SQL 2017開始提供Graph database,主要用來解釋複雜的多對多(M:N)關聯性,
好比社群複雜的階層資料,而且已經和TSQL(called MATCH())完全整合
Graph database是什麼
他是一個邊緣 (edges)和節點(nodes)的集合,並一起定義各種類型的關聯。
Node表示一個實體(如員工),Edge表示兩個實體之間的關聯性,
我們可以輕鬆查詢分析兩個實體之間資料關聯性、階層資料(如之前我介紹過的HierarchyID)處理或其他多對多複雜的關聯性,
架構如下圖
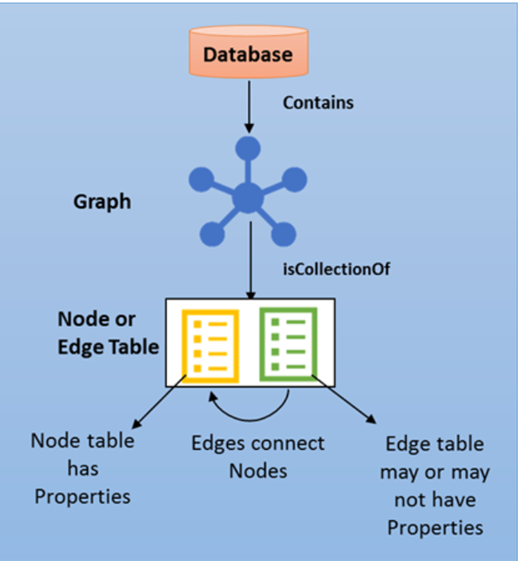 From Microsoft
From Microsoft
何時使用Graph database
面對現在使用者商業需求,我得老實說已經很難只有單一使用SQL Server通包的現象了(特殊查詢效能是主因),
像我自己就至少使用了四種非RDBMS協同輔助整個系統,
如 Influxdb(Time Series)、Redis(Key-Value)、Lucene(Document)和今天所介紹的Graph database。
當然,如果你只是單純又簡單的CRUD,系統成長量和併發量(規模)小,
你還是可以只透過傳統資料庫SQL Server完成各種需求。
我使用簡單員工資料表模型來進行簡單描述Graph
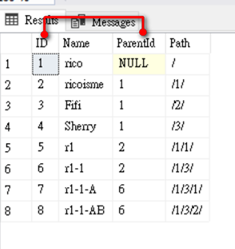
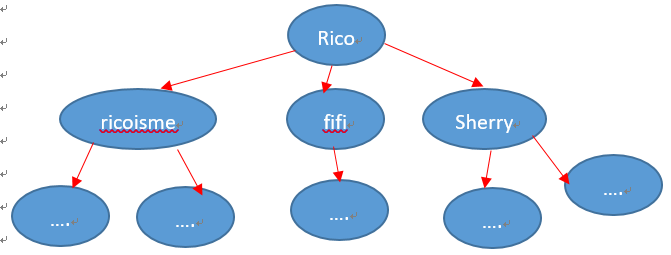
ParentID欄位和ID欄位有階層關聯,Graph簡單表示如下
開始使用Graph物件
--定義Node table
CREATE TABLE dbo.myEmployeeNode(
[ID] [int] NOT NULL,
[Name] [varchar](50) NOT NULL,
[ParentId] [int]
) AS NODE;
INSERT INTO myEmployeeNode([ID],[Name],[ParentId]) select [ID],[Name],[ParentId] from myEmployee
select * from myEmployeeNode
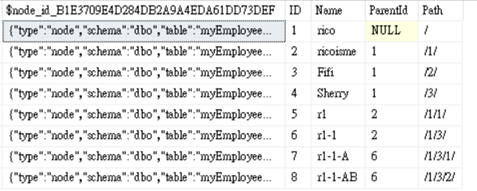 可以看到$node_id*使用json來儲存node table的metadata,另外,
可以看到$node_id*使用json來儲存node table的metadata,另外,
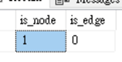
可以透過sys.tables來判斷該資料表什麼類型(node or edge)
SELECT is_node, is_edge FROM sys.tables
WHERE name = 'myEmployeeNode';
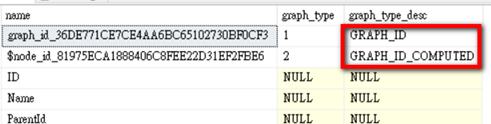
sys.columns也對欄位有所補充說明
SELECT name, graph_type, graph_type_desc
FROM sys.columns
WHERE object_id = OBJECT_ID('myEmployeeNode');
--定義Edge table
CREATE TABLE myEmployeeReportsTo(Path varchar(100)) AS EDGE
--使用ID和parentID定義關聯性
INSERT INTO myEmployeeReportsTo
SELECT e.$node_id, m.$node_id,e.Path
FROM dbo.myEmployeeNode e
inner JOIN dbo.myEmployeeNode m
ON e.[ID] = m.[ParentId];
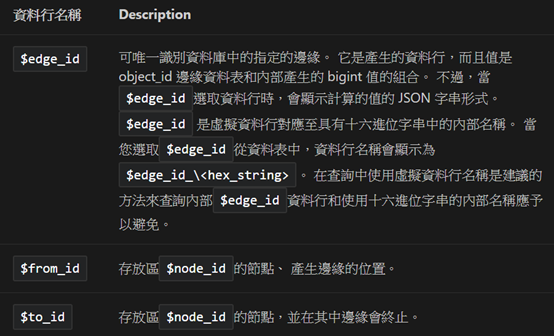
 Edge table預設有三個欄位,說明如下,我這裡還多了一個額外屬性path
Edge table預設有三個欄位,說明如下,我這裡還多了一個額外屬性path
 From Microsoft
From Microsoft
In SSMS
Call Match to Query graph properties
--查詢第一階層的資料,看誰要report 給rico和rico的老闆是誰
SELECT
E.[ID],E.[Name],E.[ParentId],E1.[ID],E1.[Name],E1.[ParentId]
FROM
myEmployeeNode e, myEmployeeNode e1, myEmployeeReportsTo m
WHERE
MATCH(e-(m)->e1)
and e.[Name]='rico'
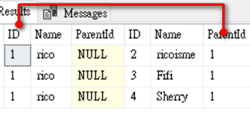 可以看到ParentID和ID的關聯性,並帶出相關階層資料
可以看到ParentID和ID的關聯性,並帶出相關階層資料
--查詢第二階層資料
SELECT
E.[ID],E.[Name],E.[ParentId],E1.[ID],E1.[Name],E1.[ParentId],E2.[ID],e2.[Name],E2.[ParentId]
FROM
myEmployeeNode e, myEmployeeNode e1, myEmployeeReportsTo m ,myEmployeeReportsTo m1, myEmployeeNode e2
WHERE
MATCH(e-(m)->e1-(m1)->e2)
and e.[Name]='rico'
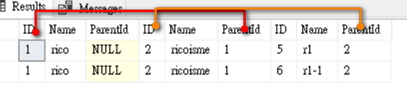
--查詢第三層資料
SELECT
E.[ID],E.[Name],E.[ParentId],E1.[ID],E1.[Name],E1.[ParentId],E2.[ID],e2.[Name],E2.[ParentId],E3.[ID],e3.[Name],E3.[ParentId]
FROM
myEmployeeNode e, myEmployeeNode e1, myEmployeeReportsTo m ,myEmployeeReportsTo m1, myEmployeeNode e2, myEmployeeReportsTo M2, myEmployeeNode e3
WHERE
MATCH(e-(m)->e1-(m1)->e2-(m2)->e3)
and e.[Name]='rico'
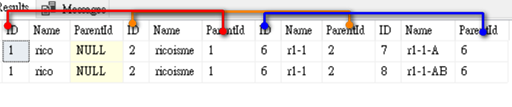
目前已知問題和相關限制

From Microsoft
這篇就先到這裡,後續我們繼續來瞧瞧Graph
參考
Graph processing with SQL Server and Azure SQL Database
Create a graph database and run some pattern matching queries using T-SQL
SQL Server Graph Databases – Part 1: Introduction
An introduction to a SQL Server 2017 graph database
How to integrate Power BI to the Facebook Graph API
Comparison of Relational Databases and Graph Databases
Graph extensions in Microsoft SQL Server 2017 and Azure SQL Database