ORM 很努力的幫你抽象化了資料存取的工作,但它並不會減少或免除你應該學習 SQL 的時間與必要性。
每次過一段時間,都會看到類似這樣子的觀點:
只要學 ORM 就好了,不需要學習 SQL 或不需要學習與資料庫相關的東西,ORM 都會幫你解決查詢的工作。
這類觀點我個人將它稱為 ORM 至上,彷彿 ORM 是一帖萬靈丹,用了它什麼事都能解決而且不會有任何副作用,然後就會看到類似這樣的問題:
EF (或其他 ORM) 適合百萬筆資料 (或億筆) 以上等級的資料庫嗎?
平常沒事看到笑笑也就算了,但我發現有些人是認真的,既然如此,那麼我也來認真的闡述為什麼不能 ORM 至上,也就是說就算有了 ORM 你還是必須且應該要好好學 SQL。
抽象滲漏法則
這篇我覺得是每個開發人員都應該要讀的文章之一,因為只要是使用任何有封裝或使用函數庫 (library)、類別庫 (class library)、元件 (component) 的程式語言,基本上都一定會將函數庫所封裝的概念以抽象 (abstraction) 的型式提供,使用函數庫的開發人員可以在完全不用理解該技術或方法的情況下,以有限的能力 (函式庫的 API) 使用該函式的功能,一切看起來都是那麼的美好,然而,約耳 (Joel Spolsky) 認為這樣其實是有潛在風險的,因為即便是封裝精良的函數庫,仍然會有它無法隱藏的東西,或是在某些情境下,抽象的封裝力無法解決該情境所面臨的問題,導致使用函數庫的開發人員仍然要深入到該函數庫所封裝的技術或領域內,才能調查、處理與解決該情境下所發生的問題,因此約耳認為:
All non-trivial abstractions, to some degree, are leaky. (在某些情況下,所有重要的抽象都是有漏洞的)
而且約耳剛好也用 ASP.NET 來舉例:
在教ASP.NET程式設計時,最好只要教學生可以在元件上雙擊,然後就能撰寫使用者點擊該元件時在伺服器執行的程式。不過處理超連結(<a>)點擊事件的HTML程式,和某個按鈕被按時的處理程式是不一樣的,而ASP.NET實際上是把這之間的差異抽象化了。問題來了,ASP.NET的設計者必須把HTML無法由超連結傳送表格的事實隱藏起來。他們的做法是在超連結的onclick產理加上幾行JavaScript程式。不過這種抽象機制也有漏洞,如果使用者關閉JavaScript功能,ASP.NET的應用程式就不能正常的運作了,萬一程式師又不瞭解ASP.NET抽象掉什麼東西,根本不可能知道出了什麼問題。
因此,即便函數庫有封裝了技術或方法,也無法免除該技術或方法應有的學習成本與時間,因為若開發人員不了解它的技術背景知識 (也就是它抽象了什麼),當函數庫在某種情況發生問題時,仍然要回到該函數所封裝的技術方法來嘗試解決問題。
ORM 抽象了什麼?
ORM 顧名思義,Object-Relatonal Mapping,它是一種可以將物件與關聯進行對應的技術,所謂的物件是指 OOP 中所產生的類別、結構等可容納資料的實體,而關聯雖然可以指其他東西,但一般泛指關聯式資料庫 (Relational Database),而關聯式資料庫的主要操作語言是 SQL,在各類程式語言中大多數都會實作與資料庫相關的用戶端函式庫 (Database Client Library),以該程式語言開發者認為適合的角度 (如OOP),提供應用程式存取資料庫的方法,而應用程式就是運用它來與資料庫做資料交換與下指令,而其中的媒介就是 SQL。
因此我們可以說,ORM 將 SQL 以及用戶端函式庫所提供的方法或 API 隱藏起來,在它們之上提供抽象化的方法,讓開發人員得以在不接觸 (傷害幼小心靈?) SQL 與用戶端函式庫的情況下就能存取資料,一切看起來都是那麼美好,此時我可以將它的結構以圖示的方式畫成這樣:
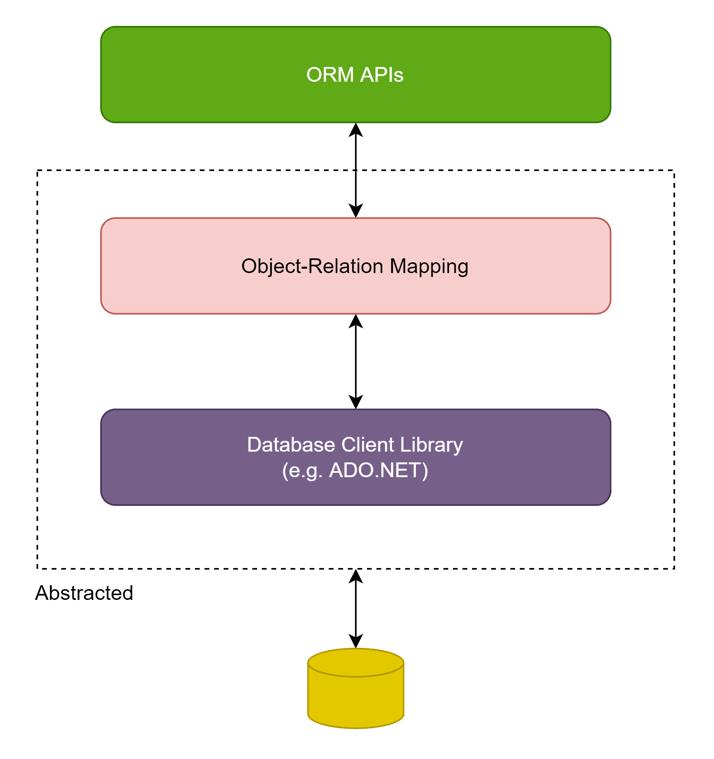
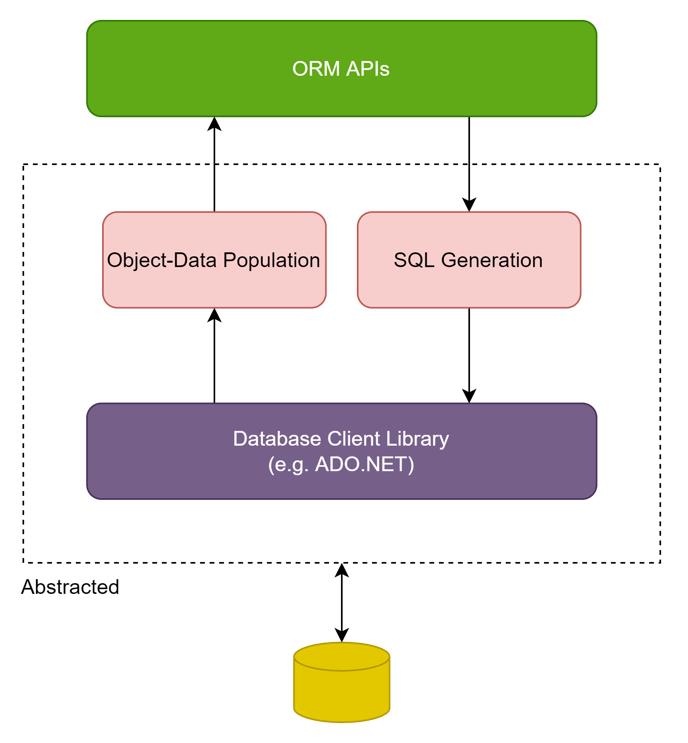
整個 ORM 的核心在於 Object-Relational Mapping,當上層 API 查詢資料庫時,ORM 必須要將 API 呼叫轉換成 SQL 指令,而在結果回傳時,ORM 必須要將 Database Client Library 傳回的結構轉換回物件結構,才能夠回傳給上層的呼叫者,因此我們可以將中間的 Object-Relational Mapping 再分割出來,對資料庫呼叫會有 SQL Generation (產生 SQL 指令) 的功能,而對資料庫回傳則是 Object-Data Population (物件資料填入),藉以達成 ORM 所應該具備的功能。
ORM 滲漏了什麼?
一切都是那麼的美好,直到那件事發生了。
ORM 的 Object-Relational Mapping 功能試著要把資料存取 (SQL) 與物件填入 (Object Data Population) 抽象化,讓開發人員得以直接運用 ORM API 存取資料庫,然而當發生幾種情況的時候,ORM 的抽象化就會發生滲漏,而且情況還不少,諸如:
- 當物件結構複雜,且想試圖與資料庫對應時,
- 開發人員缺乏相關知識,導致寫出的 ORM API 產生的 SQL 指令效能低落時。
- 當資料庫內資料型態無法 (或需要特別處理) 與 ORM API 提供的資料型態對應時。
- 需要精細控制資料存取相關設定 (e.g. Command Timeout) 時。
- ORM API 不支援的資料庫查詢功能。
- 需要精細控制資料存取 (SQL 的下法) 時。
- 當由資料庫還原回物件 (Object Data Population) 時,發現效能低落。
這些情境都是 ORM API 抽象的部份所封裝的處理行為,因此一旦這些情境發生時,開發人員就必須要想辦法由 ORM API 所隱藏的背後技術機制去找出可能的問題,若這時又缺乏相關知識時,想要找出問題更是困難重重。
其中的原因,在於 SQL Generation 和 Object Data Population 這兩個作業本身就不是容易的事,尤其是要支援多種資料庫的 ORM,實作 SQL Generation 的開發人員要對該資料庫的 SQL 與技術細節要有深入的了解,才能寫出效能較佳的 SQL Generation Code,我在之前寫的 ORM 實作文章中就提及:
ORM 本身不會因為它看起來像物件就可當沒有 SQL 這回事,當物件存取和關聯愈來愈複雜的時候,Object 和 SQL 之間的互動複雜度就會成等比級數一樣。
簡單的 C/U/D 或許還可以,但是 R (Query) 可就沒那麼簡單了,資料庫的關聯性要轉換成物件模型,在設計時期就已經有一定難度,何況是在實作時期,要如何將 Navigation Property 轉換為 LEFT JOIN 或 INNER JOIN,在在考驗著 SQL Generation 的開發者,再加上有些可能還要運用其他特定的 DBMS 函數或是特定的語法結構才能處理,更加深了 SQL Generation 的開發複雜度。

而在 Object Data Population 部份,雖然沒有像 SQL Generation Code 那麼複雜,但仍然要處理 Resultset 對應到 Object Graph 的問題,以及是否要使用 Reflection 或者是用 Dynamic Type 的問題,或是遇到資料庫的使用者定義型態 (UDT) 或特別型態的處理,有寫過 Reflection 的開發者都知道,Reflection 是很耗效能的,Dynamic Type 或許可在 Design Time 解決一部份,但在 Runtime 時仍然會有對應的效能損耗。是否要追踪物件變更狀態也是個問題,若沒有追踪的話 ORM 就無法長出 UPDATE 的 SQL 指令與無法確認物件是否已被刪除等等,但追踪物件狀態又會吃一點點效能。

ORM 在不分頁的 SQL 表現會更慘,假設用 ORM 回傳一百萬筆資料,每筆資料要花 1ms 來做 Object Population,那整個回傳至少也要 1000 秒的時間,相信沒有任何一個人能接受這樣的速度。
結論
在這篇文章中,討論了幾個議題:
- ORM API 試著將 SQL 與資料存取行為抽象化。
- 當特定情境發生時,ORM API 會發生抽象滲漏,導致開發人員要深入被抽象化的行為中找出並解決問題。
- SQL Generation 的機制
- Object Data Population 的機制
其實講這麼多,結論只有一個:不要相信 ORM 至上論,ORM 確實是現代程式語言中幫助開發人員簡化資料庫存取的一個重要技術,但它並沒有能力將所有的情境都抽象化到 ORM API 中,而當它無法處理的情況發生時,ORM 的抽象會失效,這時還是要回到根本的 SQL 去解決問題,而這也是為什麼主流的 ORM 要保留可允許開發人員自行撰寫 SQL 的功能的原因。
套用抽象滲漏法則的話就是:
ORM 很努力的幫你抽象化了資料存取的工作,但它並不會減少或免除你應該學習 SQL 的時間與必要性。
參考資料:
The Law of Leaky Abstractions – Joel on Software
Joel on Software - The Law of Leaky Abstractions (ntu.edu.tw)