網友問題:DISTINCT 使用疑問
'AAA'.'AAA '明明兩筆資料不同,為什麼SQL Server卻認為是相同資料呢?
今天看到一個有趣的問題,明明兩筆不同的資料,使用distinct或group by結果卻只有一筆,要怎麼解決該問題呢?
由於SQL Server是遵守 ANSI/ISO SQL-92 規範,除了Like unicode([SQL SERVER][Memo]LIKE statement)以外,
大部分字串尾端空白進行比較都會自動忽略,了解這行為後,該問題就容易解決了。
declare @T table (FS varchar(50))
INSERT INTO @T VALUES('AAA')
INSERT INTO @T VALUES('AAA ')
select * from @T
select distinct * from @T
select FS from @T GROUP BY FS
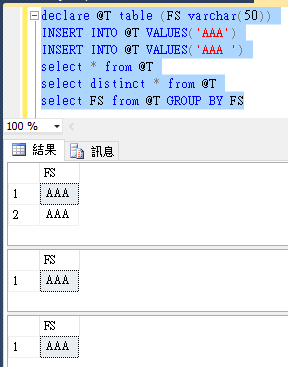 可以看到 'AAA'和'AAA '被視為相同字串。
可以看到 'AAA'和'AAA '被視為相同字串。
再用一個例子驗證SQL Server比較字串是遵守 ANSI/ISO SQL-92 規範
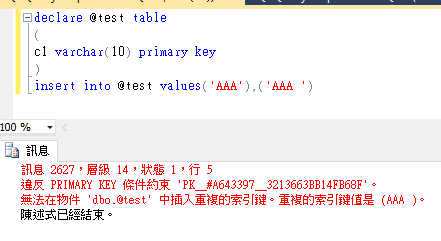 明明兩筆不同的資料,但SQL SERVER卻出現PK錯誤(值重複)。
明明兩筆不同的資料,但SQL SERVER卻出現PK錯誤(值重複)。
回到網友問題,如何讓SQL SERVER顯示正確資料(兩筆)呢?很簡單,使用DATALENGTH就可以
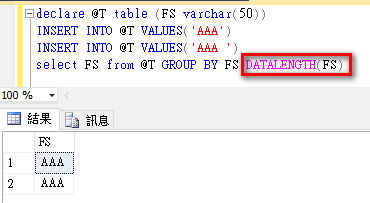
參考
INF: How SQL Server Compares Strings with Trailing Spaces
Eliminating Duplicates with DISTINCT
SET ANSI_PADDING (Transact-SQL)