有時候基於效能問題會使用Index View來提升查詢效能,但常常建立完成後SQL引擎卻不賞臉,死都不使用Index View的資料,硬是去掃Base Table。
我們先用下面Code來建立環境
--建立Database
Create Database [DB1];
GO
--建立Table
Use [DB1];
Drop Table If Exists tb1,tb2,tb3;
Create table tb1(tb1ID int Primary Key Clustered, t1Content Nvarchar(max));
Create table tb2(tb2ID int Primary Key Clustered, tb1ID int, t2Content Nvarchar(max));
Create table tb3(tb3ID int Primary Key Clustered, tb2ID int, t3Content Nvarchar(max));
GO
--寫入資料
Insert Into tb1 Values(1,N'日間部'),(2,N'進修部');
Insert Into tb2 Values(1,1,N'中文系'),(2,1,N'日文系'),(3,2,N'中文系'),(4,2,N'俄語系');
Insert Into tb3 Values
(1,1,N'史記'),(2,1,N'世說新語'),
(3,2,N'初階日文'),(4,2,N'進階日文123456'),
(5,3,N'孟子'),(6,3,N'中庸'),
(7,4,N'初階俄文'),(8,4,N'進階123456俄文');
GO完成環境建立後,我們建立一張Index View,如下面的Code
--建立Index View
CREATE VIEW dbo.vwTB
WITH SCHEMABINDING
AS
Select
tb1.tb1ID,
tb2.tb2ID,
tb3.tb3ID,
CONCAT(tb1.t1Content,tb2.t2Content,tb3.t3Content) AS txt
From dbo.tb1
Inner Join dbo.tb2 On tb1.tb1ID=tb2.tb1ID
Inner Join dbo.tb3 On tb2.tb2ID=tb3.tb2ID;
GO
--Create an index on the view.
CREATE UNIQUE CLUSTERED INDEX CIX_vwTB
ON dbo.vwTB (tb3ID);
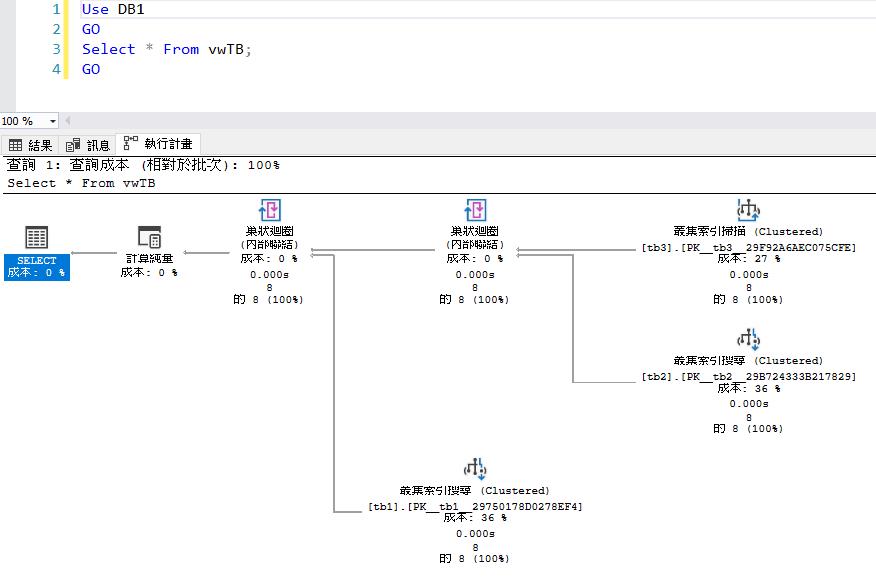
GO完成Index View建立後我們來Select該View,看看SQL會透過甚麼方式抓取資料。從下圖可以看見SQL是直接去3張Base Table抓資料,直接忽略Index View的資料。
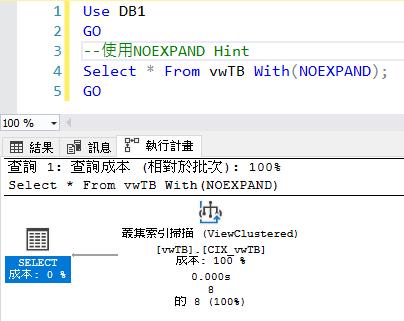
我們利用這次要介紹的Hint NOEXPAND 來從新執行一次搜尋,從下圖可以看見,SQL引擎直接掃描Index View的實體資料。
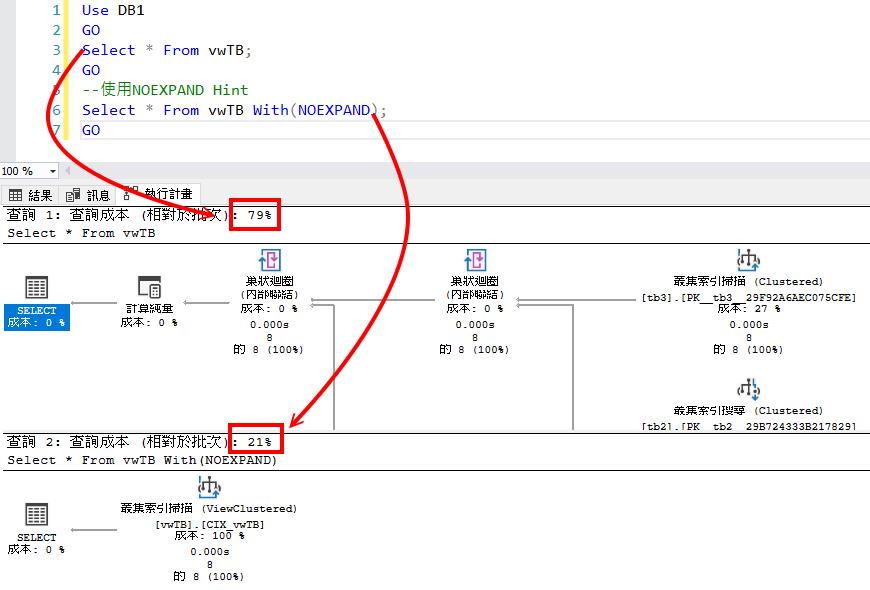
比對一下兩個查詢的執行計畫成本,如下圖我們可以看見使用 NOEXPAND 可是遠遠低於沒有使用。
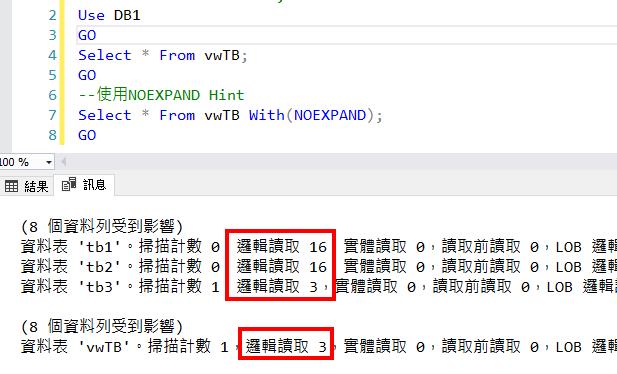
下圖的查詢IO數量也是直接抓Index View資料的IO成本較低。
雖然不知道SQL的最佳化查詢為何不吃Index View的資料,如果在你確認使用Index View可以取得較好效能的狀態下,你可以參考使用 NOEXPAND Hint。反之如果你要SQL直接抓Base Table的資料而不要考慮Index View資料的話則請使用 EXPAND VIEW Hint。
我是ROCK
rockchang@mails.fju.edu.tw


