以前我總認為SQL engine會完整接收並執行sqlcommand,不應該發生截斷問題,
直到xml_deadlock_report讓我知道原來有例外。
前幾天我在公司分享,SQL Server交易主要技巧時,當時我正在介紹如何閱讀xml_deadlock_report並分析deadlock主因,
這時有同事詢問,inputbuf的sqlcommand是否會被截斷,我當下的答案是"不會",
因為我以前透過 dm_exec_sql_text 找相關sqlcommand也從沒有截斷問題,
但偏偏在xml_deadlock_report卻有長度限制,特用此篇加強印象,並修正為 1024長度限制。
模擬發生deadlock
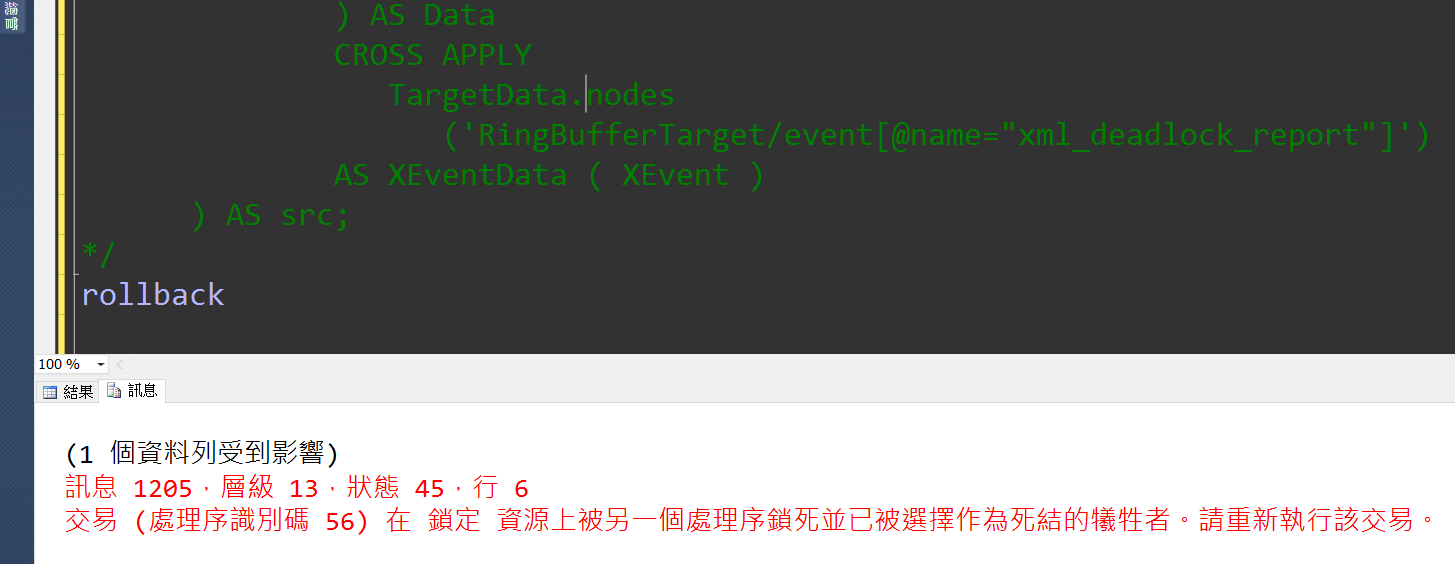
但xml_deadlock_report中的inputbuf卻發生截斷sqlcommand

存在1024限制原因如下(from Microsoft)
The same SQL engine code has generated both of these deadlock graphs. It is the exact same event, however, in the “working case”, it was channeled trough event notifications and then through the WMI event provider. There is a hardcoded limit of 1024 characters when generating sql-handle and input-buffer text for deadlocks and this limitation is not new (since the features were introduced). If you actually count the characters in the "working case" you'll find out that they are exactly 1024. One caveat is that proc names, sql-handles and input-buffers are generated on separate threads (deferred) because the generation of this information requires taking locks and the Deadlock Monitor thread cannot acquire locks because of potential deadlock participation. So, the difference between these two examples is simply result of a chance. In one case the sql-handle was in memory and in the other it was not. In the "broken case”, the sql-handle happened to be evicted from the cache which prevented proper dumping of the sql-handle. The input buffer was still dumped, but unfortunately the statement in question was beyond the supported 1024 characters. So, I would suggest trying to reproduce the deadlock a few more times until the sqlhandle gets populated or maybe figuring out the statement text by just using the provided statement offsets.
Basically, we can increase the hardcoded limit to something bigger, but then the question is by how much. Don’t having any limit would be impractical. If the events become too big, several other things may get affected:
1. Extended events may get dropped (due to limited event session buffer size). A workaround might be to recreate the event session with a larger buffer and try to reproduce the deadlock.
2. SQL Trace events may get dropped (especially when using rowset trace – Profiler – the in-memory buffer is not very big)
3. The system_health event session which happens to capture deadlock events may get flooded. The files rollover once the max size is reached and older files get deleted.
4. Internal (SSMS, Profiler) or 3-rd party tools may stop rendering the deadlock graphs properly -> this is hypothetical, but it is a valid concern.
5. Possibly hitting other thresholds/limitations in the system (max limit of a WMI event size, max event notification size, etc.) which can cause loss of events in other places.
So, I would like to push back on this request and keep the current hardcoded limits as they are.
參考
SQL Command is Truncated on Deadlock Graph