平行處理提高Insert效能。
SQL Server 2016針對select .. into. With(TABLOCK)完全採用平行新增(parallel insert),
這消息相信對有在執行ETL作業的DBA或開發人員算一大福音。
在SQL Server 2014資料如要新增至Columnstore index,
基本上只會使用單一執行緒來處理,大概過程就是直到row group填滿後在換下一個row group,
所以導致資料表含有Columstore Index,不論查詢計畫有多棒,資料新增往往是最慢的。

SQL2014
在SQL Server 2016且資料庫層級為130,使用select .. into. With(TABLOCK)預
設將使用平行處理,我們將使用每一個CPU核心來接收資料並分割Delta-Store。
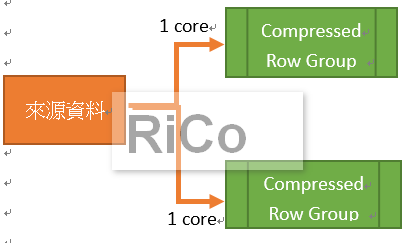
現在我就來簡單測試TABLOCK對新增效能的差異
CREATE TABLE [dbo].[testDatetime_CCI](
id INT NOT NULL,
sdatetime DATETIME NOT NULL,
edatetime DATETIME NOT NULL,
sdate date not null,
content VARCHAR(300) NOT NULL,
INDEX PK_testDatetime_CCI CLUSTERED COLUMNSTORE
);
insert into [testDatetime_CCI]
select top 2000000 id,sdatetime,edatetime,sdate,content
from testDatetime option (recompile)
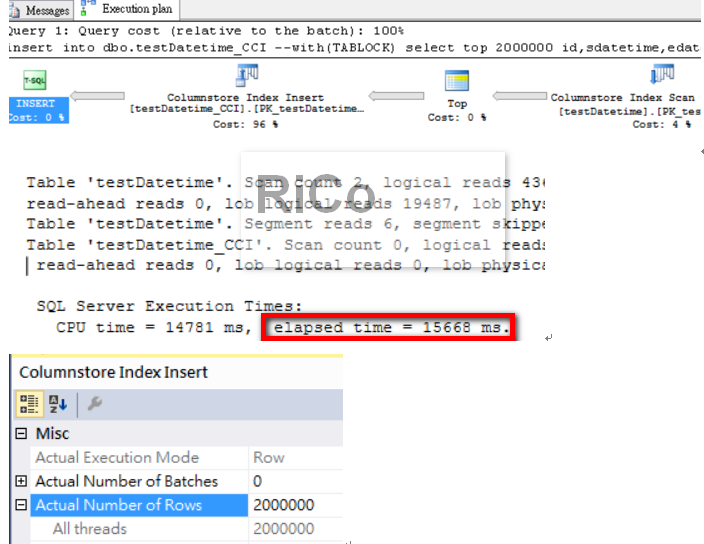 新增二百萬筆約耗費15秒,透過執行計畫可以看到只使用一條執行緒新增。
新增二百萬筆約耗費15秒,透過執行計畫可以看到只使用一條執行緒新增。
查看Row Group
select *
from sys.column_store_row_groups
where object_schema_name(object_id) + '.' + object_name(object_id) = 'dbo.testDatetime_CCI'
order by row_group_id asc;
使用TABLOCK新增
truncate table [testDatetime_CCI]
insert into dbo.testDatetime_CCI with(TABLOCK)
select top 2000000 id,sdatetime,edatetime,sdate,content
from testDatetime option (recompile)
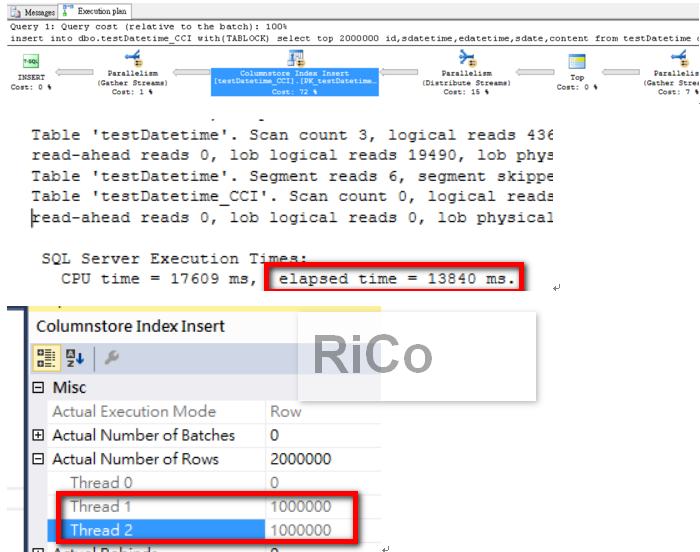 使用TABLOCK快了2秒鐘,因為我VM的CPU只有2 core,
使用TABLOCK快了2秒鐘,因為我VM的CPU只有2 core,
所以這裡可以看到使用兩條執行緒平行新增(CPU core數量越多,耗用時間越少)。
查看row group
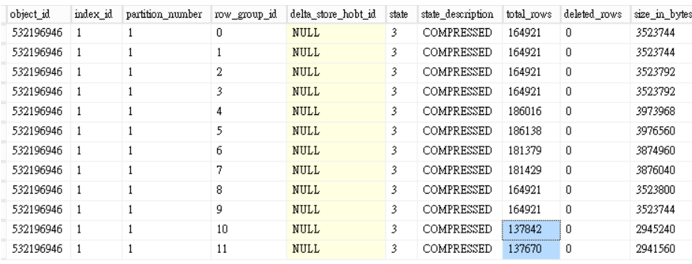
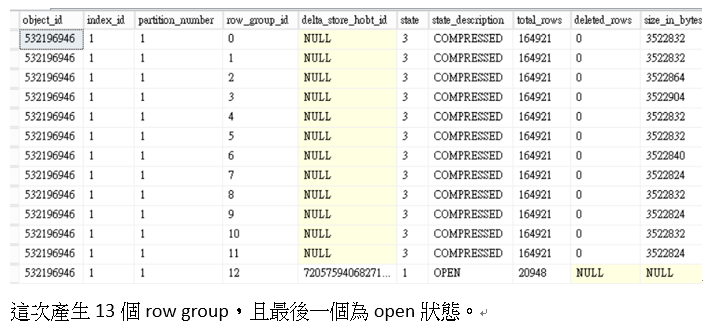
這次可以看到只產生12個row group,且最後兩個資料平均分散(因為我們使用兩條執行緒)
,並且所有狀態都為壓縮,
我們再透過sys.dm_db_column_store_row_group_physical_stats確認最後兩個row group trim原因為BULKLOAD。
select *
from sys.dm_db_column_store_row_group_physical_stats
where object_schema_name(object_id) + '.' + object_name(object_id) = 'dbo.testDatetime_CCI'
order by generation;
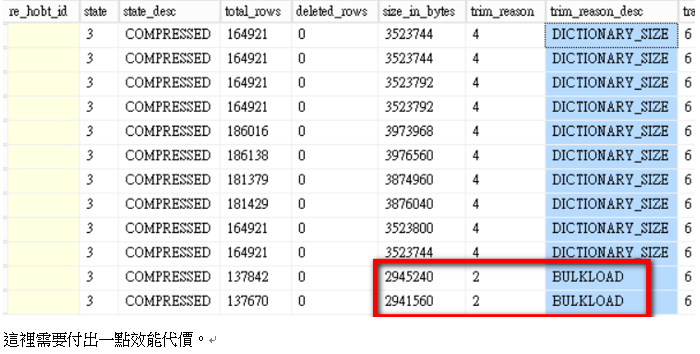
BULKLOAD,表示資料載入Compressed rowgroup,會紀錄最少內容。但載入delta rowgroup(差異資料列群組)就不會最小化紀錄(Log)
Nonclustered Columnstore測試
CREATE TABLE [dbo].[testDatetime_NCCI](
id INT NOT NULL,
sdatetime DATETIME NOT NULL,
edatetime DATETIME NOT NULL,
sdate date not null,
content VARCHAR(300) NOT NULL,
INDEX IDX_testDatetime_NCCI Nonclustered Columnstore (id,sdatetime,edatetime,sdate,content)
);
insert into dbo.[testDatetime_NCCI] with(TABLOCK)
select top 2000000 id,sdatetime,edatetime,sdate,content
from testDatetime option (recompile)
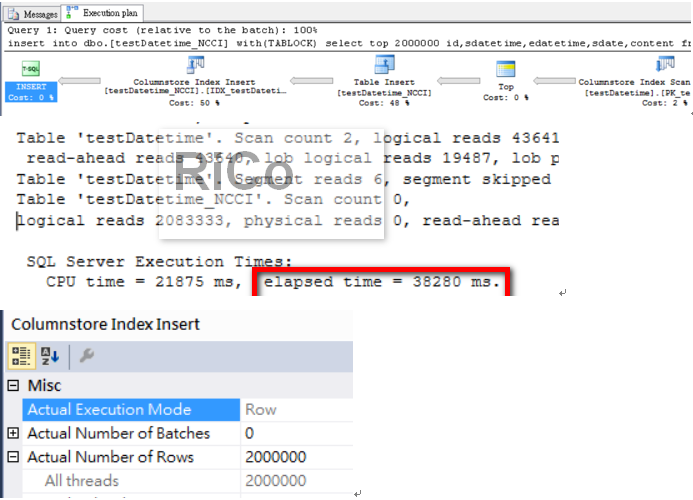 可以看到可更新的Nonclustered Columnstore並無法使用TABLOCK平行新增,
可以看到可更新的Nonclustered Columnstore並無法使用TABLOCK平行新增,
二百萬筆資料整整花費38秒才完成。
查看row group
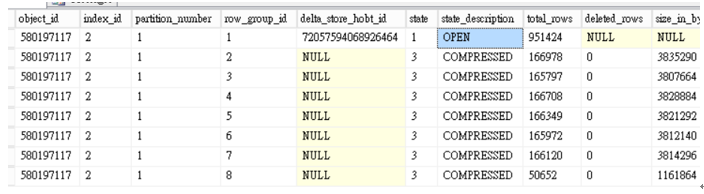 Note:InMemory資料表並無法支援TABLOCK
Note:InMemory資料表並無法支援TABLOCK
Enjoy SQL Server 2016
參考
Columnstore Indexes Data Loading
Columnstore Index: Scan and parallelism
Data Loading performance considerations with Clustered Columnstore indexes