搜尋樹主流是 B+-tree,是一種在新增、刪除節點時會執行自我平衡 (self-balanced) 的搜尋樹,與 B-tree 的差異是它在子葉節點中亦存有指向鄰近子葉節點的指標,可快速執行掃瞄作業 (Index Scan),同時亦保有搜尋樹的搜尋能力 (Index Seek)。
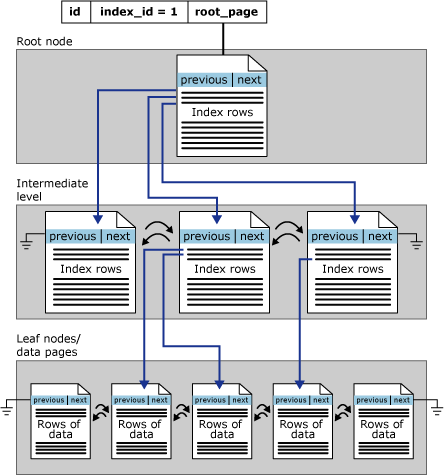
另外,在 SQL Server (其他的 DBMS 也類似) 內的索引分為 Clustered Index 以及 Nonclustered Index,這兩者的差異在於 Clustered Index 在生成時就會依照指定鍵值進行排序 (節點內會包含該鍵值),Nonclustered Index 則只是組織資料列位址到節點內而己,但若 Clustered Index 和 Nonclustered Index 同時存在時,Nonclustered Index 的節點會指向 Clustered Index 所指定的順序,若 Clustered Index 不存在時則會僅會指向資料列的位址。想當然,當任何索引都不存在時,資料列位址僅會存在於資料儲存的邏輯結構內。
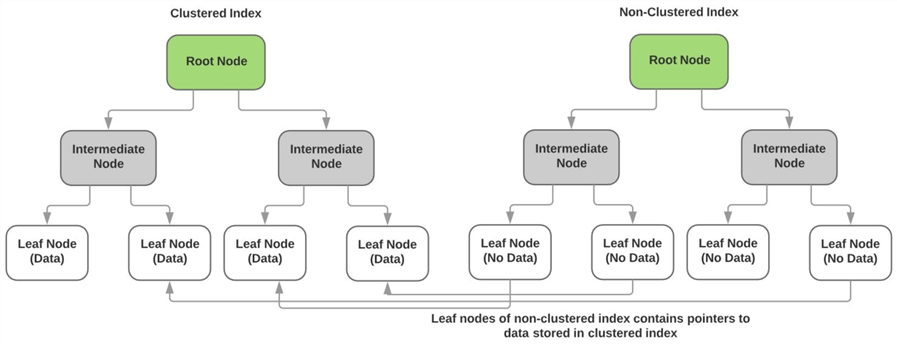
SQL Server 預設會將 PK 設置為 Clustered Index,因 Clustered Index 會自動形成有序資料 (Ordered Data),使得許多涉及排序作業的運算都會使用到 Clustered Index (其實較廣泛的運算就是範圍查詢,例如日期區間或值域等),可想見沒有 Clustered Index 會對效能的傷害有多大 (因為都要先掃瞄再排序,而不是直接取一個已排序的資料集,在沒有 Clustered Index 的時候會導致 Table Scan)。
索引與資料型態的選用
前面提到 Clustered Index 會形成有序資料,在不影響 B+ tree 插入資料時期排序的速度下,以可自動形成順序的資料最為有利,因此很多人都會使用 int, bigint 這類具有快速判斷順序的資料型態作為 Clustered Index 的材料,除了有序性外,另一種影響到索引新增速度的的因素就是資料長度,在新增資料時若節點可用空間不足以置放新增的資料時,會產生頁分裂 (Page Split) 的效應,因此若作為索引的資料型態太長的話,發生索引分裂的機率會較高,另外空間不足的分頁也無法存放資料,空間碎裂 (Fragment) 的情況會較嚴重,也就是分頁內的可以空間可能會有一定比例是沒使用到的。
索引的空間碎裂問題可以用重建索引的方式解決,但頁分裂會使得 I/O 次數增加,影響索引新增節點的速度,不過若資料庫所在的磁碟是具有高速 I/O 能力的磁碟,這點效能損耗或許還可以忽略,只是若是很要求時間的應用程式就一定要正視這個問題。
GUID於主鍵與索引的使用
GUID / UUID 是一種唯一性很強的資料形態,依照 GUID 的演算法,想要得到重覆的 GUID,得要在85年的時間內每秒都產10憶個GUID才可能會發生重覆,或是剛好電腦環境有問題才有可能出現,所以 GUID 通常拿來當需要很強唯一性的識別資料之用。那麼 GUID 是否能做為主鍵? 答案幾乎是肯定的,因為要作為 PK 的鍵值本身就要有很強的唯一性,所以 GUID 的特性相當符合 PK 的要求,若使用 int, bigint 等型態作為 PK 的話,可能還需要自行編寫演算法處理重覆問題,不過 GUID 的生成方式可能會有些許影響,尤其是跨不同類型資料庫 (如混合 SQL Server, MySQL 等 DBMS 的環境),相同的 API 無法直接運用。
會決定 GUID 適用與否的其實不是 PK/FK,而是索引。
前面有提到 Clustered Index 是有序的資料,但 GUID 一般都是採用隨機亂數方式產生 (也就是 version 4 的 GUID 演算法),當然也有資料庫實作有序的 GUID (例如 SQL Server 的 Sequential ID),隨機亂數產生的 GUID 不利於 Clustered Index 的處理,尤其是新增資料時的排序作業,會增加 I/O 的次數。不過這個問題只發生在 Clustered Index 上,若是使用到 Nonclustered Index 則沒有這個問題。
因此要避過 GUID 用於 Clustered Index 的問題,使用代理鍵 (Surrogate Key) 是個不錯的作法,使用一個可判斷排序的資料型態作為 Clustered Index,然後將 GUID 的欄位設為 Nonclustered Index,此時 Nonclustered Index 會指向 Clustered Index,可降低因為排序作業導致的效能損耗,不過新增作業上的 I/O 則會略增,不過若不是非常頻繁的新增資料,新增作業的 I/O 倒是可以忽略不看,除非很計較新增資料的 I/O 速度。
參考1:https://www.slideshare.net/yftzeng/btreepart-1
參考2:https://blog.darkthread.net/blog/guid-as-pk-on-db/
參考3:https://docs.microsoft.com/zh-tw/sql/relational-databases/indexes/clustered-and-nonclustered-indexes-described?view=sql-server-ver15