Columnstore indexes主要可以改善大量scan/aggregate操作(可達10倍),
因為採用xVelocity壓縮儲存方式(但無法對in-memory table壓縮),
可大大節省disk space(壓縮大約10倍以上,取決於資料表中所有資料型別),
所以和傳統row存放方式不同,通常會在fact table上建立來改善Data Mart/Data Warehouse彙熜效能。
唯一可在In-Memory table(schema_only並不支援)上,建立clustered index就只有clustered columnstore,
之前我在SQL2016測試建立相當耗時緩慢(耗用大量交易紀錄),該問題還好在SP1得到改善,
我整理以下幾點和disk table差異,使用上請依需求自行服用。
先釐清clustered columnstore index和一般clustered index主要差異
1 clustered index key都會附加所有的nonclustered index,
但clustered columnstore沒有key,所以內部自然不存在該特性。
2clustered index等同資料表,並維護資料的邏輯排序(實體資料排序並不保證),
但columnstore的資料都是沒有排序的(無論clustered or nonclustered)。
接下來,我們來比較和disk table的差異
1不支援計算資料行
SQL2017開始,disk table的clustered columnstore開始支援非保存計算資料行,
但In-Memory table的clustered columnstore還是不支援計算資料行,
雖然SQL2017的In-Memory table已經支援非保存計算資料行。
2無法建立nonclustered columnstore
disk table可以建立第二個nonclustered columnstore,來降低相等(point)和範圍(range)查閱(Lookup)對系統效能影響,
同時也可以建立filter index改善查詢效能,但In-Memory 只能建立clustered columnstore index,
也無法支援filter index,同時你也無法透過alter table增加nonclustered index。
alter table columnstoreMem
add index idx1 (c3)
 3索引維護作業
3索引維護作業
Disk table我都會判斷clustered columnstore是否要rebuild(大部分無須rebuild)或reorganize,
但在in-memory table並不支援reorganize,只支援rebuild用在hash index的bucket_count。
4 Columnstore archive
Disk table我們可以額外使用Columnstore archive來舒緩硬碟空間,
但In-Memory table並不支援,你只有columnstore唯一選項。
5 Native compiled sp無法支援(平行處理)
In-memory table建立clustered columnstore後,查詢clustered columnstore基本上會使用平行處理來提高效能(只有interop TSQL),
但Native compiled sp並無法平行使用clustered columnstore,disk table+old sp卻沒有這樣的煩惱。
create table columnstoreMem
(
c1 int not null
,c2 int not null
,c3 varchar(30)
,c4 datetime
,c5 money
,constraint PK_columnstoreMem primary key nonclustered(c1,c2)
)
with(memory_optimized=on,durability=schema_and_data)
alter table columnstoreMem
add index Memory_CCI clustered columnstore
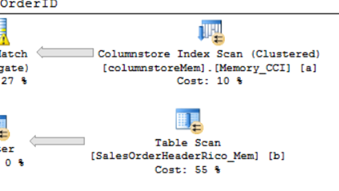
select sum(c5),max(c4) from columnstoreMem a join SalesOrderHeaderRico_Mem b on a.c1=b.SalesOrderID
create proc usp_GetSumNative
with native_compilation ,schemabinding,execute as owner
as
begin atomic
with(transaction isolation level=snapshot, language='english')
select sum(c5),max(c4) from dbo.columnstoreMem a join dbo.SalesOrderHeaderRico_Mem b
on a.c1=b.SalesOrderID
end
SET SHOWPLAN_XML ON
GO
exec dbo.usp_GetSumNative
GO
SET SHOWPLAN_XML OFF
GO
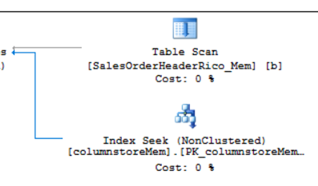 不管我執行多少次,native compiled sp彙總查詢效能,都無法快過interop TSQL,
不管我執行多少次,native compiled sp彙總查詢效能,都無法快過interop TSQL,
兩者相差45%左右(904 ms vs 1690 ms)。
6 Schema變為Read-Only
Disk table新增clustered columnstore後,我們依然可以透過alter table來修改columnstore index或table layout,
但在In-memory table就會變成read-only(依然可以執行DML)。
alter table columnstoreMem add c6 int null;
![]() 7 LOB data不支援
7 LOB data不支援
SQL2016 的Disk table和In-memory table的clustered columnstore都無法支援LOB資料類型,
但SQL2017的disk table已經開始支援。
c3 varchar(max)
 8 columnstore indexes會儲存在disk
8 columnstore indexes會儲存在disk
MS文件有寫每個記憶體中的索引,只存在於記憶體中,索引都不會儲存至disk,
當資料庫OnLine時,會重建記憶體索引,但看起來是一個很明顯的錯誤,
因為columnstore indexes只能建立在schema_and_data上,所以columnstore index會實體化至disk,
而這主要改善RTO時間,但我比較希望MS能改善restore DB with In-Memory的問題,
如果目標記憶體不足時,應該立即先拋出記憶體不足錯誤訊息,
而不是restore 到一半才拋出錯誤,因為我已經浪費等待restore時間了。
參考
[SQL Server]talk about clustered index again
Columnstore indexes - overview
Columnstore Indexes – part 108 (“Computed Columns”)
Include support for Calculated Columns on Columnstore Indexes
sys.dm_db_column_store_row_group_physical_stats
Columnstore indexes - what's new
[SQL SERVER]Clustered Columnstore Indexes 效能大耀進